![[レポート]モダンデータスタックの歪 #SWTTokyo](https://images.ctfassets.net/ct0aopd36mqt/28u6B2aY5JSWLH2X4skKvz/25afbdd5c459fe539e8f0aff34fba358/eyecatch_snowflakeworldtourtokyo2024_1200x630.png)
[レポート]モダンデータスタックの歪 #SWTTokyo

さがらです。
2024年9月11日~2024年9月12日に、「SNOWFLAKE WORLD TOUR TOKYO」が開催されました。
本記事はセッション「モダンデータスタックの歪」のレポートブログとなります。
登壇者
- トヨタ自動車株式会社 データ利活用推進グループ リードデータエンジニア 川嶋 真希 氏
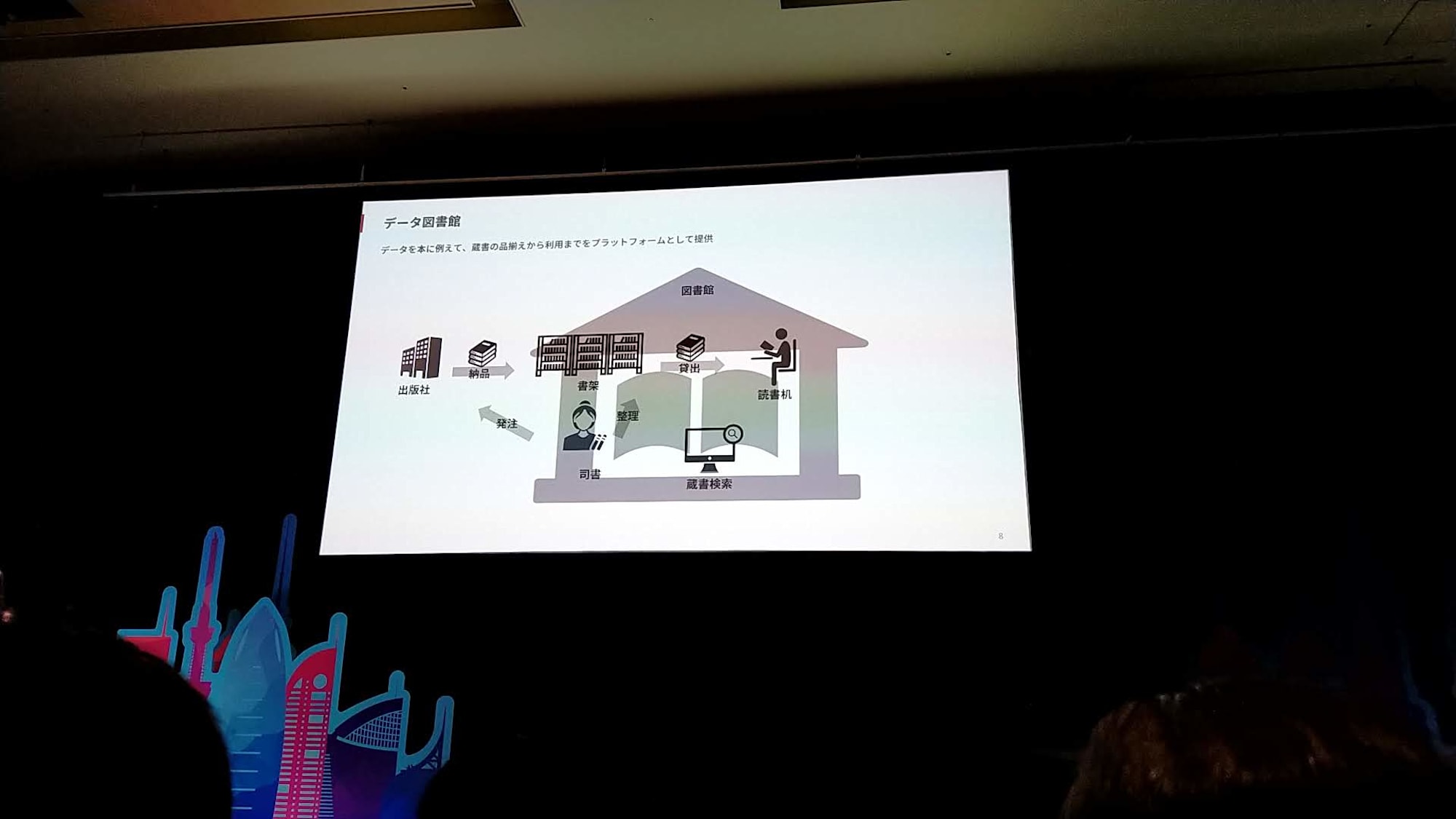
データ図書館:トヨタのデータ利活用基盤
- 背景
- デジタル化で自動車に関わる550万人が同じ方向を向いて仕事に打ち込める環境を作りたい
- データ図書館
- データを本に例えて、蔵書の品ぞろえから利用までをプラットフォームとして提供
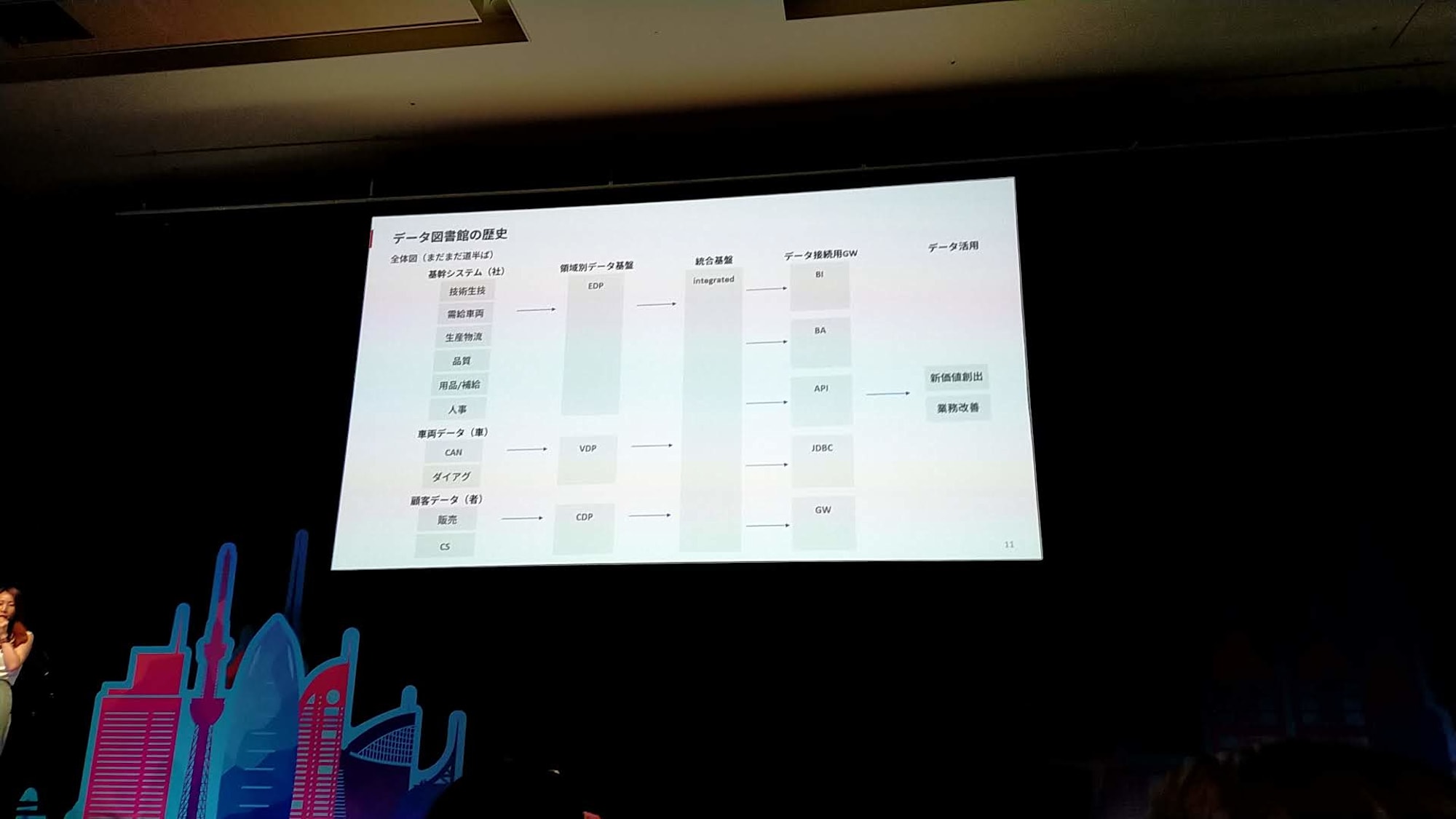
データ基盤の歴史
- 基幹システムを「社(やしろ)」と呼んでいる。これはEDPに集約
- 車両データは「車」と呼んでいる。これはVDPに集約
- 顧客データは「者」と呼んでいる。これはCDPに集約(これから開発予定)
- BI
- TableauとPowerBIを使用
- 今日は、社のEDPのアーキテクチャの話をする
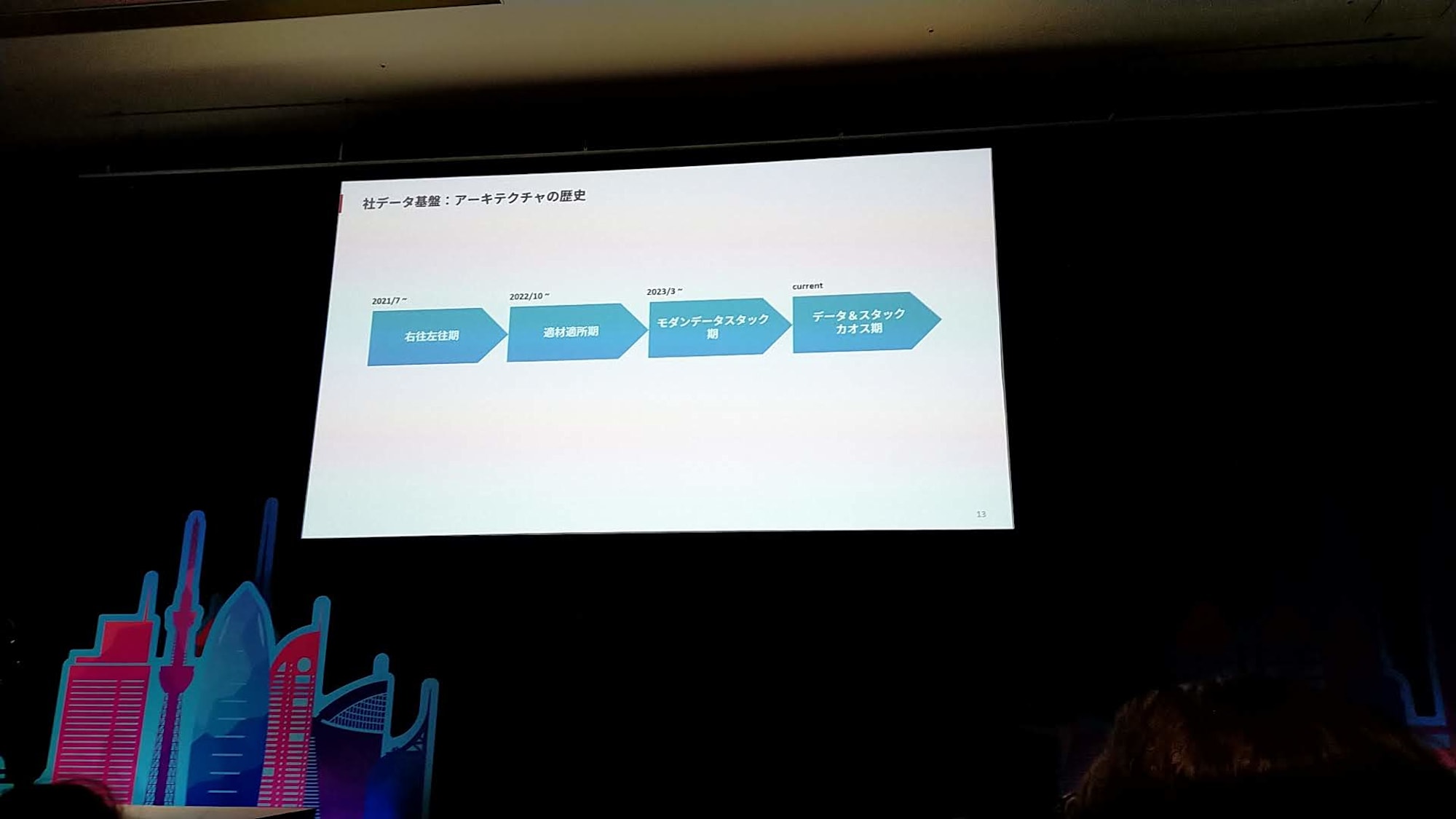
- アーキテクチャの変遷としては、大きく4つの期に分かれる
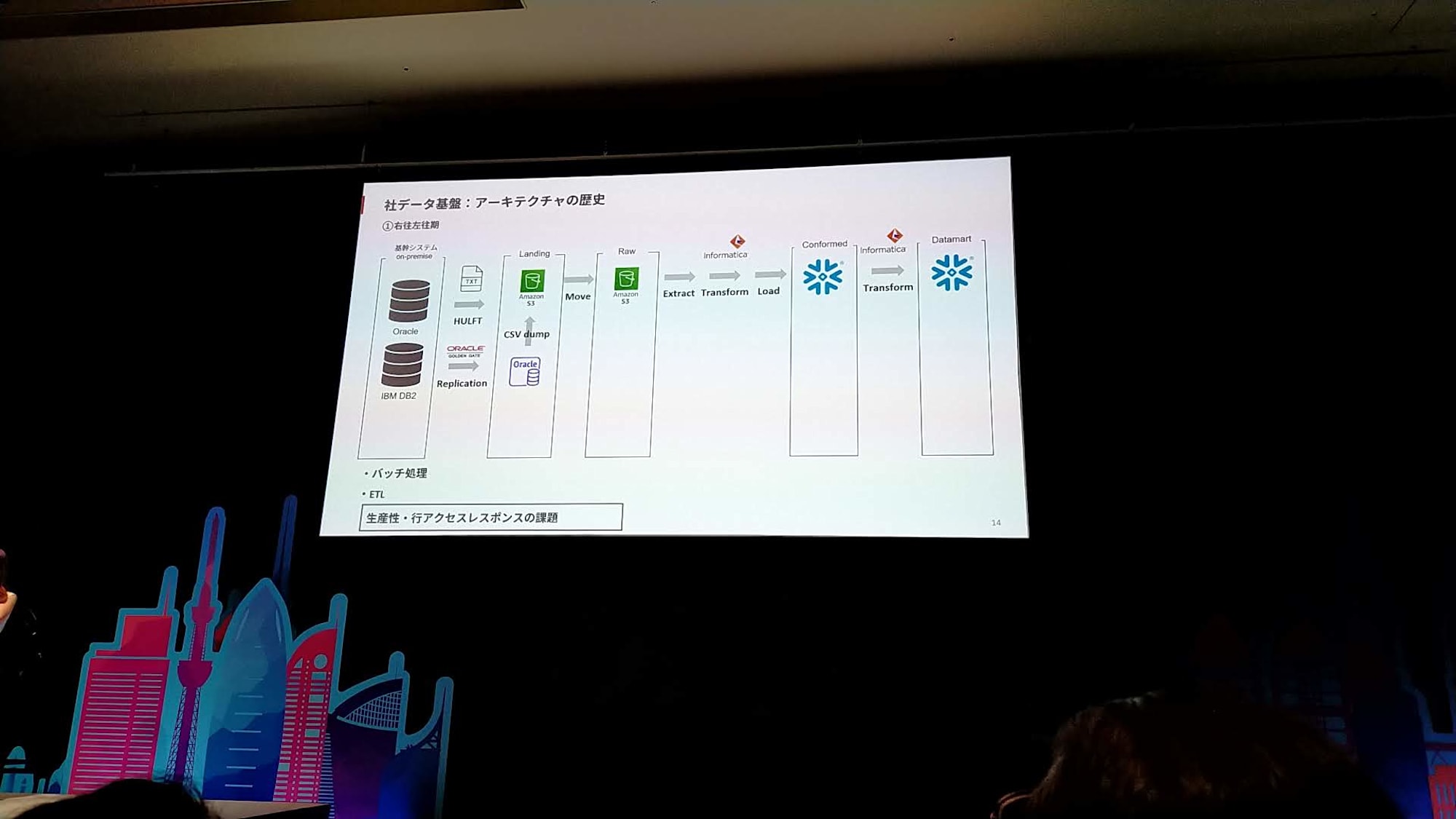
右往左往期
- S3に置いたデータを、InformaticaでETLしてSnowflakeへ
- データマートに変換するところも、Informaticaを使用
- すべてバッチ処理で動かしている
- 課題
- 開発生産性が良くなかった
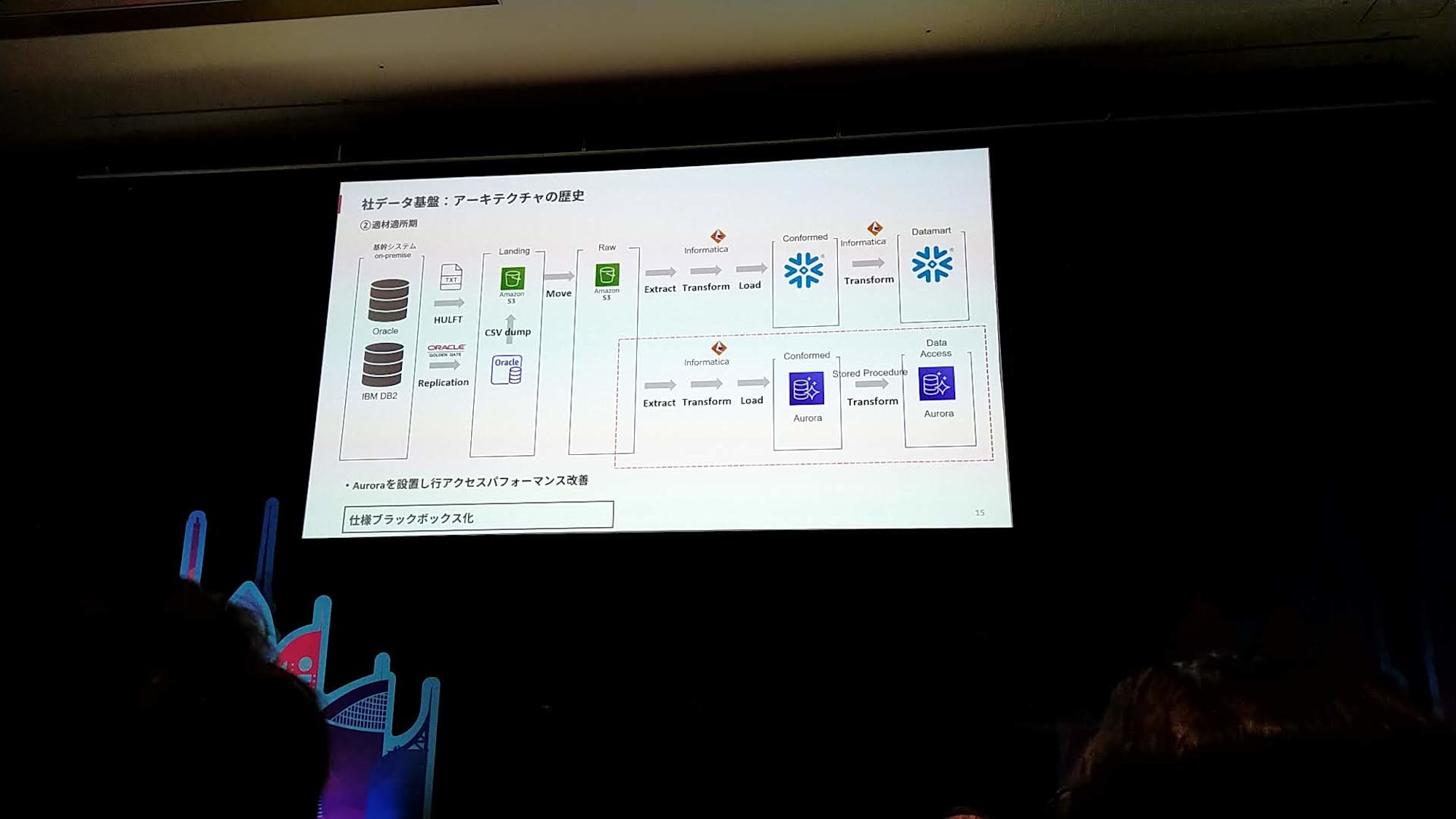
適材適所期
- 行アクセスパフォーマンスを改善するために、別途Auroraも導入
- 課題
- Auroraのストアドプロシージャの仕様が、ブラックボックス化
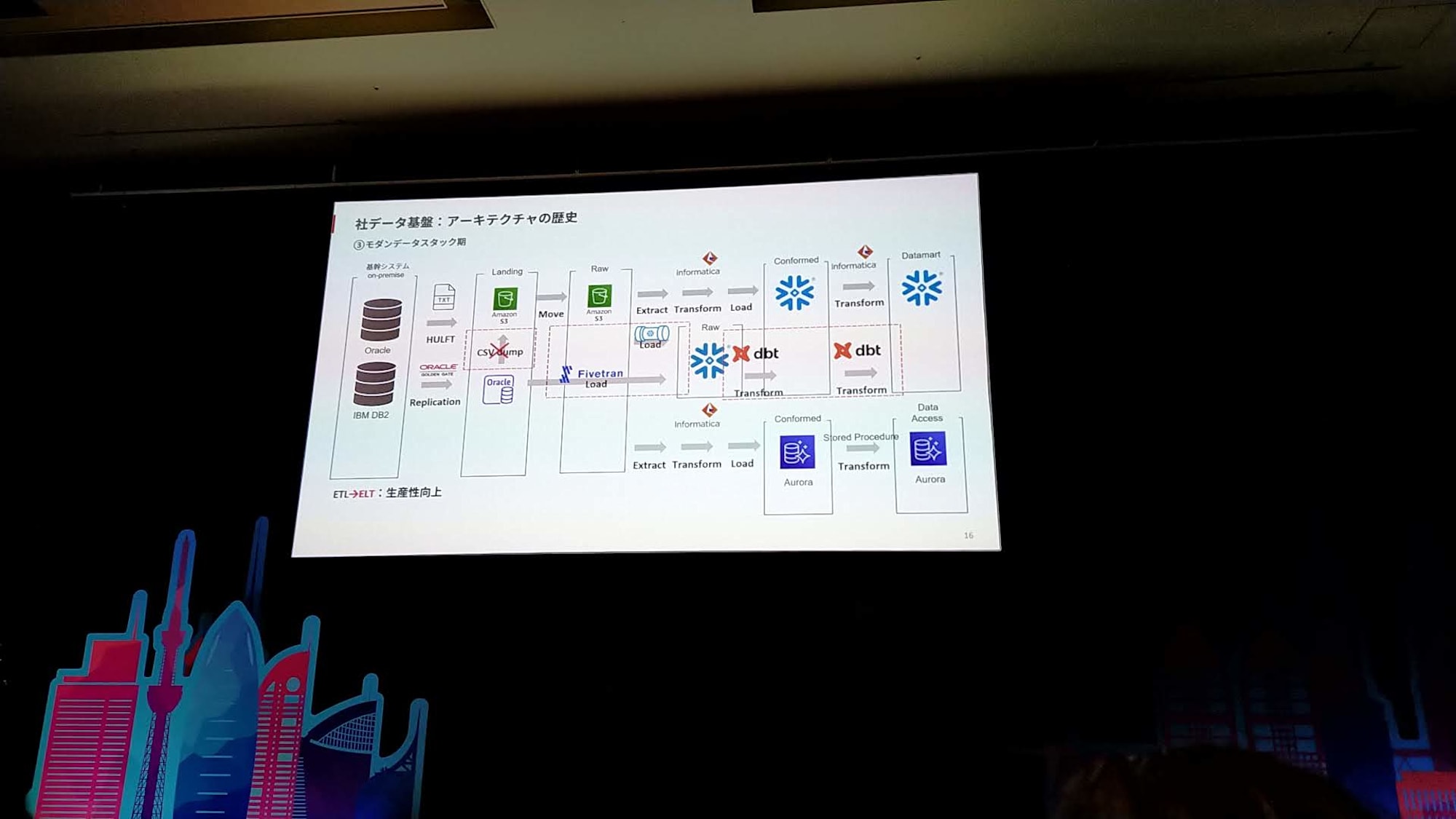
モダンデータスタック期
- ETL→ELTへの転換
- データをとりあえずSnowflakeにロードさせるように。Snowpipeを用いて実装
- また、Fivetranも用いてOracle RDSにレプリケーションされたデータをCDCでSnowflakeへ
- データ変換はdbt。SQLで開発できるため、これまで2か月などかかっていた処理が10日ほどで開発でき、リネージも可視化できるように
- 課題
- Informatic、Fivetran、Snowpipe、Aurora、多様なスタックで多箇所にデータが存在
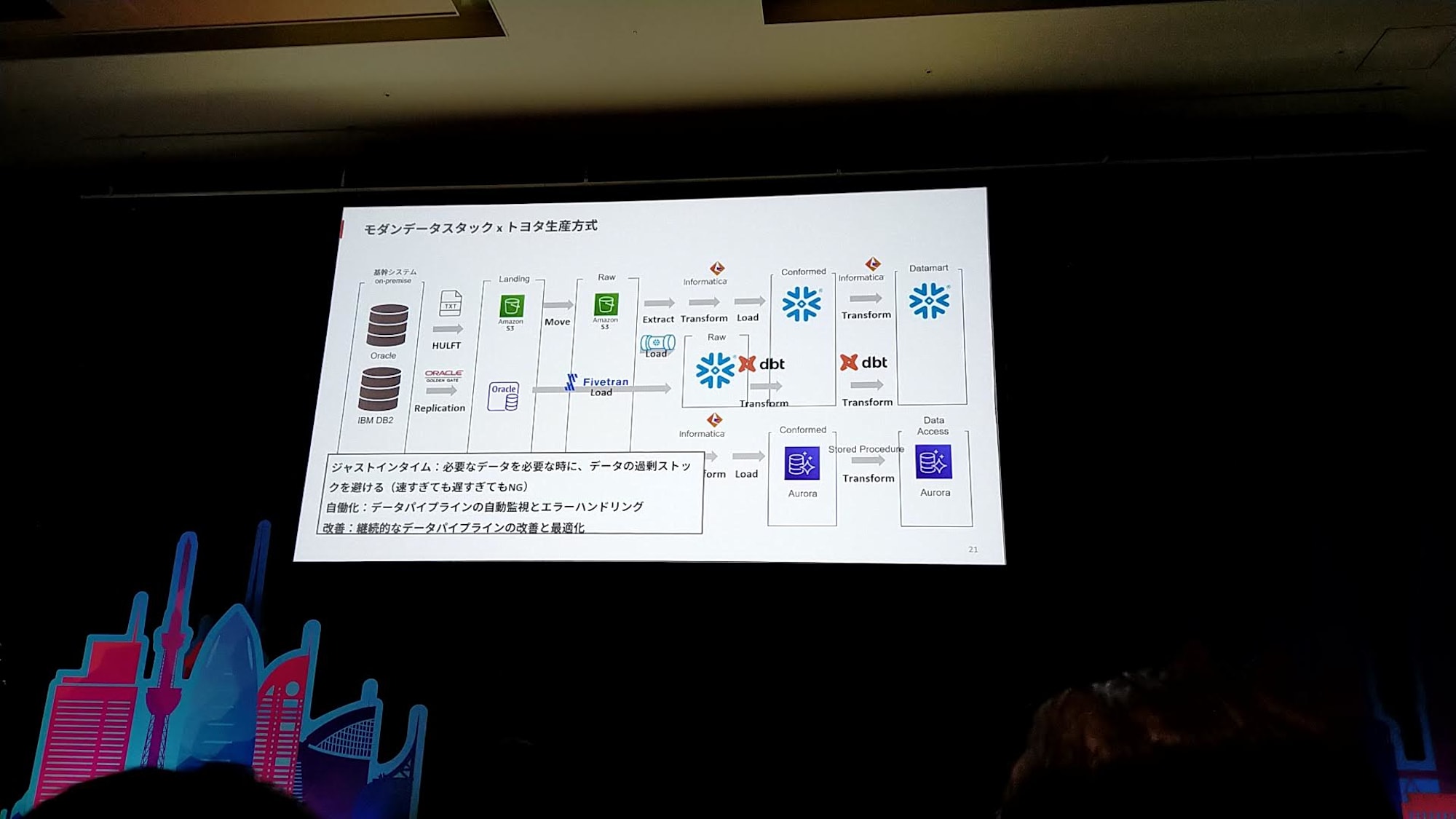
これまでの基盤の変遷をトヨタ生産方式で振り返る
- 出来ていない点
- ジャストインタイムでない
- 自動化できていない
- 改善(リファクタリング)もできていない
- 標準作業もできていない

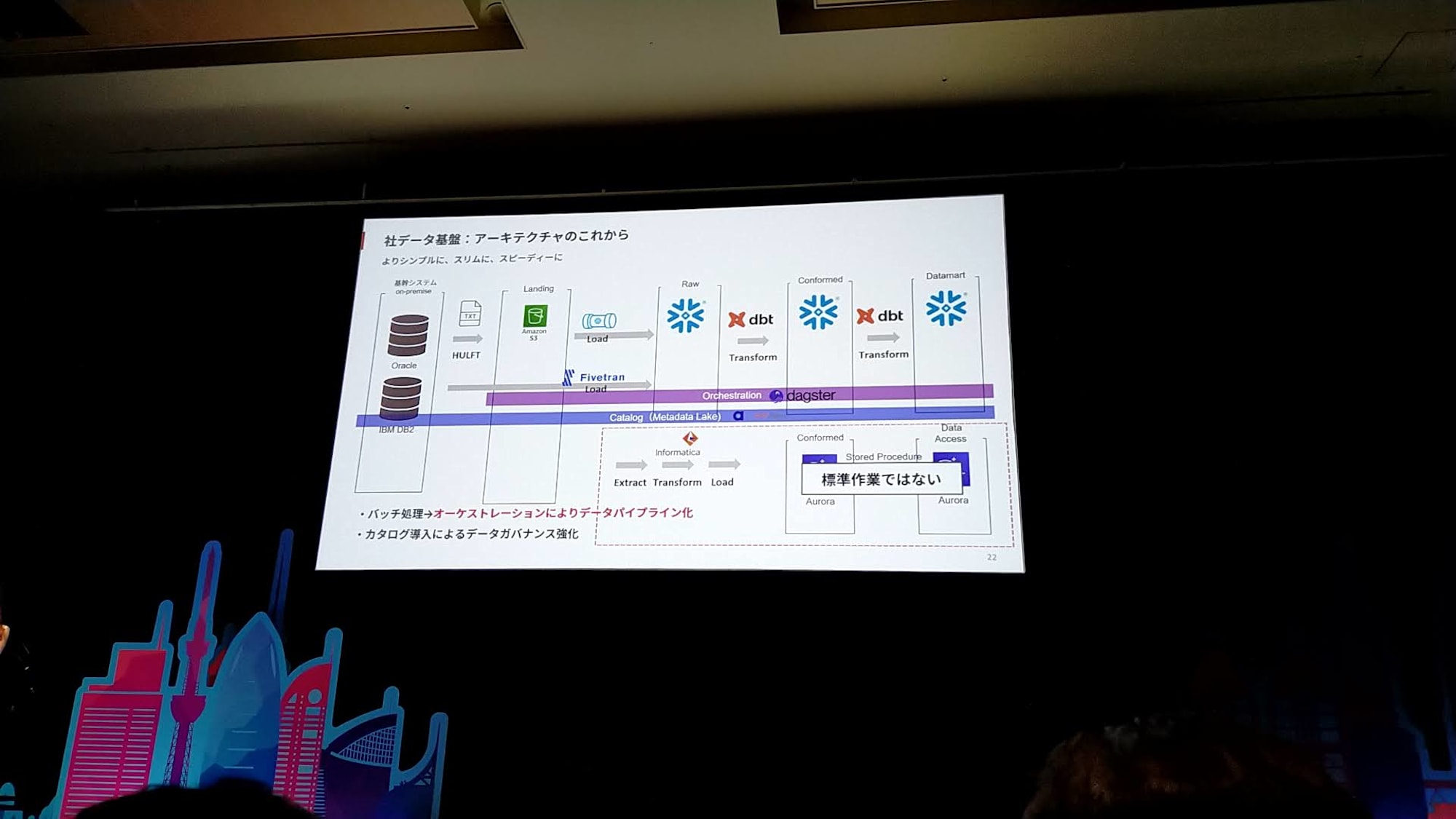
今後のデータアーキテクチャ
- オーケストレーションツールにDagsterを導入
- 異常を検知したら自動で停止するように
- これで「ジャストインタイム」と「自動化」を実現
- データカタログ
- AtlanかAlationを検証予定
- Aurora
- 先日パブリックプレビューとなったHybrid Tableを導入予定
- 次章で検証状況を紹介
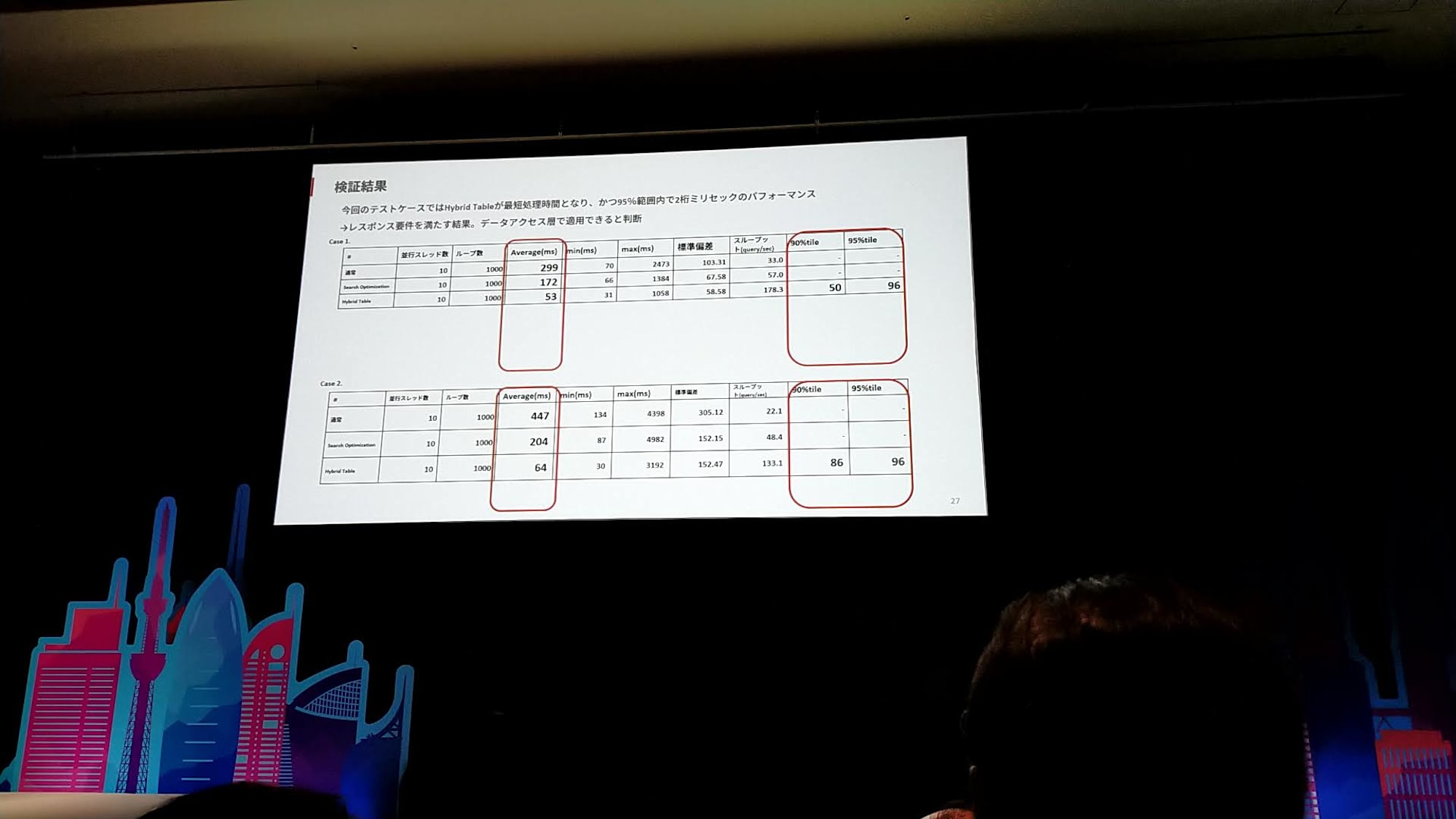
Auroraの処理をSnowflakeの各機能(Search Optimization、Hybrid Table)で検証
- Case1
- 車種に紐づく品番検索
- Case2
- 個車に紐づくメンテナンス履歴検索
- 検証結果
- Hybrid Tableを用いることで、データアクセス層でも導入可能なレスポンスを得られた


サマリ
- 一番伝えたいこと
- カイゼンが継続できるデータスタックであることが重要
- 標準化された作業であること
- このスライドが完成形である、データの流れを可視化して、最短リードタイムで開発できる基盤にしていきたい

最後に
トヨタ自動車社のデータスタックが、どのような変遷を経てきたかがよくわかるセッションでした。
このデータ基盤界隈の技術も変遷が激しいため、その時によって最適と考えるアーキテクチャは異なってくるのが非常に悩ましいですよね…と私も痛感するセッションでした。「シンプルに」「カイゼンが継続できる」という点は非常に大事だと思うので、私も改めて意識してアーキテクチャを考えていきたいですね。

