![[新機能]テキストを独自のカテゴリに自動分類できるCortex LLM Function「CLASSIFY_TEXT」がリリースされました](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-37f4322e7cca0bb66380be0a31ceace4/0886455fd66594d3e7d8947c9c7c844d/eyecatch_snowflake)
[新機能]テキストを独自のカテゴリに自動分類できるCortex LLM Function「CLASSIFY_TEXT」がリリースされました

さがらです。
現地時間2024年9月12日に、テキストを独自のカテゴリに自動分類できるCortex LLM Function「CLASSIFY_TEXT」がリリースされました。
早速試してみたので、本記事で内容をまとめてみます。
試してみた
本関数の公式ドキュメントを参考に、試していきます。
英語での分類
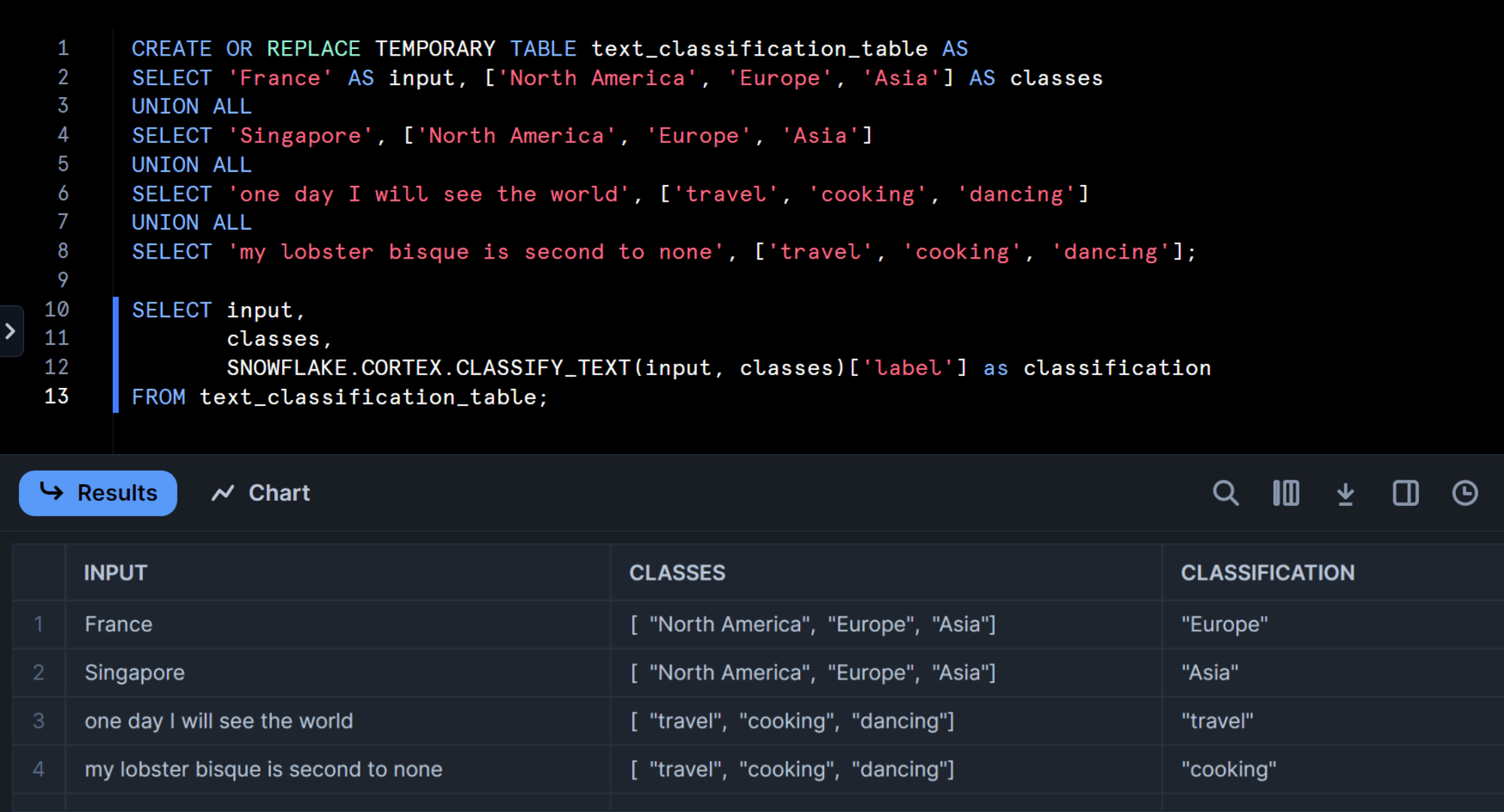
まずは公式ドキュメントに記載の下記のクエリを実行してみます。
CREATE OR REPLACE TEMPORARY TABLE text_classification_table AS
SELECT 'France' AS input, ['North America', 'Europe', 'Asia'] AS classes
UNION ALL
SELECT 'Singapore', ['North America', 'Europe', 'Asia']
UNION ALL
SELECT 'one day I will see the world', ['travel', 'cooking', 'dancing']
UNION ALL
SELECT 'my lobster bisque is second to none', ['travel', 'cooking', 'dancing'];
SELECT input,
classes,
SNOWFLAKE.CORTEX.CLASSIFY_TEXT(input, classes)['label'] as classification
FROM text_classification_table;
すると、国名からは適切に地域に分類し、英文からはどのようなことについて言及しているかも適切に分類されています。
日本語での分類:その1
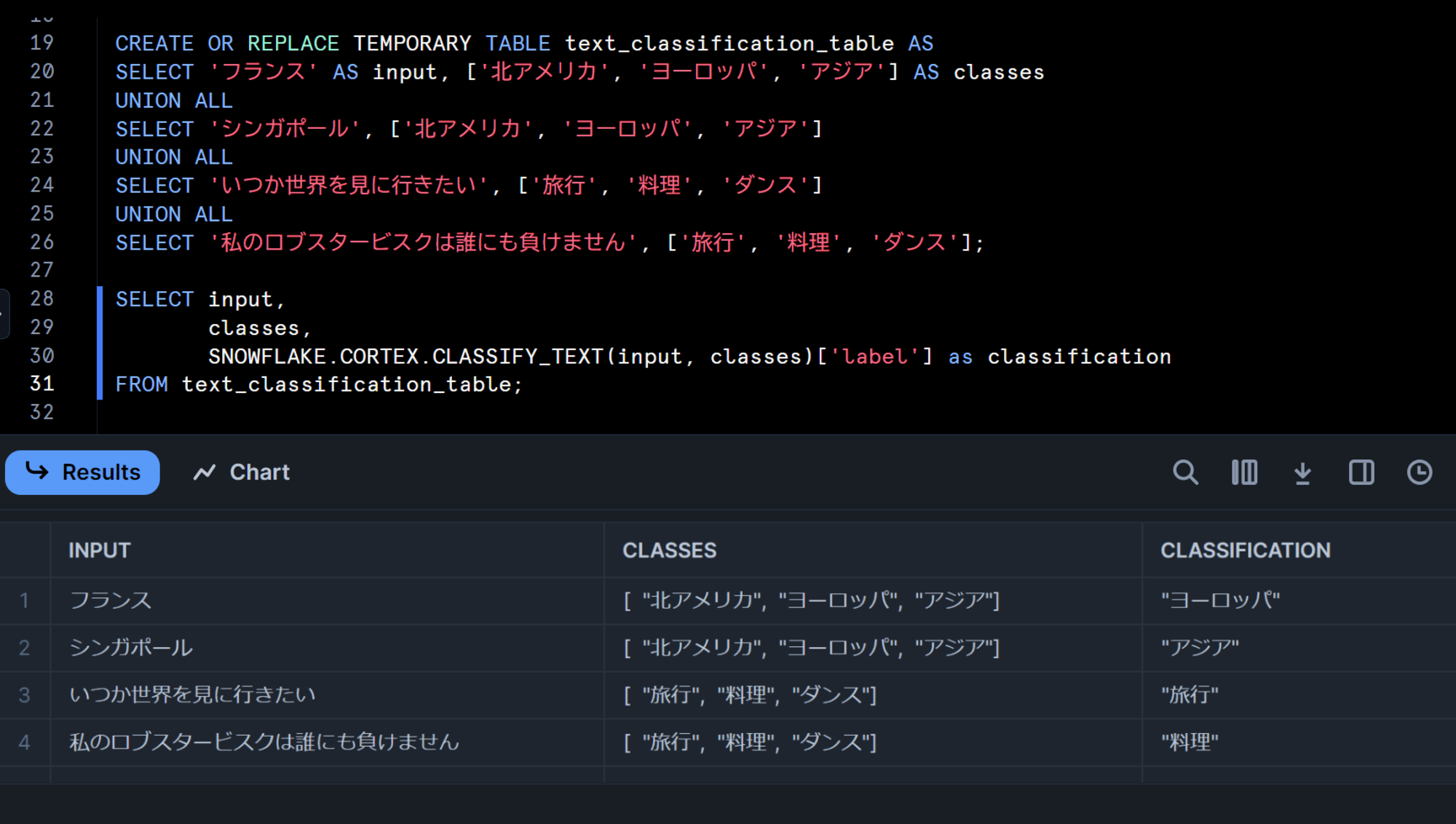
先ほど試したサンプルクエリの内容を、日本語化してやってみます。
CREATE OR REPLACE TEMPORARY TABLE text_classification_table AS
SELECT 'フランス' AS input, ['北アメリカ', 'ヨーロッパ', 'アジア'] AS classes
UNION ALL
SELECT 'シンガポール', ['北アメリカ', 'ヨーロッパ', 'アジア']
UNION ALL
SELECT 'いつか世界を見に行きたい', ['旅行', '料理', 'ダンス']
UNION ALL
SELECT '私のロブスタービスクは誰にも負けません', ['旅行', '料理', 'ダンス'];
SELECT input,
classes,
SNOWFLAKE.CORTEX.CLASSIFY_TEXT(input, classes)['label'] as classification
FROM text_classification_table;
すると、テキストもカテゴリも日本語でも問題なく分類することが出来ました!
日本語での分類:その2
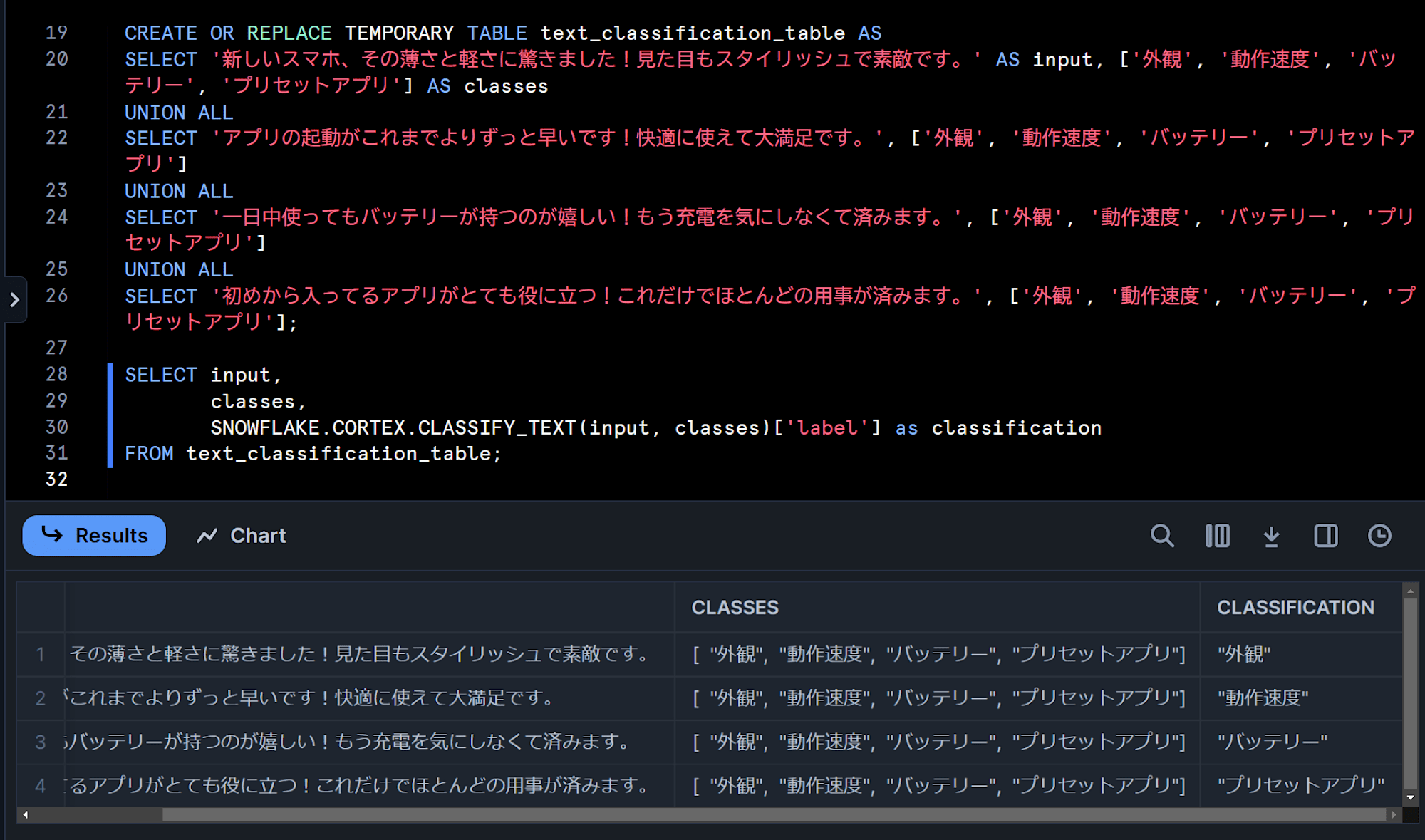
次は、より文章を長くして日本語で試してみます。
「ある新しいスマートフォンをリリースして寄せられたコメントが、製品のどの点に着目しているのかを分類したい」という状況をイメージしています。(例文はGPT-4に考えてもらいました。)
CREATE OR REPLACE TEMPORARY TABLE text_classification_table AS
SELECT '新しいスマホ、その薄さと軽さに驚きました!見た目もスタイリッシュで素敵です。' AS input, ['外観', '動作速度', 'バッテリー', 'プリセットアプリ'] AS classes
UNION ALL
SELECT 'アプリの起動がこれまでよりずっと早いです!快適に使えて大満足です。', ['外観', '動作速度', 'バッテリー', 'プリセットアプリ']
UNION ALL
SELECT '一日中使ってもバッテリーが持つのが嬉しい!もう充電を気にしなくて済みます。', ['外観', '動作速度', 'バッテリー', 'プリセットアプリ']
UNION ALL
SELECT '初めから入ってるアプリがとても役に立つ!これだけでほとんどの用事が済みます。', ['外観', '動作速度', 'バッテリー', 'プリセットアプリ'];
SELECT input,
classes,
SNOWFLAKE.CORTEX.CLASSIFY_TEXT(input, classes)['label'] as classification
FROM text_classification_table;
すると、下図のように適切に分類をしてくれました!
参考:CLASSIFY_TEXT関数のコスト
こちらのPDFからの引用ですが、ウェアハウスのコストとは別に「100万トークンあたり1.39クレジット」発生します。
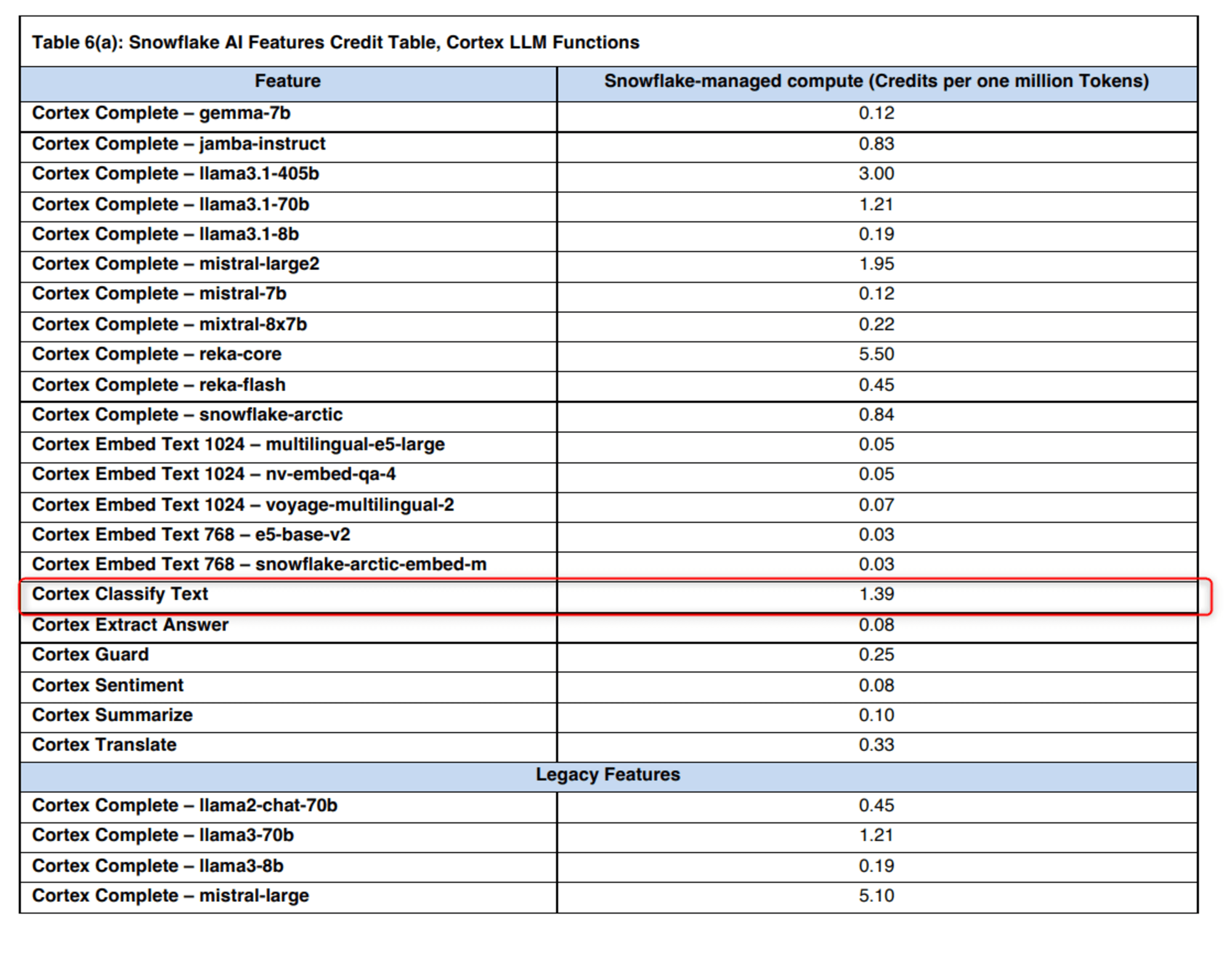
また、ドキュメントによると入出力どちらもカウントされるため、非常に長い文章を分類しようとすると課金が急に増える可能性があります。この点だけご注意ください。
For functions that generate new text in the response (COMPLETE, CLASSIFY_TEXT, SUMMARIZE, and TRANSLATE), both input and output tokens are counted.
最後に
テキストを独自のカテゴリに自動分類できるCortex LLM Function「CLASSIFY_TEXT」がリリースされたので、試してみました。
記事で検証した通り、日本語でも私が試した範囲では問題なく分類できましたので、かなり汎用性が高い関数ではないでしょうか!!コストに気をつけて、ぜひお試しください。


