
Snowflake Connector for PostgreSQL の構成手順をまとめてみる #SnowflakeDB

はじめに
2024年7月のアップデートで、Snowflake Connector for PostgreSQL/MySQL がプレビューとなりました。この内、Snowflake Connector for PostgreSQL(以下、コネクタとします)を試してみましたので、本記事ではコネクタによるデータロードを開始できるまでの手順をまとめます。コネクタ管理の詳細までは触れていないため、ご注意ください。
Snowflake Connector for PostgreSQL の概要
コネクタの概要や制限事項は以下に記載があります。
コネクタは Snowflake ネイティブアプリとしてマーケットプレイスから入手可能で、PostgreSQL から Snowflake にデータをロードできます。
主な特徴は以下です。詳細は上記のドキュメントをご参照ください。
- PostgreSQL バージョン11 以降で動作
- コネクタの構成には追加で PostgreSQL エージェント コンテナの構成が必要
- 顧客のネットワーク内にデプロイされ、ソースデータベースからデータの読み取りを行う
- デフォルトのレプリケーションモードは Continuous として動作し、頻繁に変更されるデータソースにはこのモードが使用できる
- スケジュールモードでレプリケートすることも可能
- 制限
- リードレプリカはサポートされていない
- レプリケーションに最大 200 個のソース テーブルを追加しても正常に動作するが、それ以上になると動作が不安定になる可能性がある
- 主キーのないテーブルはサポートされていない
検証環境
構成
コネクタを構成する際は、PostgreSQL エージェント コンテナの設定が必要です。ここでは簡単にプライベートサブネットに構築した EC2 に Docker をインストールしエージェントの設定を行いました(ECS や Kubernetes などは使用せずに、EC2 インスタンス上で Docker Compose を使って直接 Docker を起動しています)。
以下の構成です。
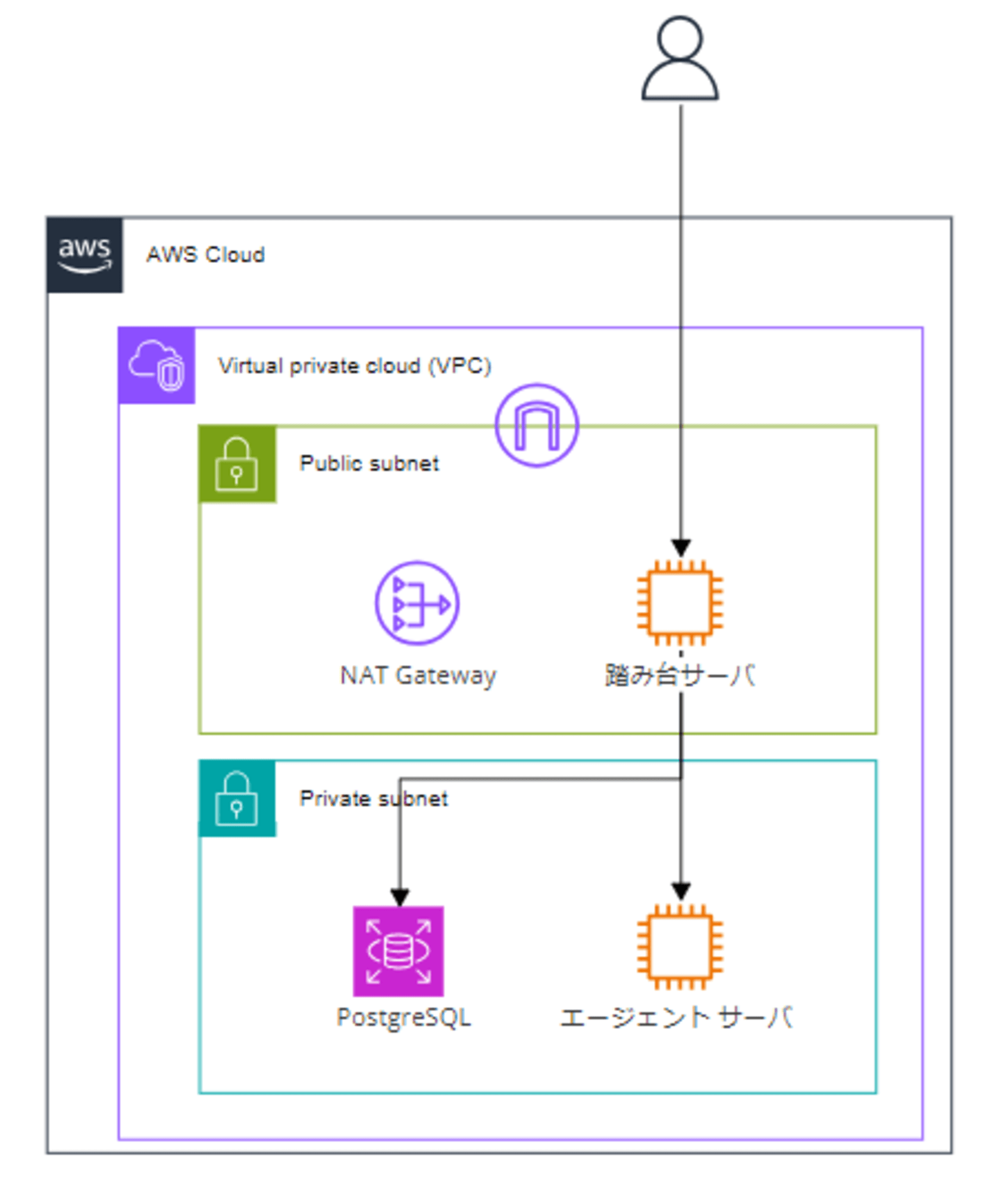
前提条件
その他は記載の条件で検証しています。踏み台サーバから PostgreSQL・エージェントサーバにログインし設定を行います。
- エージェントサーバ(PostgreSQL エージェント コンテナをホストするサーバ)
- OS:Amazon Linux 2023
- インスタンスタイプ:t2.xlarge(4vCPU, 16GB RAM)
- ボリューム
- ルートボリューム:8 GB
- Dockerストレージ:50 GB
- データソース
- Amazon RDS PostgreSQL:16.3-R2
- プライベートサブネットに構築
- インスタンスタイプ:db.t4g.micro
- Amazon RDS PostgreSQL:16.3-R2
事前準備:サンプルデータの作成
はじめに、踏み台サーバに psql をインストールしサンプルデータを作成しました。
-- データベースを作成
CREATE DATABASE sample_db;
\c sample_db;
-- テーブル1: customers
CREATE TABLE customers (
customer_id SERIAL PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100),
age INT
);
-- テーブル2: products
CREATE TABLE products (
product_id SERIAL PRIMARY KEY,
name VARCHAR(100),
price DECIMAL(10, 2)
);
-- テーブル3: orders
CREATE TABLE orders (
order_id SERIAL PRIMARY KEY,
customer_id INT REFERENCES customers(customer_id),
product_id INT REFERENCES products(product_id),
order_date DATE
);
-- customers テーブルにサンプルデータを挿入
INSERT INTO customers (name, email, age) VALUES
('Alice Smith', '[email protected]', 30),
('Bob Johnson', '[email protected]', 25),
('Charlie Brown', '[email protected]', 35);
-- products テーブルにサンプルデータを挿入
INSERT INTO products (name, price) VALUES
('Laptop', 999.99),
('Smartphone', 499.99),
('Tablet', 299.99);
-- orders テーブルにサンプルデータを挿入
INSERT INTO orders (customer_id, product_id, order_date) VALUES
(1, 1, '2023-10-01'),
(2, 2, '2023-10-02'),
(3, 3, '2023-10-03');
Docker のインストール
エージェントサーバでは、追加ボリュームの設定と Docker のインストールを実施しておきます。
追加ボリュームのマウント
はじめに Docker のインストール用にボリュームのマウントを行いました。
sudo mkfs -t xfs /dev/xvdb
ボリュームのマウントポイントの作成とマウント
# Dockerストレージ用
sudo mkdir -p /var/lib/docker
sudo mount /dev/xvdb /var/lib/docker
再起動後も永続的にボリュームがマウントされるように/etc/fstab ファイルを編集します。
以下のコマンドで/etc/fstabに書き込むための UUID を確認します。
$ sudo blkid
/dev/xvda128: SEC_TYPE="msdos" UUID="A41B-D0D1" BLOCK_SIZE="512" TYPE="vfat" PARTLABEL="EFI System Partition" PARTUUID="dc8e83c2-fd31-4403-960e-484e567be164"
/dev/xvda127: PARTLABEL="BIOS Boot Partition" PARTUUID="d0854c70-9a2b-4635-a6ce-267dedbe5605"
/dev/xvda1: LABEL="/" UUID="693eea79-11af-44b1-9c1e-01aced209966" BLOCK_SIZE="4096" TYPE="xfs" PARTLABEL="Linux" PARTUUID="8eca1f17-8f97-4b7d-9b31-ba295f584293"
/dev/xvdb: UUID="3171ca58-2dd8-4626-9f10-33dc0a298ce6" BLOCK_SIZE="512" TYPE="xfs"
/etc/fstabを開いて追加ボリュームの情報を追記します。
sudo vi /etc/fstab
以下の内容を追記しました。
UUID=3171ca58-2dd8-4626-9f10-33dc0a298ce6 /var/lib/docker xfs defaults,nofail 0 2
マウントの確認
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
xvda 202:0 0 8G 0 disk
tqxvda1 202:1 0 8G 0 part /
tqxvda127 259:0 0 1M 0 part
mqxvda128 259:1 0 10M 0 part /boot/efi
xvdb 202:16 0 50G 0 disk /var/lib/docker
$ df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs 7.9G 0 7.9G 0% /dev/shm
tmpfs 3.2G 456K 3.2G 1% /run
/dev/xvda1 8.0G 1.6G 6.4G 20% /
tmpfs 7.9G 0 7.9G 0% /tmp
/dev/xvda128 10M 1.3M 8.7M 13% /boot/efi
tmpfs 1.6G 0 1.6G 0% /run/user/1000
/dev/xvdb 50G 389M 50G 1% /var/lib/docker
Docker と Docker Compose のインストール
以下のコマンドで Docker と Docker Compose をインストールしました。
sudo dnf update
# dockerのインストール
sudo dnf install -y docker
# dockerの開始
sudo systemctl start docker
# システムの起動時に Docker も自動的に起動するように設定
sudo systemctl enable docker
# sudoなしでdockerを実行できるようにする
sudo usermod -aG docker $USER
# dockerのソケットファイルの所有グループをdockerに変更
sudo chgrp docker /var/run/docker.sock
# dockerデーモンを再起動
sudo service docker restart
# docker compose をインストール
sudo curl -L "https://github.com/docker/compose/releases/download/v2.29.7/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
Docker Compose のインストール | Docker docs
バージョンを確認
$ docker -v
Docker version 25.0.5, build 5dc9bcc
$ docker-compose -v
Docker Compose version v2.29.7
ここまでで事前準備が完了です。
PostgreSQL の構成
コネクタの構成にあたり PostgreSQL 側で事前に以下の作業が必要です。
- wal_level の設定
- パブリケーションの構成
- エージェントからの接続に使用するユーザーを作成
手順は以下に記載があるので、こちらに沿って進めます。
wal_level の設定
ここでは Amazon RDS を使用しているのでパラメータグループのrds.logical_replicationを 1 に設定します。
> SHOW rds.logical_replication;
rds.logical_replication
-------------------------
on
(1 row)
パブリケーションの構成
パブリケーションはデータベース単位で機能するため、CREATE データベースの権限を持つユーザーで対象のデータベースにログインし、以下を実行します。
\c sample_db;
CREATE PUBLICATION mypublication;
続けて Snowflake Connector for PostgreSQL エージェントが参照できるテーブルを以下の通り定義します。
ALTER PUBLICATION mypublication ADD TABLE customers;
ALTER PUBLICATION mypublication ADD TABLE products;
ALTER PUBLICATION mypublication ADD TABLE orders;
エージェントからの接続に使用するユーザーを作成
Amazon RDS の場合ユーザーにはrds_superuserおよびrds_replicationロールが割り当てられている必要があります。ここでは以下の内容でユーザーを作成しました。
-- ユーザーを作成
CREATE USER sf_connector_user WITH PASSWORD '<パスワード>';
-- rds_superuserロールを割り当てる
GRANT rds_superuser TO sf_connector_user;
-- rds_replicationロールを割り当てる
GRANT rds_replication TO sf_connector_user;
--確認
> \du sf_connector_user;
List of roles
Role name | Attributes | Member of
-------------------+------------+---------------------------------
sf_connector_user | | {rds_superuser,rds_replication}
PostgreSQLエージェントコンテナの設定
ここからエージェントコンテナの構成を行います。コンテナの構成については以下に記載があります。
要件
構成時の前提条件として、サーバマシンには以下の要件があります。
- システム要件
- 正常に動作するには最低 6 GB の RAM が必要
- 最適な CPU 数は 4
- ネットワーク要件
- エージェントは、ソース データベースに接続できる必要がある
- エージェントは、Snowflake に直接接続する
- 接続に必要な Snowflake ホスト名の詳細は、「ホスト名の許可」をご参照ください
- 通信時はエージェントから Snowflake ホストに対してアウトバウンド通信が行われるため、インバウンド通信用にポートの開放は必要ありません
上記より、ここではセキュリティグループのインバウンドルールとして、以下の設定としました。
- エージェントサーバ
| ポート範囲 | タイプ | ソース |
|---|---|---|
| 22 | SSH | 踏み台サーバのセキュリティグループ |
- Amazon RDS for PostgreSQL
| ポート範囲 | タイプ | ソース |
|---|---|---|
| 5432 | PostgreSQL | 踏み台サーバのセキュリティグループ |
| 5432 | PostgreSQL | エージェントサーバのセキュリティグループ |
agent-postgresql フォルダを作成
エージェントサーバにログインし、構成に必要なフォルダを作成します。
mkdir -p snowflake-connector-postgres/{agent-keys,configuration}
この時点で以下のフォルダ構成です。
.
`-- snowflake-connector-postgres
|-- agent-keys
`-- configuration
設定ファイルの作成
エージェントコンテナの構成には、以下の設定ファイルが必要です。
snowflake.json- Snowflake への接続情報を持つ
- 後述する手順で Snowflake 側で生成される
datasources.json- ソース データベースへの接続情報を持つ
datasources.json自分で用意する必要があるので、以下の内容で作成し configuration ディレクトリに配置しました。
{
"PSQLDS1": {
"url": "jdbc:postgresql://<RDSのエンドポイント>:5432/postgres",
"username": "sf_connector_user",
"password": "<パスワード>",
"publication": "mypublication",
"ssl": false
}
}
postgresql.conf- 追加のエージェント環境変数を含む
こちらはドキュメントの内容に従い、以下の内容で作成しconfiguration ディレクトリに配置しました。
JAVA_OPTS=-Xmx5g
docker-compose.yml
プロジェクトのルートに以下の内容で作成しました。
version: '1'
services:
postgresql-agent:
container_name: postgresql-agent
image: snowflakedb/database-connector-agent:latest
volumes:
- ./agent-keys:/home/agent/.ssh
- ./configuration/snowflake.json:/home/agent/snowflake.json
- ./configuration/datasources.json:/home/agent/datasources.json
env_file:
- configuration/postgresql.conf
mem_limit: 6g
参考:Configure the Agents | Working with the MySQL and PostgreSQL connectors for Snowflake
この時点で以下のディレクトリ構成です。
.
`-- snowflake-connector-postgres
|-- agent-keys
|-- configuration
| |-- datasources.json
| `-- postgresql.conf
`-- docker-compose.yml
Snowflake 側での作業
上記の設定まで完了後、Snowflake アカウントで作業を行います。こちらの手順は以下に記載があります。
コネクタのログ記録の構成
コネクタのイベントログを保存するためにイベント テーブルが必要となります。ここでは以下のコマンドでテーブルを作成し、アカウントに対して設定しました。
USE ROLE SYSADMIN;
--イベントテーブル格納先のデータベース・スキーマを作成
CREATE DATABASE event_db;
CREATE SCHEMA event_schema;
--イベントテーブルを作成
CREATE EVENT TABLE IF NOT EXISTS event_db.event_schema.my_event_table CHANGE_TRACKING = TRUE;
--アカウントにイベントテーブルを設定
USE ROLE ACCOUNTADMIN;
ALTER ACCOUNT SET EVENT_TABLE = event_db.event_schema.my_event_table;
PostgreSQL 用 Snowflake コネクタのインストール
ACCOUNTADMIN で Marketplace を操作し「Snowflake Connector for PostgreSQL」を検索します。
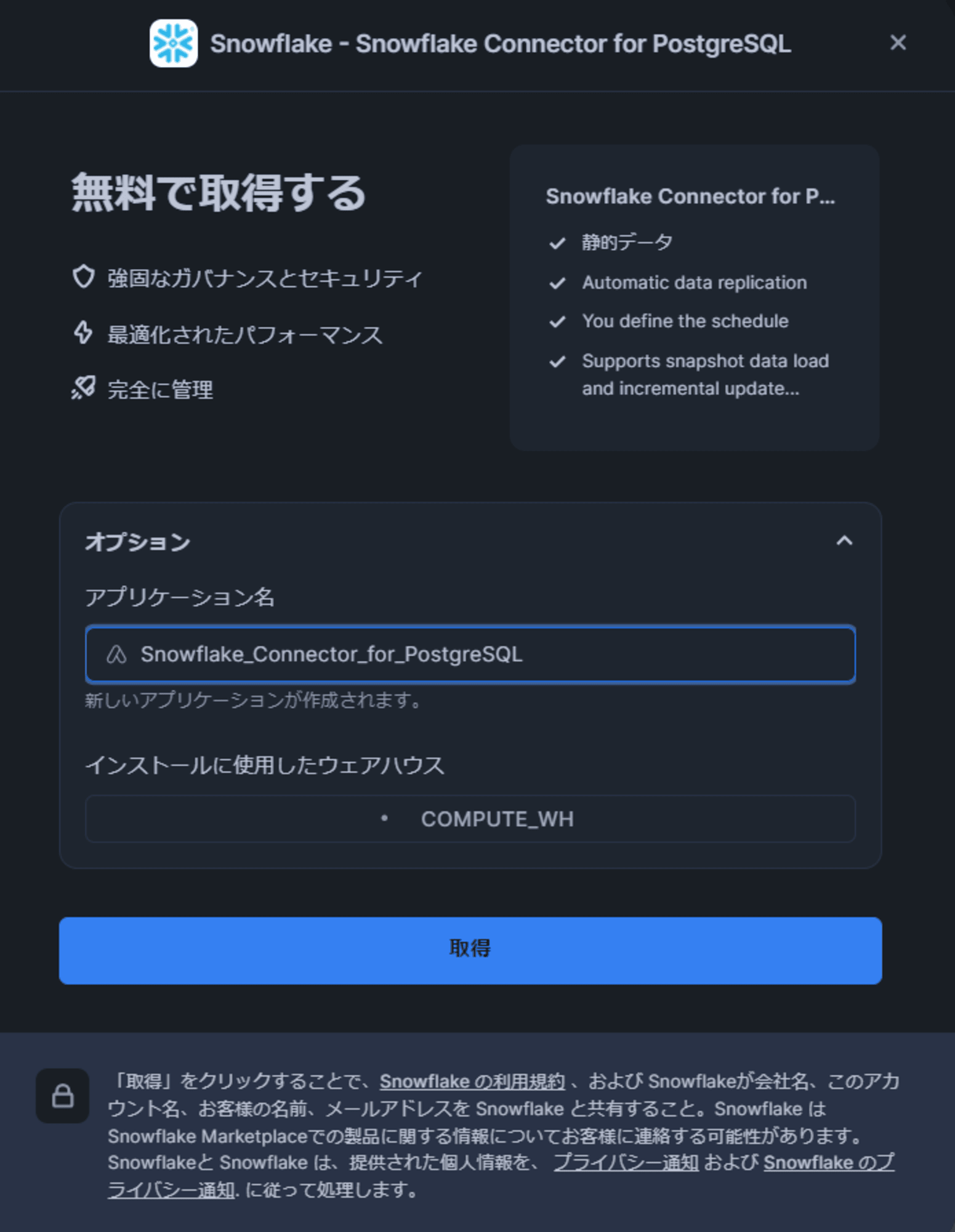
[取得] をクリックすると下図の表示になるので、任意のアプリケーション名を指定します。
インストール中の様子
コネクタの設定
アプリケーションがインストールされたら、設定画面を開きます。はじめにこれまでの各ステップを実施済みかの確認があるので、問題なければ「Mark as done」にチェックを入れ [Start configuration] をクリックします。
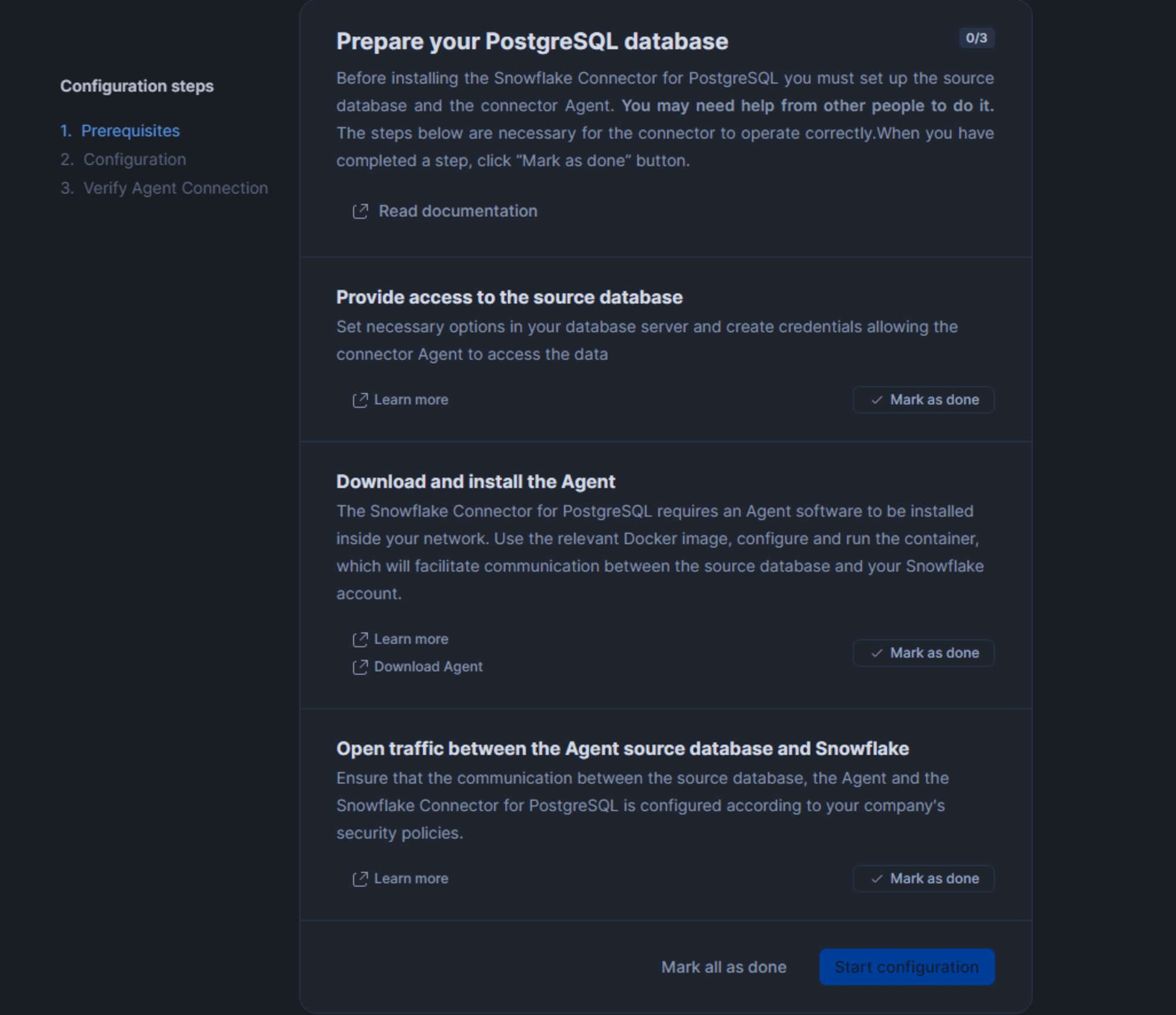
コネクタが使用するウェアハウスを作成、または指定します。公式ドキュメントにも記載がありますが、コネクタの使用には2種類のウェアハウスが必要です。デフォルトでは以下の名称で作成されます。
- SNOWFLAKE_CONNECTOR_FOR_POSTGRESQL_COMPUTE_WH
- エージェントから取得したデータを処理し、ターゲット テーブルに格納するために使用
- SNOWFLAKE_CONNECTOR_FOR_POSTGRESQL_OPS_WH
- コネクタとそのエージェントのアクティビティを管理するために使用
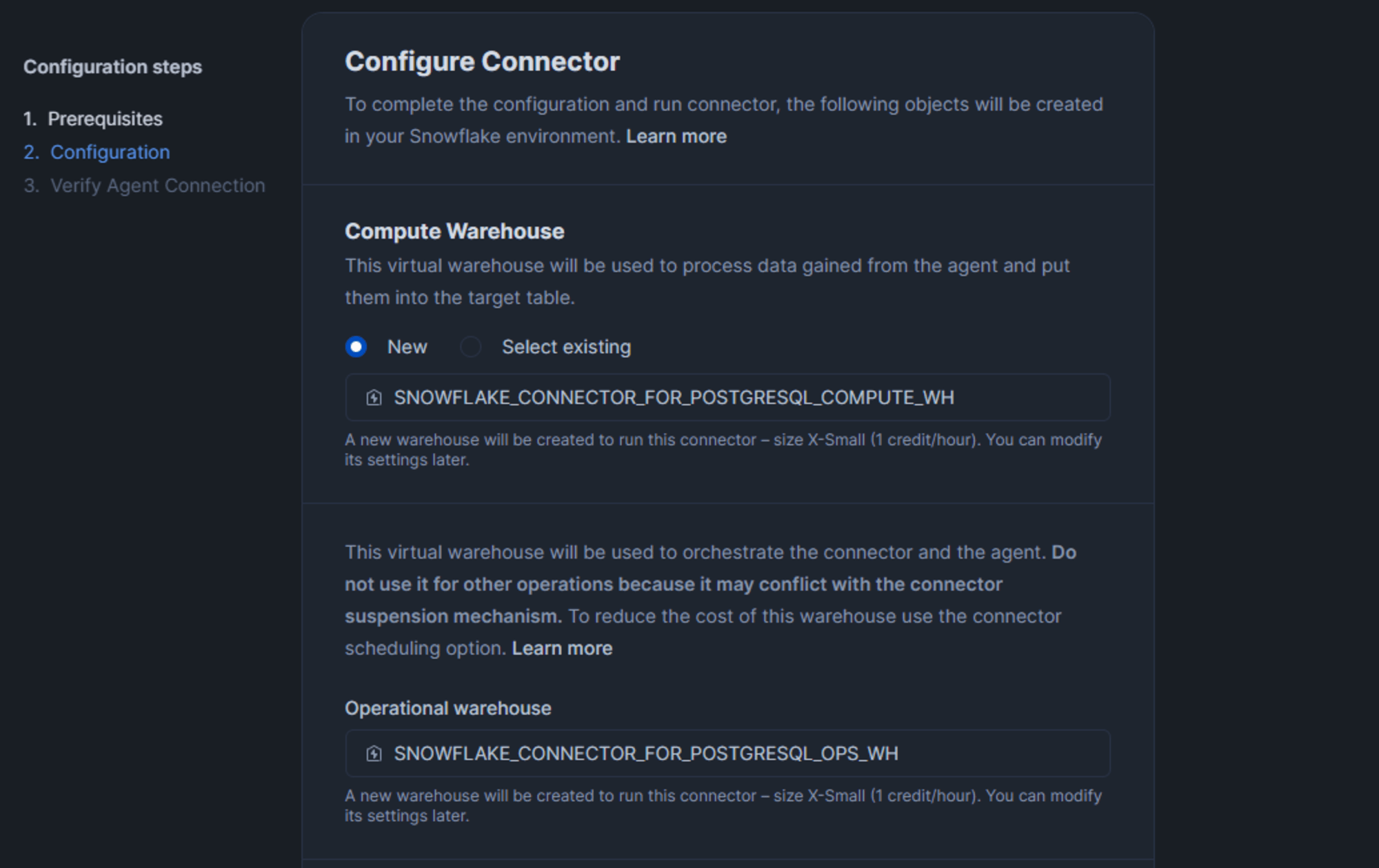
続けてエージェントが Snowflake への認証に使用するユーザーを指定します。デフォルトでは以下の内容で作成されます。
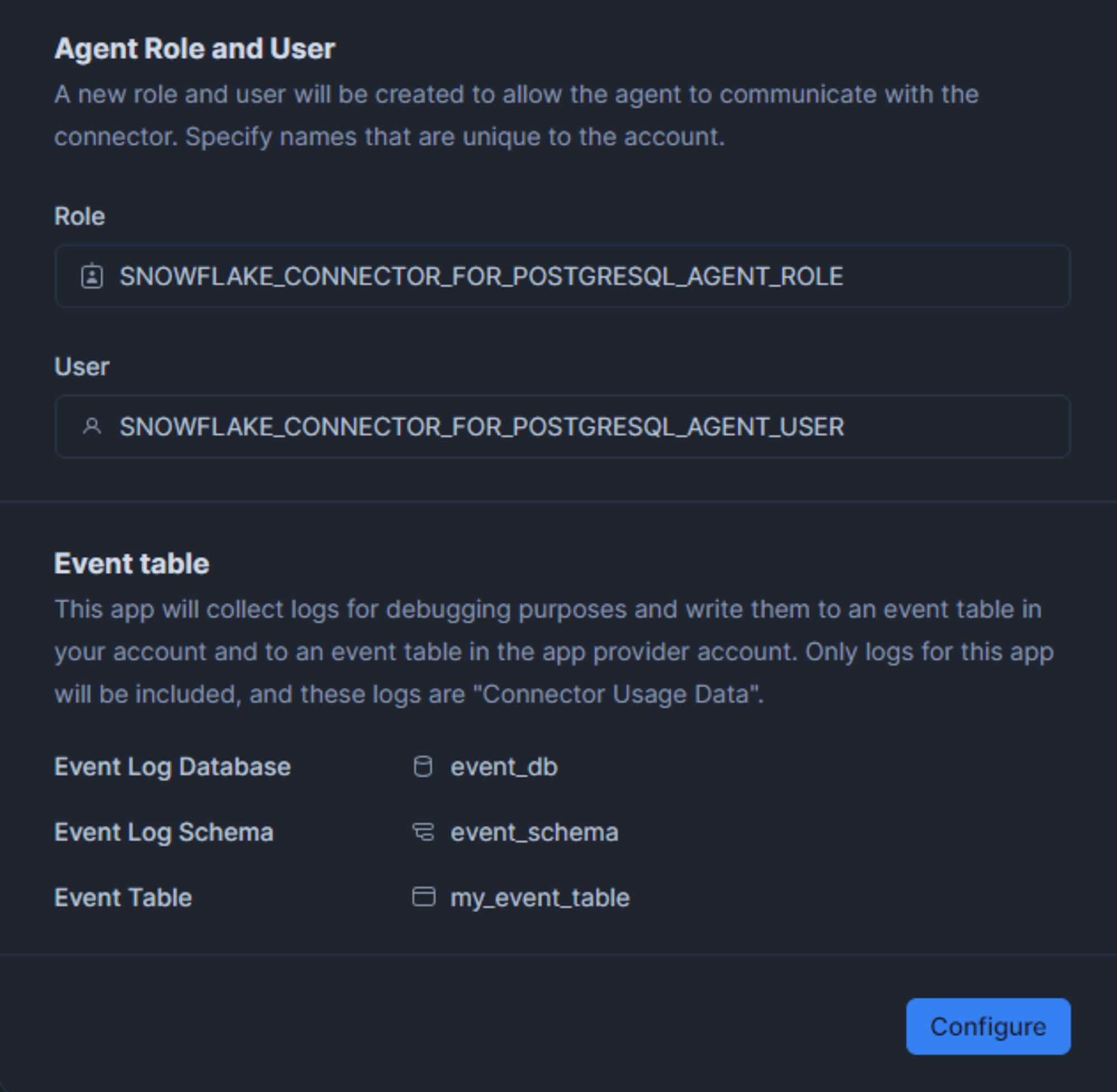
ここまでの設定ができたら、エージェントの構成ファイル(snowflake.json )をダウンロードできるので [Generate file] からダウンロードし、エージェントサーバに転送します。このファイルには、Snowflake への接続に使用される URL やエージェントからの接続に使用するユーザー情報、認証に使用される一時的なキーに関する情報が含まれます。
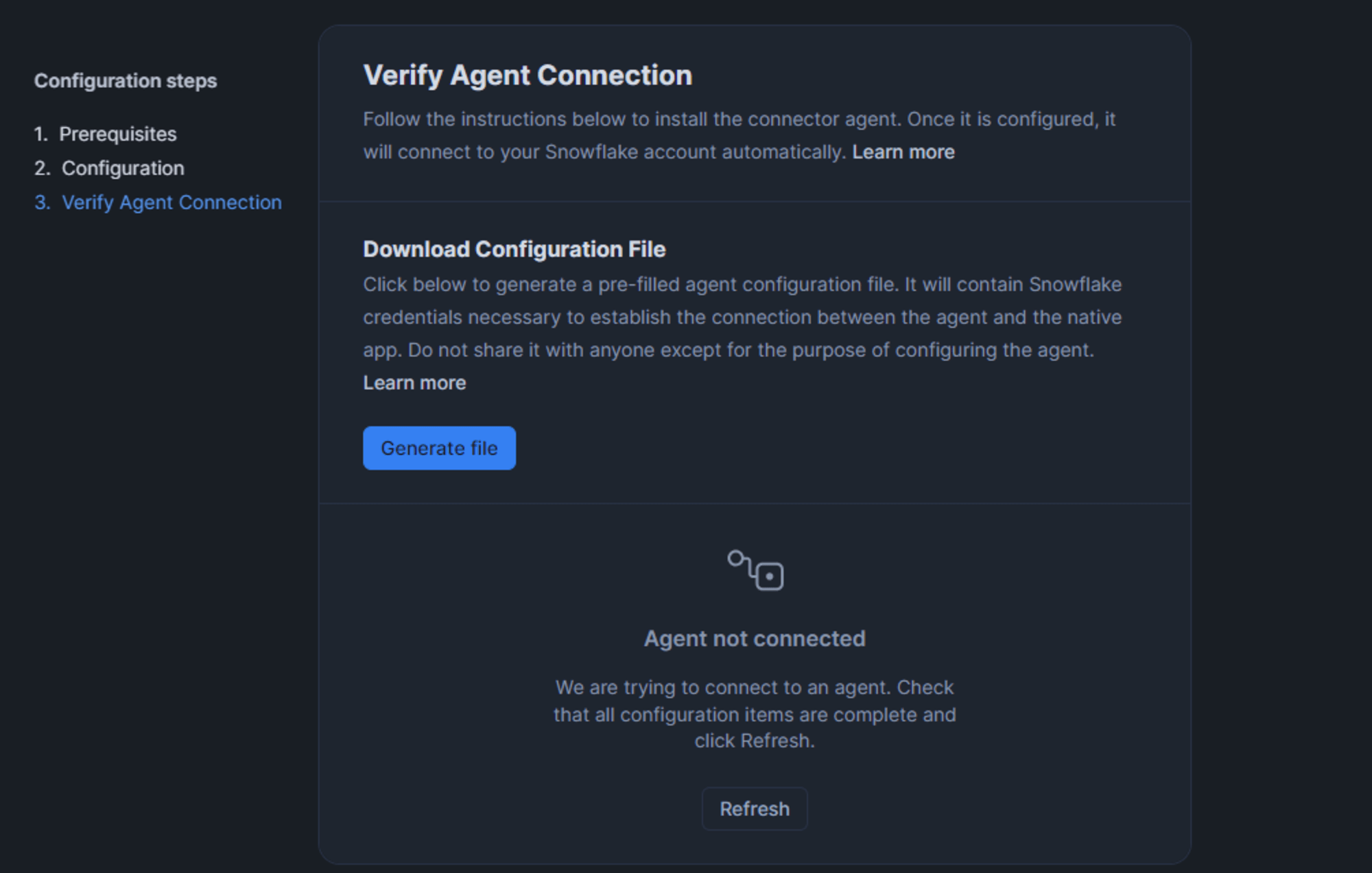
エージェントコンテナの起動
エージェントの構成ファイル(snowflake.json )をエージェントサーバに転送したら、configuration ディレクトリに配置します。この時点で以下のディレクトリ構成になります。
.
|-- agent-keys
|-- configuration
| |-- datasources.json
| |-- postgresql.conf
| `-- snowflake.json
`-- docker-compose.yml
必要なファイルを配置後、コンテナを起動します。
docker-compose up -d
起動後のディレクトリは以下の構成になっています。
.
|-- agent-keys
| |-- database-connector-agent-app-private-key.p8
| `-- database-connector-agent-app-public-key.pub
|-- configuration
| |-- datasources.json
| |-- postgresql.conf
| `-- snowflake.json
`-- docker-compose.yml
Snowsight:アプリの構成を続ける
エージェントが起動したら、構成中であった Snowsight に戻り [Refresh] をクリックします。
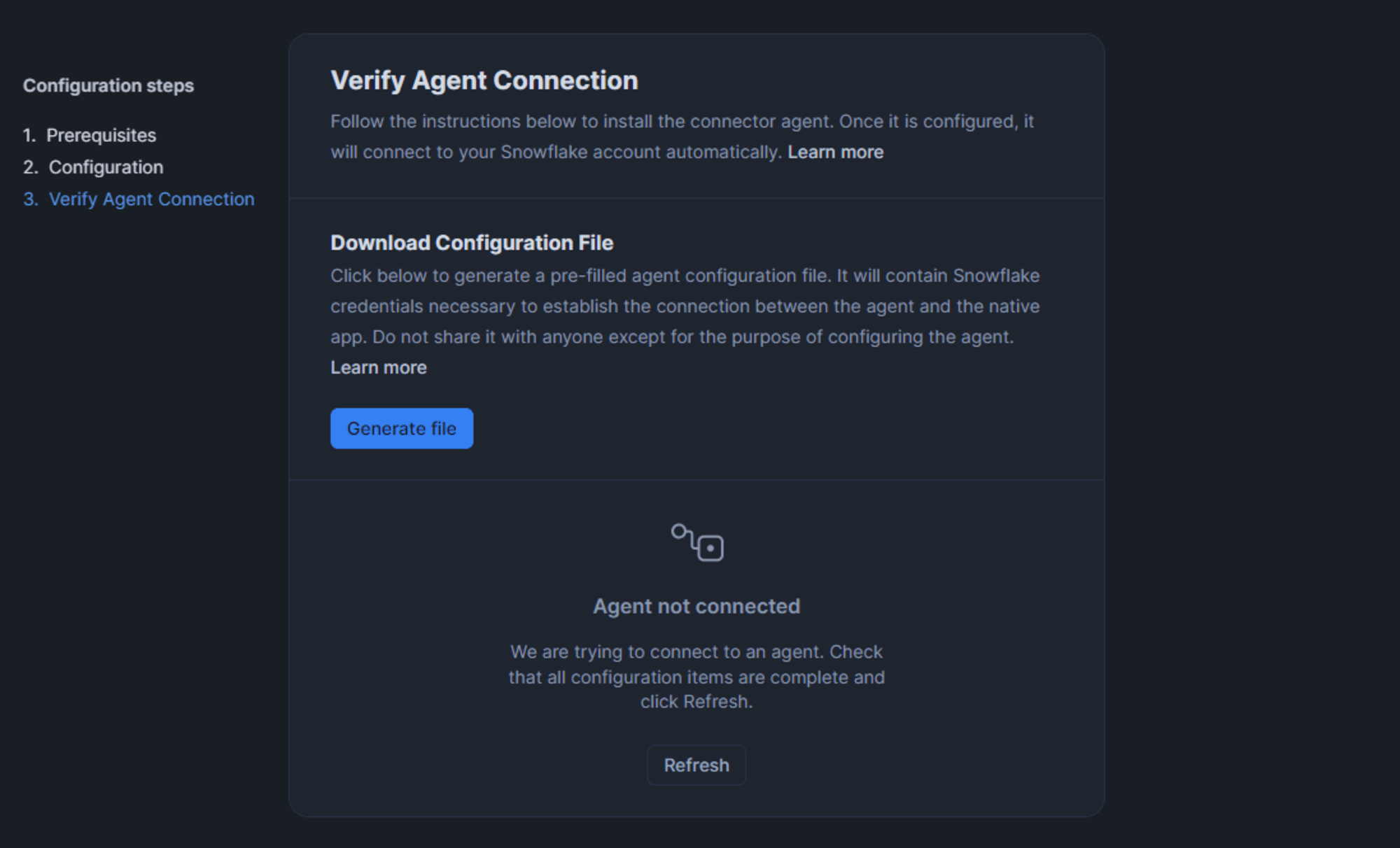
エージェントサーバから問題なく Snowflake アカウントに到達できれば以下の表示になります。
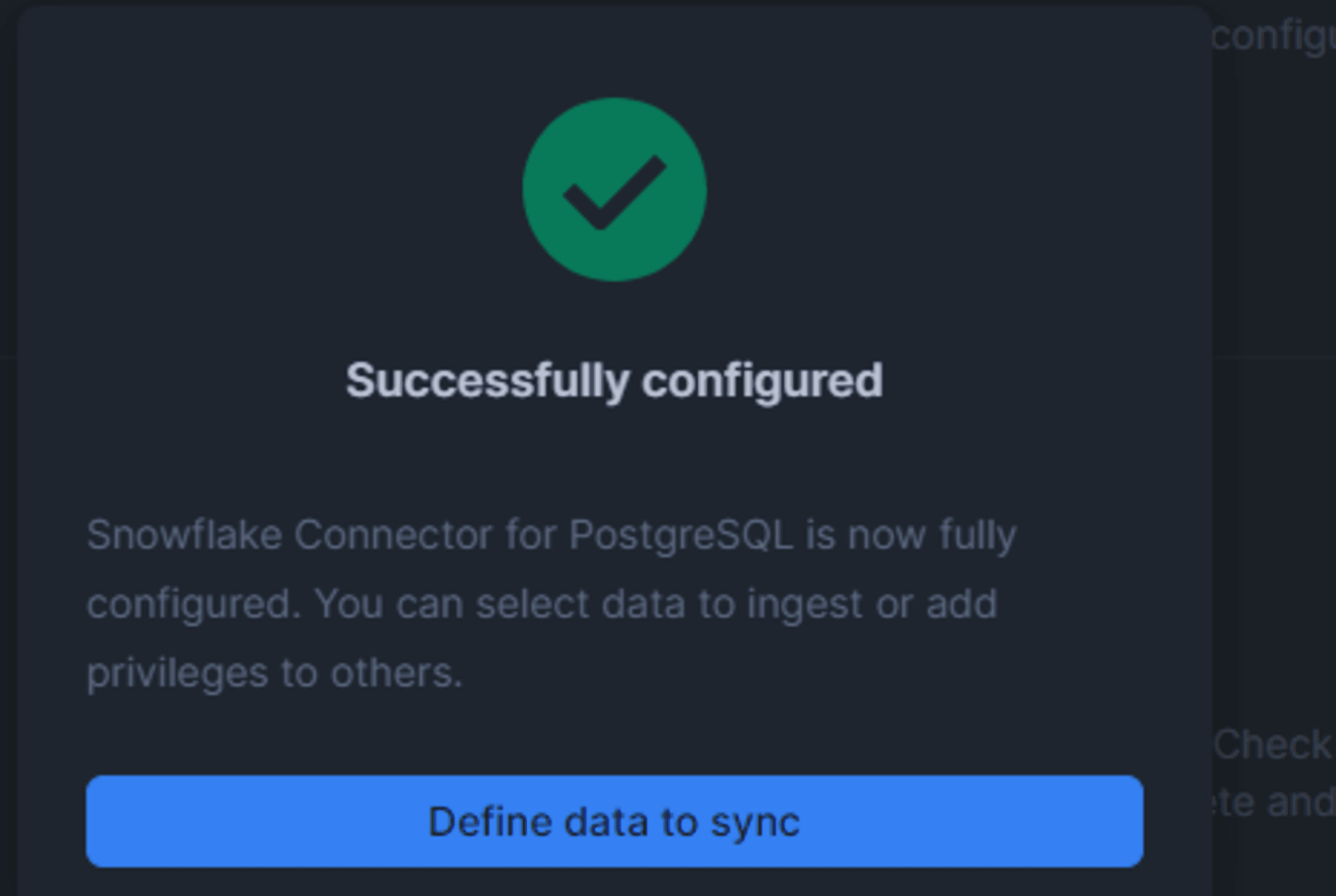
PostgreSQL 用 Snowflake コネクタのレプリケーションの構成
コネクタの構成が完了したら、実際にアカウントに同期するデータテーブルを選択します。手順は以下に記載があるのでこちらに沿って進めます。
宛先データベースの作成
ここでははじめに、以下の手順でデータのロード先となるデータベースを作成しておきました。
USE ROLE SYSADMIN;
CREATE DATABASE DEST_DB;
また、既存のデータベースを宛先データベースとして使用するには、PostgreSQL 用 Snowflake コネクタにそのデータベースに対するCREATE SCHEMA権限が必要なので、ドキュメントの通り以下で権限を与えました。
USE ROLE ACCOUNTADMIN;
GRANT CREATE SCHEMA ON DATABASE DEST_DB TO APPLICATION SNOWFLAKE_CONNECTOR_FOR_POSTGRESQL;
データソースの追加
続けて「データソース」を追加します。ここのでデータソースとは、単一の PostgreSQL サーバーを指します。ドキュメントによると、コネクタは複数のデータ ソース(複数の異なるサーバ)からデータを同期できるようです。ここでは、単一のサーバを追加します。
データソースの追加には、次のコマンドを使用します。
CALL PUBLIC.ADD_DATA_SOURCE('<data_source_name>', '<dest_db>');
データソースは名はdatasources.json で定義している名称で、以下の内容で定義したものになります。
{
"PSQLDS1": {
"url": "jdbc:postgresql://<RDSのエンドポイント>:5432/postgres",
"username": "sf_connector_user",
"password": "<パスワード>",
"publication": "mypublication",
"ssl": false
}
}
この場合、以下の内容でデータソースを追加しました。宛先データベースが存在しない場合は、自動的に作成されます。
--データソースを追加
USE DATABASE SNOWFLAKE_CONNECTOR_FOR_POSTGRESQL;
CALL PUBLIC.ADD_DATA_SOURCE('PSQLDS1', 'DEST_DB');
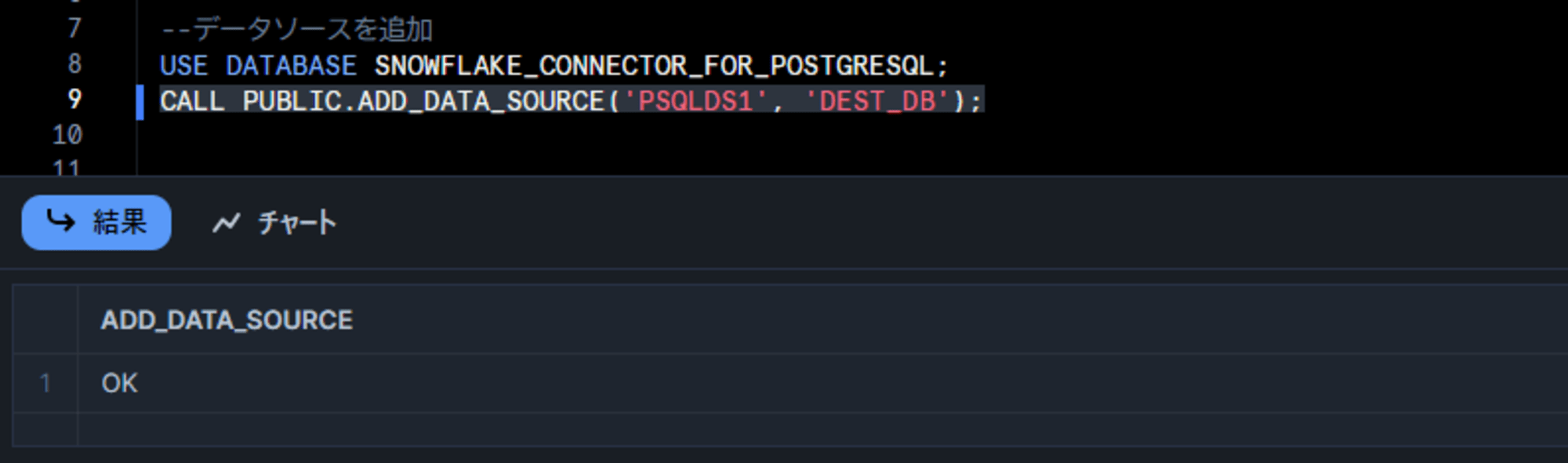
作成されたデータソースは以下のコマンドで確認できます。
SELECT * FROM PUBLIC.DATA_SOURCES;

テーブルの追加
さいごにレプリケーションの対象となるテーブルを指定します。これにより指定されたテーブルの同期が開始されます。はじめに以下を実行しcustomers テーブルを追加しました。コマンド実行時の注意点として、大文字小文字の区別を含めた正確なテーブル・スキーマ名を指定します。
CALL SNOWFLAKE_CONNECTOR_FOR_POSTGRESQL.PUBLIC.ADD_TABLES('PSQLDS1', 'public', ARRAY_CONSTRUCT('customers'));
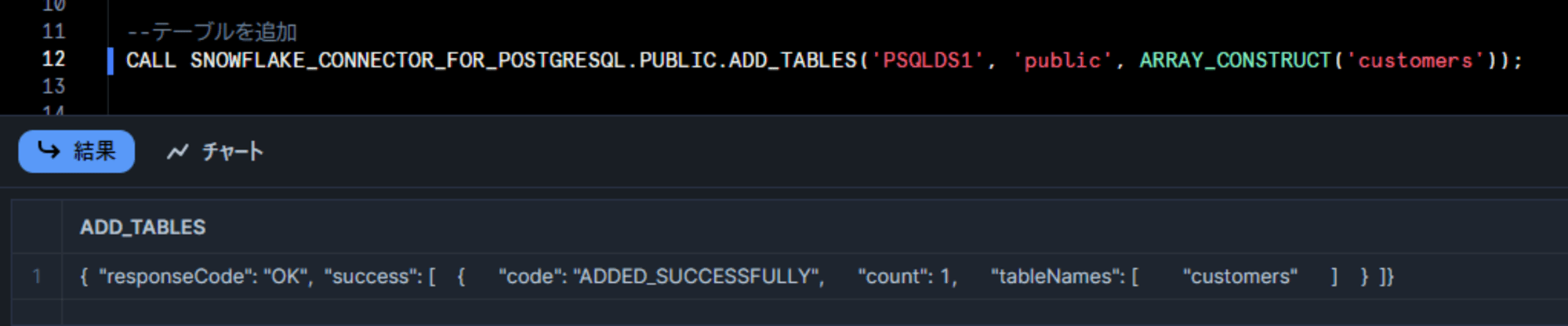
しばらくすると対象の宛先データベースにソーススキーマ・テーブルと同じ名称でデータが同期されました。
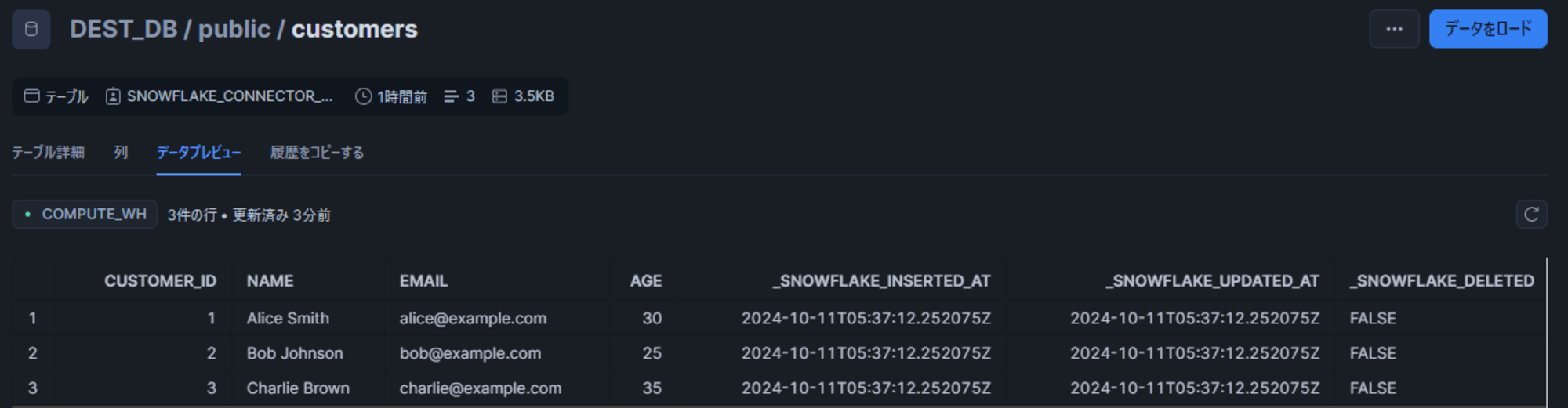
PostgreSQL からコネクタを使用した同期の特徴として、スキーマ・テーブル名は、大文字小文字の区別を含めてソースと同じ内容で作成されます。今回、PostgreSQL 側では特に引用符など無しでテーブル等を作成していました。PostgreSQL ではこの場合、常に小文字として解釈されるため、Snowflake 側でもスキーマ・テーブル名は小文字で作成されます。(カラム名は大文字扱いとなっていました。)
データの確認
データを確認する際は、DATA_READERアプリケーション ロールを使用できます。
これまでの手順による構成時点で権限を確認すると下図のようになっていました。
USE ROLE ACCOUNTADMIN;
USE DATABASE SNOWFLAKE_CONNECTOR_FOR_POSTGRESQL;
SHOW GRANTS TO APPLICATION ROLE SNOWFLAKE_CONNECTOR_FOR_POSTGRESQL.DATA_READER;

宛先スキーマに対する USAGE が含まれていなかったので、手動で読み取り用ロール(ここではSYSADMINを使用)に権限を付与し SYSADMIN でロード先のテーブルに対してクエリできるような設定としました。
GRANT USAGE ON SCHEMA DEST_DB."public" TO ROLE SYSADMIN;
GRANT APPLICATION ROLE SNOWFLAKE_CONNECTOR_FOR_POSTGRESQL.DATA_READER TO ROLE SYSADMIN;
テーブルを追加する
テーブルの追加は、先と同様の手順で実施できます。ここでは以下のコマンドを使用し残りのテーブルを追加しました。
USE ROLE ACCOUNTADMIN;
USE DATABASE SNOWFLAKE_CONNECTOR_FOR_POSTGRESQL;
CALL SNOWFLAKE_CONNECTOR_FOR_POSTGRESQL.PUBLIC.ADD_TABLES('PSQLDS1', 'public', ARRAY_CONSTRUCT('orders','products'));

しばらくすると Snowflake 側にテーブルとレコードの追加を確認できました。
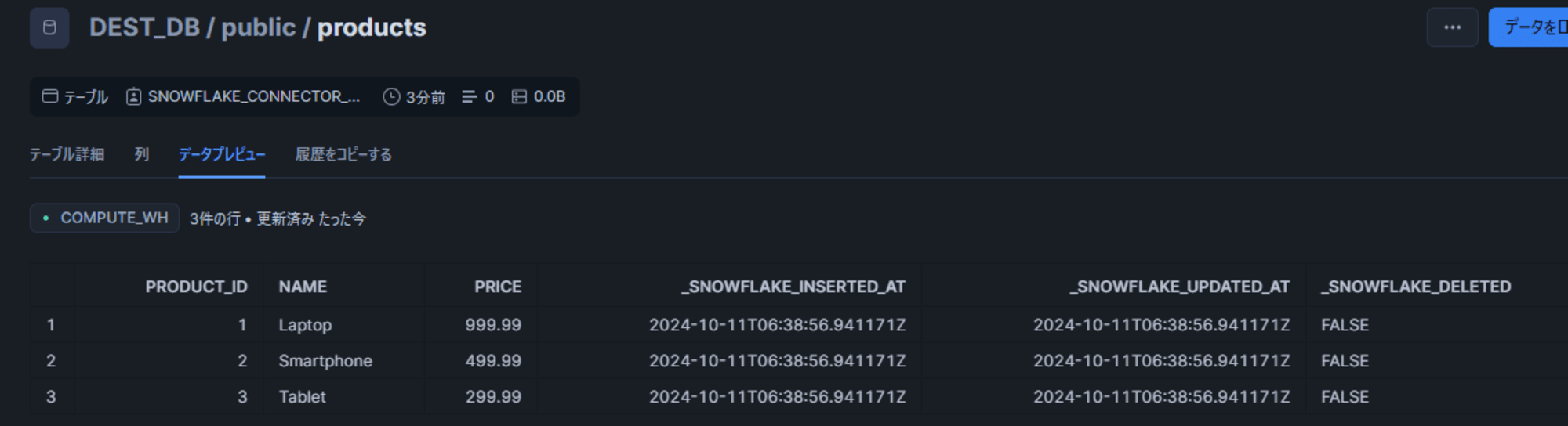
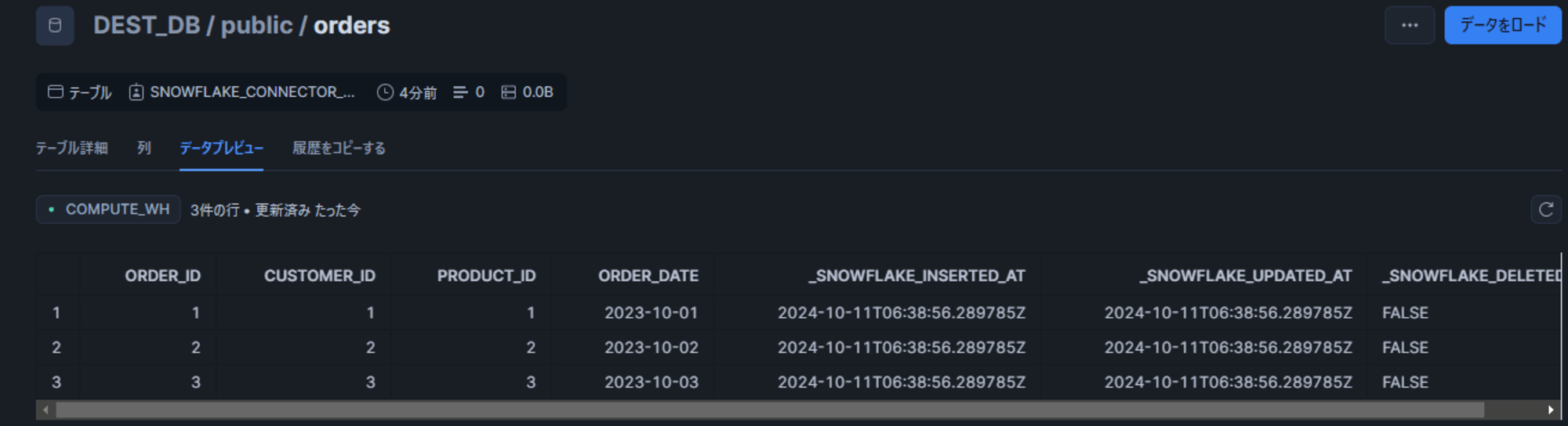
変更の確認
コネクタはソースデータベースで実行された変更をキャプチャ可能です。この変更には INSERT、UPDATE、および DELETE 操作が含まれ、これらの変更は Snowflake の宛先データベースに自動的に複製されるので挙動を確認してみます。
レコードの更新
ここではcustomersテーブルを使用します。
> SELECT * FROM customers;
customer_id | name | email | age
-------------+---------------+---------------------+-----
1 | Alice Smith | alice@example.com | 30
2 | Bob Johnson | bob@example.com | 25
3 | Charlie Brown | charlie@example.com | 35
(3 rows)
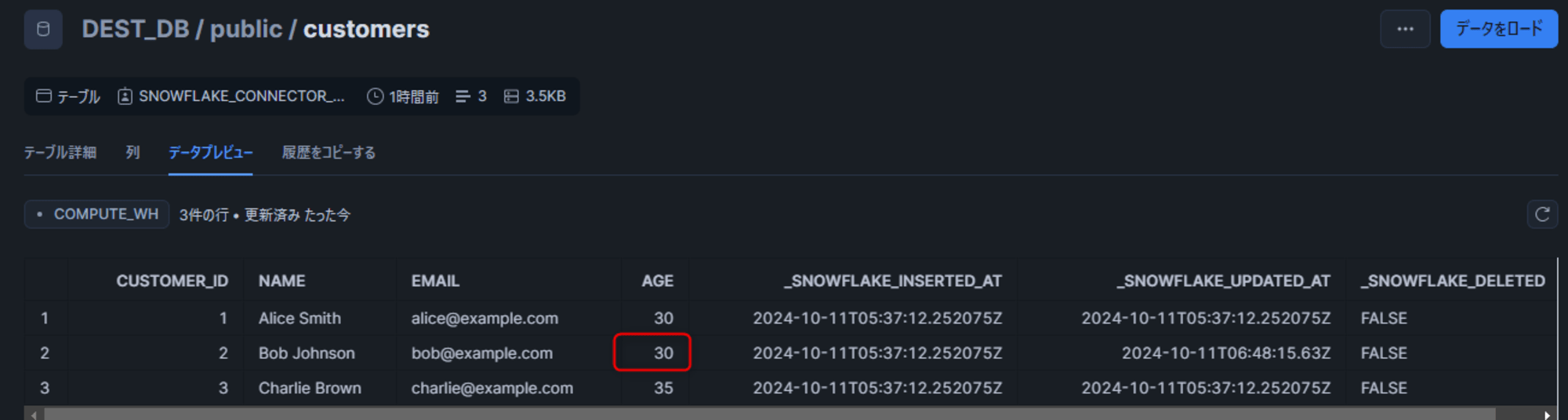
PostgreSQL 側でレコードを更新します。
UPDATE customers SET age = 30 WHERE customer_id = 2;
すぐに Snowflake 側でも変更が反映されました。
レコードの追加
PostgreSQL 側でレコードを追加します。
INSERT INTO customers (name, email, age) VALUES
('David Green', '[email protected]', 40),
('Eve White', '[email protected]', 28);
同様にすぐに変更が反映されました。
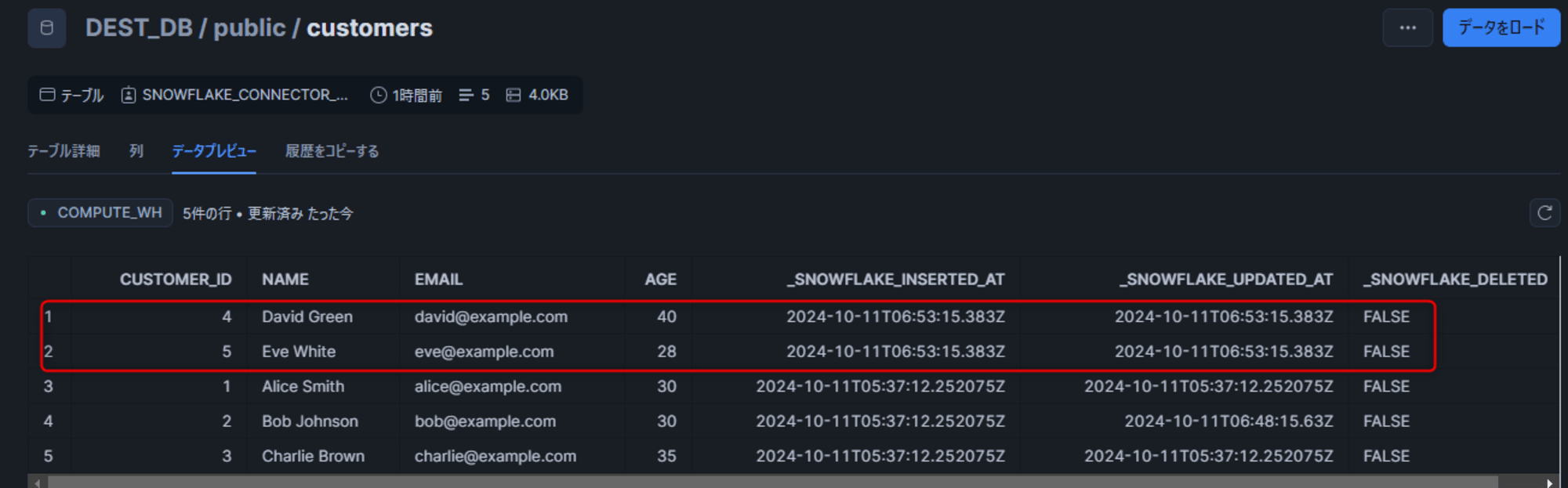
レコードの削除
PostgreSQL 側でレコードを削除します。
DELETE FROM customers WHERE customer_id = 4;
Snowflake 側では Soft Delete として扱われるため_SNOWFLAKE_DELETED がTRUEとなります。
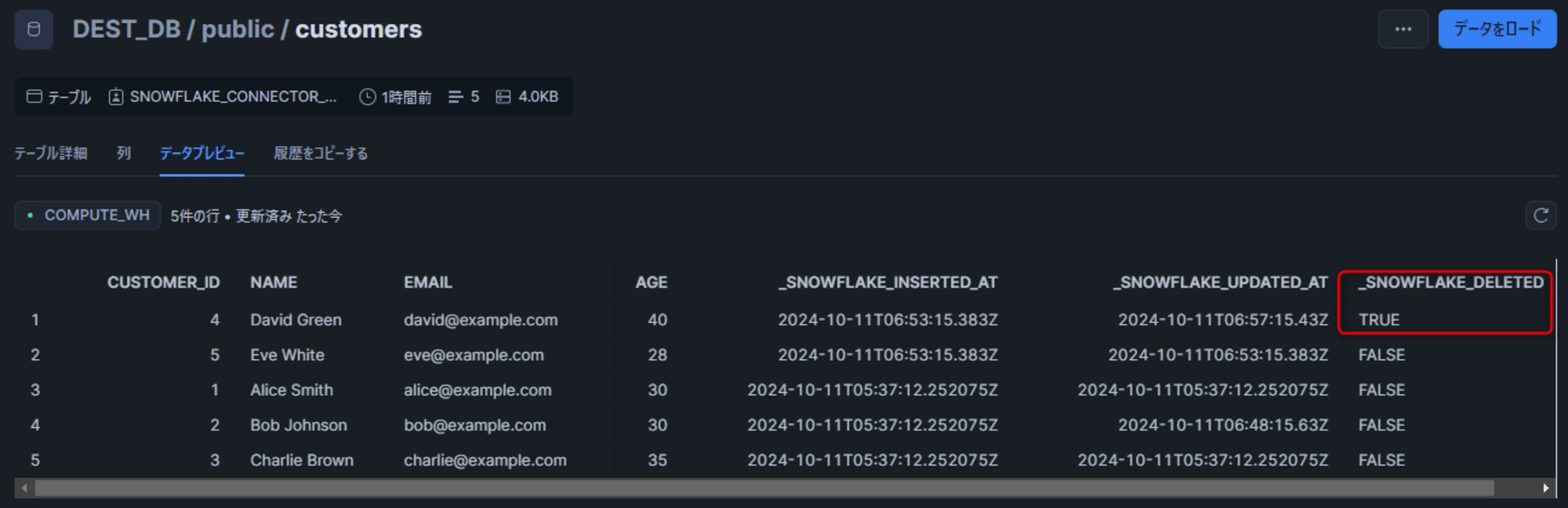
ソーステーブルスキーマの変更
コネクタはテーブルスキーマの変更にも一部対応しています。詳細は以下をご参照ください。ここでは対応する変更の内、カラム追加・カラム削除・カラムのリネーム時の挙動を確認します。
カラムの追加
PostgreSQL 側でカラムを追加します。
ALTER TABLE customers ADD COLUMN address VARCHAR(255);
> SELECT * FROM customers;
customer_id | name | email | age | address
-------------+---------------+---------------------+-----+---------
1 | Alice Smith | alice@example.com | 30 |
3 | Charlie Brown | charlie@example.com | 35 |
2 | Bob Johnson | bob@example.com | 30 |
5 | Eve White | eve@example.com | 28 |
(4 rows)
この場合、すぐに反映されなかったため、さらにレコードを追加しました。
INSERT INTO customers (name, email, age, address) VALUES
('Frank Black', '[email protected]', 45, '123 Maple Street');
> SELECT * FROM customers;
customer_id | name | email | age | address
-------------+---------------+---------------------+-----+------------------
1 | Alice Smith | alice@example.com | 30 |
3 | Charlie Brown | charlie@example.com | 35 |
2 | Bob Johnson | bob@example.com | 30 |
5 | Eve White | eve@example.com | 28 |
6 | Frank Black | frank@example.com | 45 | 123 Maple Street
(5 rows)
その後、変更が反映されたことが確認できました。
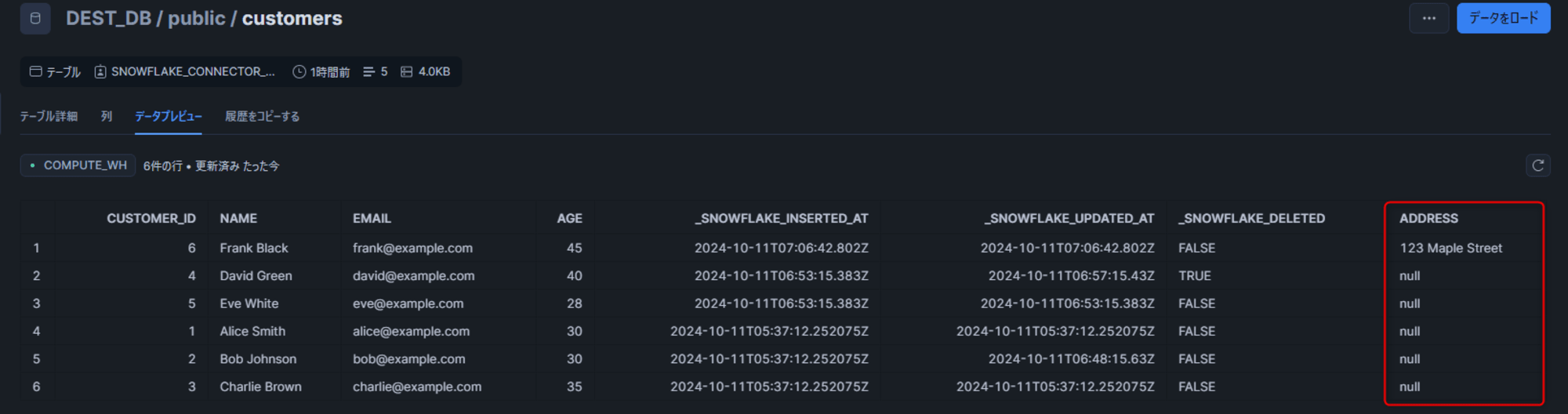
カラムの削除
PostgreSQL 側でカラムを削除します。
ALTER TABLE customers DROP COLUMN age;
こちらも追加時と同様にすぐに変更されないため、レコードを追加します。
INSERT INTO customers (name, email, address) VALUES
('Henry Ford', '[email protected]', '789 Pine Street');
> select * from customers;
customer_id | name | email | address
-------------+---------------+---------------------+------------------
1 | Alice Smith | alice@example.com |
3 | Charlie Brown | charlie@example.com |
2 | Bob Johnson | bob@example.com |
5 | Eve White | eve@example.com |
6 | Frank Black | frank@example.com | 123 Maple Street
7 | Henry Ford | henry@example.com | 789 Pine Street
(6 rows)
その後、変更の反映を確認できました。カラム削除も Soft Delete となり宛先テーブルでは削除されません。その代わりに、削除されたカラム名が<カラム名>__SNOWFLAKE_DELETEDに変更されます。
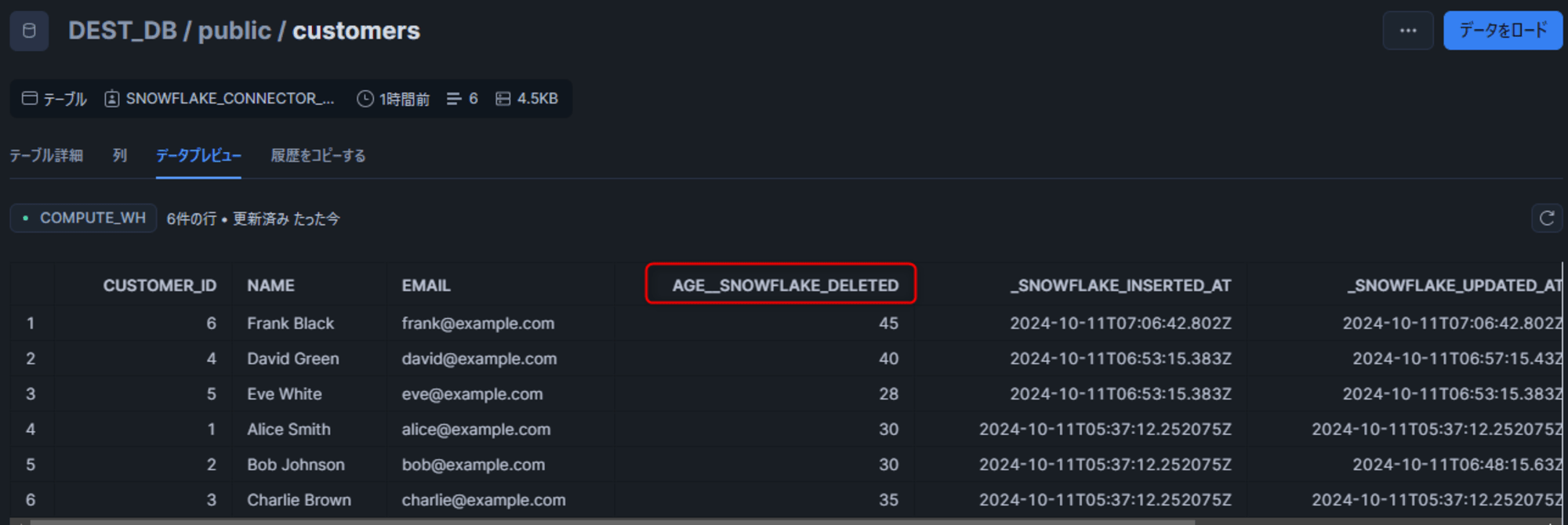
列名の変更
PostgreSQL 側でカラム名を変更します。この場合、列を削除して新しい名前で新しい列を作成することで変更が反映されます。
列名の変更
ALTER TABLE customers RENAME COLUMN name TO full_name;
この場合もすぐ変更が反映されないため、レコードの追加も行いました。
INSERT INTO customers (full_name, email, address) VALUES ('Ingrid Bergman', '[email protected]', '321 Birch Lane');
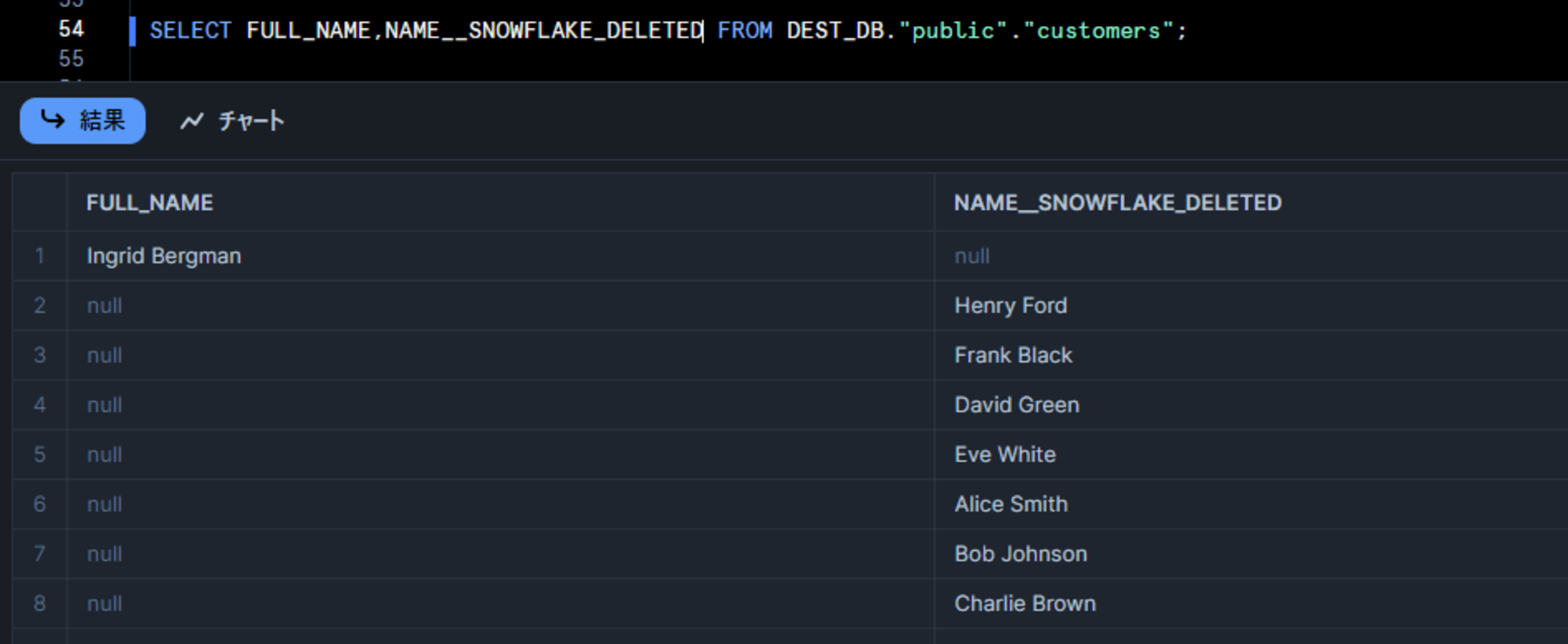
変更後は、下図のようになります。ポイントとして、変更前に存在していた行のデータは、Soft Delete されたカラム(NAME__SNOWFLAKE_DELETED)に残り、変更後に追加された新しい行は変更後のカラム(FULL_NAME)に保存されます。
さいごに
Snowflake Connector for PostgreSQL を構成しデータロードから変更のキャプチャができるまでの手順をまとめてみました。
コンテナの管理には ECS や Fargate を使用したり、ネットワーク面では PrivateLink にも対応しているので、この場合の設定も今後試してみたいと思います。同期の方法についても、記事ではデフォルトのままとしましたが、スケジュール実行も可能なので、こちらも試してみたいと思います。
こちらの内容が何かの参考になれば幸いです。


