![[レポート]得上竜一氏による『自前でLLMを作ってみたいけど、何をしたら良いのかさっぱりわからない人にむけた最初の一歩を伝える話』"run_clm.py is all you need." #cm_odyssey](https://devio2024-media.developers.io/image/upload/v1722870106/user-gen-eyecatch/goigj6mlu52bfwhxpluy.png)
[レポート]得上竜一氏による『自前でLLMを作ってみたいけど、何をしたら良いのかさっぱりわからない人にむけた最初の一歩を伝える話』"run_clm.py is all you need." #cm_odyssey

クラスメソッド設立20周年を記念し、オフラインイベント、オンラインイベントを複数日にわたって展開するイベント「Classmethod Odyssey」を2024年7月に開催されました。
当エントリでは、2024年07月11日(木)に開催された「Classmethod ODYSSEY 2024 ONLINE」における得上竜一氏によるセッション『自前でLLMを作ってみたいけど、何をしたら良いのかさっぱりわからない人にむけた最初の一歩を伝える話』の内容についてレポートします。
セッションの概要について
登壇者のセッション概要が仮だったため、セッションを聞いた感想を概要としてここにまとめます。
最近、大規模言語モデル(LLM)がどんどん流行ってきて、使うだけでは飽き足らず、自分でも作ってみたいなと思う方もいるかもしれません。しかし、いざ始めようとすると急にハードルが高くなると感じるでしょう。
このセッションを聞くと、一般のご家庭(逸般の誤家庭ではありません)でも、その最初の一歩を踏み出せるようになります。
より具体的には、Hugging FaceがGitHub上で公開している run_clm.py を利用し、私家版 LLMを作成します。
run_clm.py のプログラム冒頭では Fine-tuning the library models for causal language modeling (GPT, GPT-2, CTRL, ...) on a text file or a dataset. と紹介されています。
Large Language Model(大規模言語モデル)ならぬ Casual Language Model(一般のご家庭向け言語モデル)の作り方を得上さんから学びましょう。
最初の第一歩では不要だけれども、後々必要になる観点も紹介されています。
スピーカーの得上竜一さんについて
スピーカーの得上 竜一さんは株式会社ハンカチの代表取締役です。
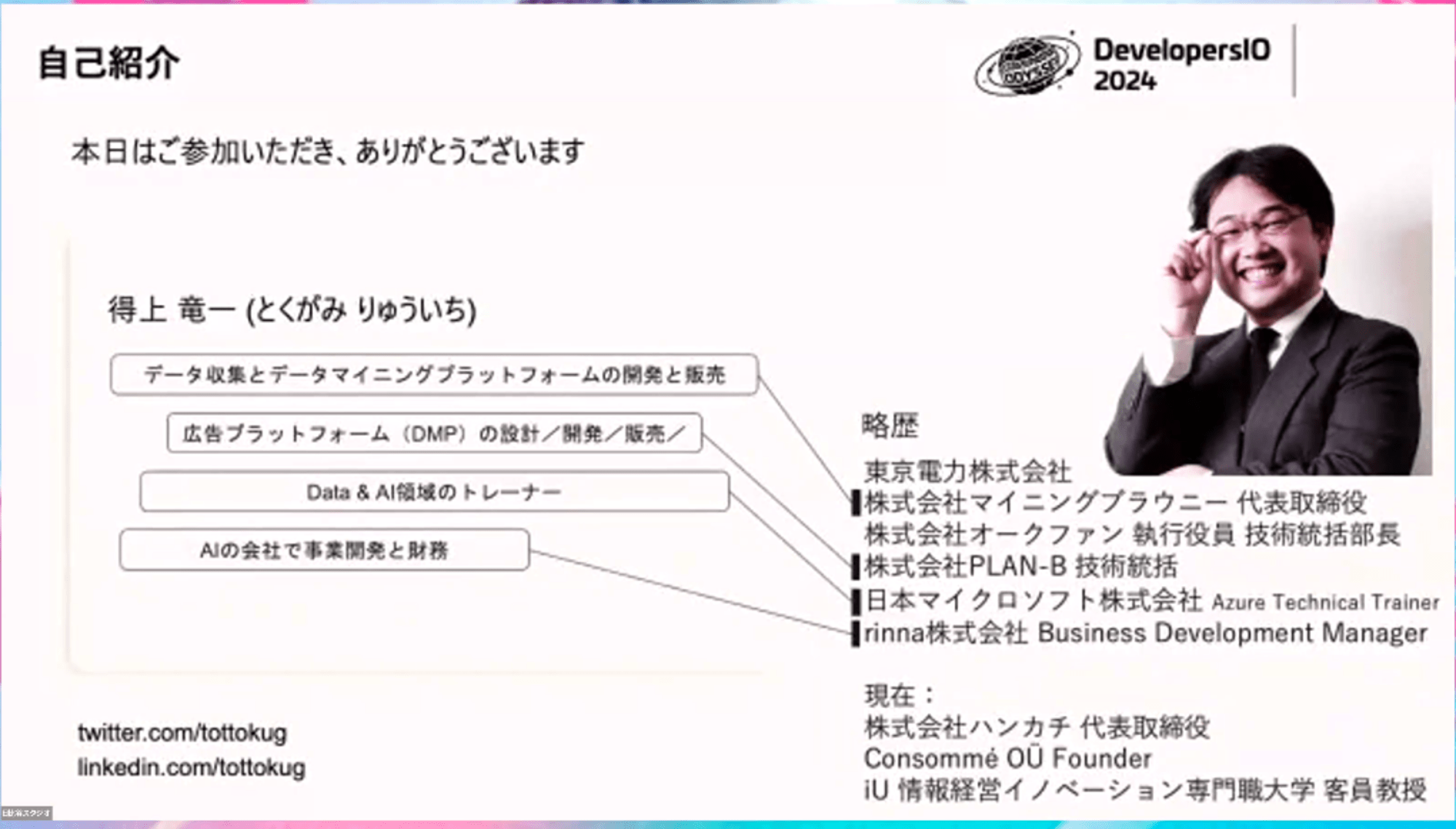
データ収集、広告のプラットフォーム、大手でデータやAI領域のトレーナー、AIの会社で事業開発や財務など、ずっとデータや機械学習やAIに関連するキャリアを歩まれています。
実は DevelopersIO のゲストブロガーとして2013年から11年で24本も書いていただいています。
LLMを作るとはどういうことなのか
LLMを作るにはデータセットの用意、トレーニング、精度検証という段階があります。

データを集めるには、自分でインターネットからクローリングすることもできますが、今回は最初の第一歩のため、すぐに使えるオープンデータセットを利用します。
トレーニングにもいくつかのアプローチがあります。
- 事前学習(pre-train):新規データを使って学習させる方法
- 継続事前学習(continuous pre-training):既存のモデルに追加で学習させる方法。追加学習
- 指示を与えて学習(instruction tuning)
- 精度を上げる手法(alignment)
今回は、事前学習と公開されているモデルに対して日本語で継続事前学習します。
今回はまずは作るところを目指すため、精度検証は割愛します。
データセット編
公開されている日本語のLLMは、Wikipedia、mC4、 CC-100、最近だと OSCAR、さらには、ウェブサイトのメインコンテンツに特化したThe Pile、RefinedWebといったデータセットがよく使われるようになっています。
クローリングの性質上、どうしても重複しているデータが存在するため、こうしたデータセットを使う時には、重複を取り除くような前処理をすると良いです。
機械学習界のGitHubというべきHugging Faceにはデータセットが公開されており、データを整備することなく、簡単に使えます。
from huggingface_hub import list_datasets
datasets = list_datasets(search="mC4 ja")
データセットはとても大事
最近の各社のいろいろなLLMはモデルのアーキテクチャーやレイヤー構造ではなく、LlaMa3-8Bのような良いモデルに対して、質の良いデータセットで継続事前学習して精度を上げることが主流になっているように見えます。
最近の精度のよいモデルは、自前で何かしらの良いデータセットを持っているところからリリースされており、良いデータセットが今の勝負所になっているように思われます。
最初の一歩ではないが、後々ちゃんとした精度のモデル出したり、独自のLLMを作るなら、自分たちで良いデータセットを持つことが大事です。
トレーニング編
データセット編の次はトレーニング編です。
今回は最初の一歩なので、逸般の誤家庭にしかないNVIDIA RTX/DGX はではなく、パソコンやColab(Colaboratory)などを使った一般のご家庭向けのトレーニング方法です。
今回紹介するトレーニングは 3種類あります。
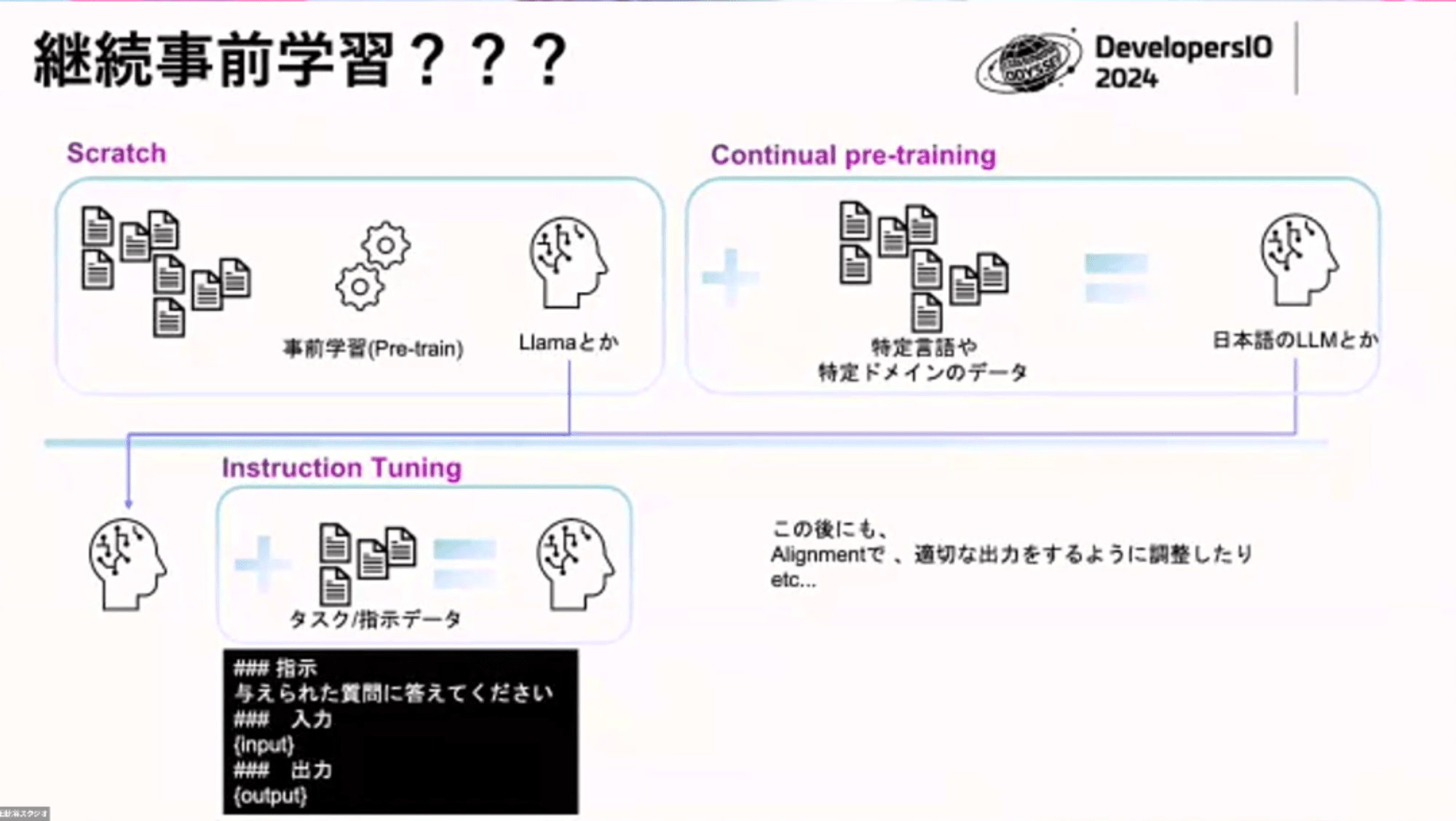
- スクラッチ(Scratch):
LlaMa(Meta)とかGPT(OpenAI)のように1からモデルを学習させていく方法です。
公開されているモデルと同じアーキテクチャ(レイヤーの構造)を使い、自分たちで一から学習させる方法もスクラッチです。
- Continual pre-traing(継続事前学習)
継続事前学習はLlambaのようなすでに学習済みのモデルに対して、特定のドメインのデータや特定の言語のデータを使って学習していく方法です
- Instruction Tuning
ある一定のフォーマットで学習させて、より精度が上げる方法です。
LLMの公開とともに、インストラクションが付属するものがこのケースです。
例) Instruction Tuningにより対話性能を向上させた3.6B日本語言語モデルを公開します
Instruction Tuningした後に、強化学習のアライメントを使って、人間が「これは良い回答だね」のような評価を与えながらチューニングする方法もあります。人間の倫理観と照らし合わせて「爆弾の作り方を教えない」といったチューニングすることもあります。
スクラッチLLM:新規で学習して小さいモデルを作る
まずここから初めてもらうのが良いです。
最近の 8Bやら 175Bと比べるとだいぶ小さい「orenoLLM-0.037B」のLLMをまず自前で作るところからやってみます。
学習データは著作権が切れた青空文庫を用います。
Wikipedia等に比べるとだいぶ小さいので、まず最初にやってみるには非常にいいデータセットです。
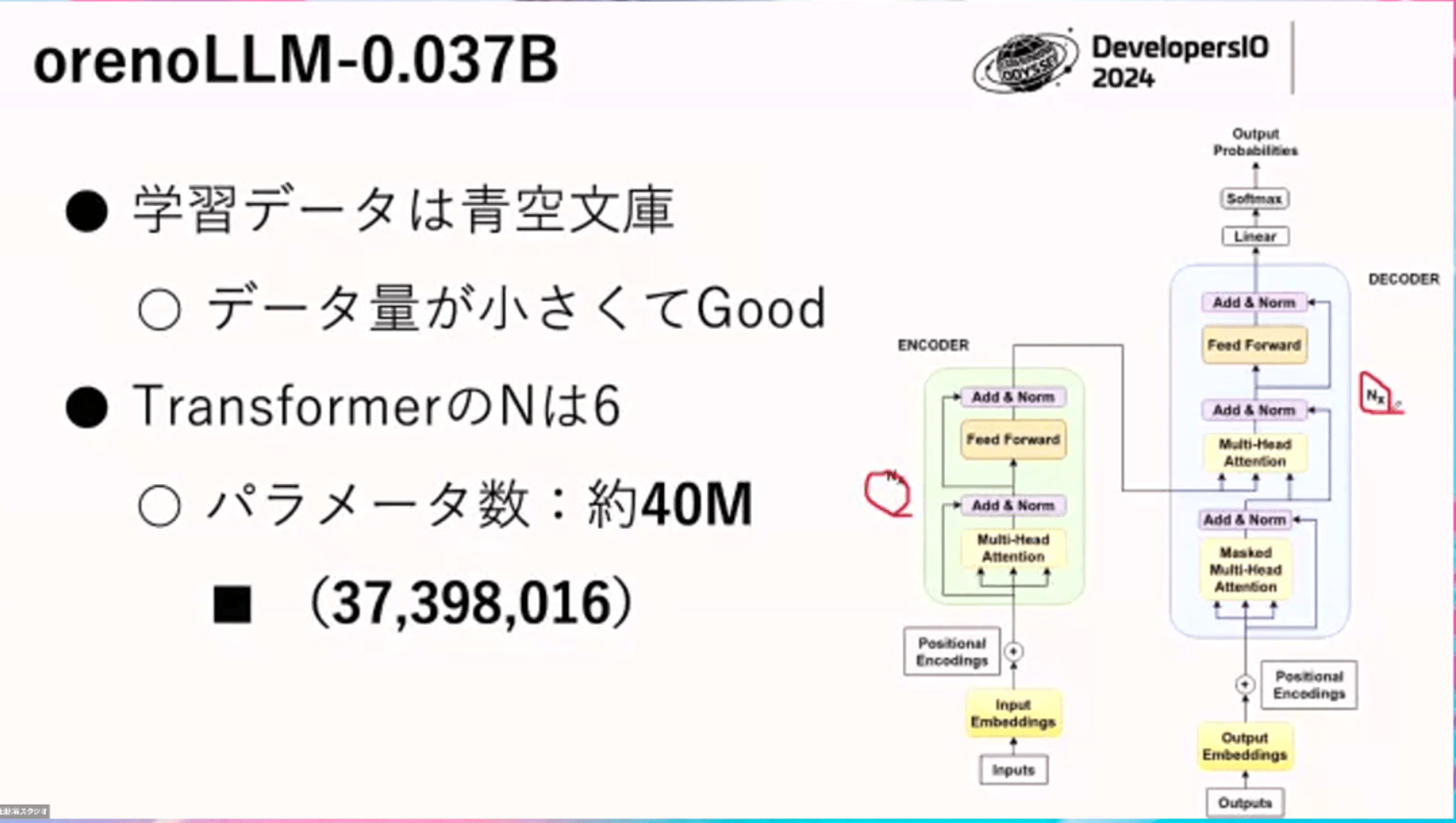
LLMはトランスフォーマーというアーキテクチャを多用しており、 赤枠の「N ×」 というところが増えれば増えるほど、パラメーター数はどんどん増えます。今回の N は 6 で、3700万=0.037 Billionです。
これを作る方法が主に 3 パターンあります。
- とてもつらい:PyTorchのようなディープラーニングのフレームワークを使って、自分で全部書く
- そこそこツライ:Hugging Faceが提供するPyTorchを使ったTransformers.Trainerクラスを利用
- 最初の第一歩: GitHubにあるHugging FaceのTransformersレポジトリにあるLLM界のスイス製アーミーナイフrunc_clm.py を利用
今回はこの3つ目の run_clm.py を利用します

わずか700行程度の runc_clm.py には約160個のオプションがあり、コマンド一つでLLMを作れます。
python ./transformers/examples/pytorch/language-modeling/run_clm.py \
--config_name rinna/japanese-gpt2-xsmall \ # モデルのレイヤー構造をコピーしてくれる
--tokenizer_name rinna/japanese-gpt2-xsmall \
--dataset_name globis-university/aozorabunko-clean \ # どのデータセットを使って学習させるか
--auto_find_batch_size \ # 動いている環境のメモリなどからバッチサイズを決定
--do_train \
--do_eval \
--num_train_epochs=3 \
--save_steps-5000 \
--save total_limit=3 \
--output_dir=orenoLLM-0.04B/
LlaMa3-8Bを日本語で継続事前学習
次にもうちょっと難易度を上げてLlaMa-3-8B を日本語で継続事前学習をやります。
このモデルを利用するには、アクセス申請が必要です。
LlaMaにはファインチューニングする公式のハウツーガイドやより具体的なレシピも存在しますが、最初の一歩ではありません。
1コマンドでやるために再び出てくるのが run_clm.pyです。
python/transformers/examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path_meta-llama/Meta-Llama-3-8B \ # どのモデルをベースに追加学習するのか?先ほどは config_name
--tokenizer_name meta-llama/Meta-Llama-3-8B \
--dataset_name izumi-lab/cc100-ja-filter-ja-normal \ #
--auto find batch size \
--do_train \
--do_eval \
--num_train_epochs-3 \
--save_steps-5000 \
--save_total_limit-3 \
--output_dir-Llama-3-8B-japanese/ # 学習済みのモデルが出力される
オプションはスクラッチとほぼ同じで、真似るモデルを指定する config_name オプションが、ベースモデルを指定する --model_name_or_path に変わった程度です
今日持って帰ってもらいたいこと2つ
run_clm.py を読み込め
run_clm.py は Hugging FaceのTransformersのサンプルですが、侮ってはいけなくて、最初の一歩でやりたいことの多くは、このコマンド一つでできます。
次の一歩をやりたくなったら、このスクリプトを読み込みましょう
トレーニングやデータセットなど、LLMを作る上で大事なことが学べます。
700行弱の多くはオプション定義なので、実装部分はそんなに多くありません。
データセットが大事
今後、自前のデータセットが非常に重要になってくる時代が来ると思うので、今のうちから、データセットを作り始めるとかしてもらうと良いのではないかなというと思います。
Q&A
Q:データセットを作成する際に気をつけること
クローリングの場合、HTMLタグやメインコンテンツじゃない部分のクレンジングが大事。
自前のデータセットの場合、学習させる前に、個人情報や機密情報を絶対にマスク・削除すること。
Q:自前のLLMを作成する辛い・辛くないの判断はどうする?
辛い・辛くないはコーディング量がポイントです。
自分たちで、レイヤー、トレーニングをラップしたHugging Face Trainer、run_clm.pyコマンドの使い方など、どれだけ低レベルなレイヤーまで覚えないといけないのかによる。
最近はレイヤーを意識する必要もなってきていて、データセットの勝負になり始めている。
次の一歩やビジネスを想定すると run_clm.py では力不足のため、 NVIDIA が出している少しつらい世界のライブラリ等も検討すること。
Q:業界ごとに整理されたオープンなデータセットはある?
業界ごとのデータセットないのが現状で、そもそもだしたがらない。
そのようなデータセットがあると、世界が変わる。
学習用のデータセットを提供し、利益の一部を受け取るNew York TimesとOpenAIのような関係が今後増えて気ており、今後も増えてくれると嬉しい。
Q:非エンジニアの場合、どこから始めれば良い?
手元のパソコンにPythonがなくてGPUもない非エンジニアがLLMを作る最初の一歩は、Google Colab にサインアップして開発してみると良い。
Pythonなどがインストールされた開発環境にウェブからアクセスできる。
Q:既存のLLMを利用せず、自作で作るべき理由は?
ビジネス観点では、1から作る選択肢がされることはほぼない。
あるとすれば、既存のレイヤー構造に対してさらに何らかの工夫を加えたいので、あれば1から作るのもありだが、ビジネス寄りもアカデミック領域にある気がしていて、LlaMa3のようなアーキテクチャーを理解した上で改善点がわかる人、あるいは、質の良いデータセットを持っているとアピールしたい場合など、かなり限定される
Q:instruction tuningをカスタマー系チャットボットに適用できるか?
できると思うが、カスタマーサポートでやろうとしたら、インストラクション・アライメントの後に、外部データを参照するRAGという手法がある。
RAGはチューニングコストが低いので、更に、モデル単体で精度をだしたいなら instruction tuningを試すのが良い。
Q:最近主流のファインチューニングの手法は?
どこのファインチューニングを指しているのかによる。
LoRA は現在もよく使われ、 LlaMaのファインチューイングのハウツーも、最初に LoRA の例が紹介されています。
いろんな手法を組み合わせたり、周辺のテクニックも登場しているので、そのあたりを確認してみるとよいのでは?
感想
初心者がLLMを独自に作成するとなると、全体像が見えず、大規模な計算機資源や難しい技術など、どこから手を付ければよいか、途方にくれてしまいます。
Hugging Faceが公開するLLM界のスイス製アーミーナイフrunc_clm.py を利用すると、データセットを用意するだけで独自のLLMを家のコンピューターからコマンドライン一発でカジュアルに作れます。
第一歩としては、Hugging Faceを利用すれば、出発点となるデータセットはいくらでも用意されているので、runc_clm.py と戯れてみましょう。
より本格的にLLMの作成と向き合おうとすると、質の良いデータセットが重要です。セッションの中でもQ&Aでも良いデータセットを持つこと、データ整備の重要性が何度も語られましたが、LLMを1から作成するケースは極めて稀になってきているため、差別化のために、良いデータセットを持つことの重要性がひしひしと伝わりました。
難しいことを難しく感じさせない話し方が素敵だと思いました。
とくがみさん、お忙しい中ご登壇いただき、ありがとうございました。
なお、一般人を対象したよりテクニカルなLLMの作り方としては、fukabori.fm #107 の ストックマーク株式会社の近江さんによる解説もあります。
107. LLMをゼロから作るということ w/ Takahiro Omi | fukabori.fm
参考まで。






