![[Ruby]Redshiftへのインポートを自動的に行う](https://devio2023-media.developers.io/wp-content/uploads/2014/04/ruby.png)
[Ruby]Redshiftへのインポートを自動的に行う

はじめに
Redshiftへデータをインポートする際、S3へアップロード → Copyコマンドを実行してRedshiftへのインポート、ということが多いかと思います。この流れ(というほど大げさなものでもないですが)を自動的にできたらと思い、Rubyのサンプルプログラムを作成してみました。今回はその処理概要と実行方法について書きたいと思います。
前提条件と処理概要
前提条件
前提条件としては以下の通りです。
- Redshiftにインポートしたいデータファイルは、S3のバケットにアップロードするものとする。
- 予めS3のバケットにはS3 Event Notificationsを設定しておき、データファイルのアップロード時にSQSに書き込むようにする。
- Redshiftへの書き込みは、プログラムによりCopyコマンドを実行するものとする。このCopyコマンドはデータファイル毎に定義しておく(定義情報は後述する)。
- 処理済みのSQSのキューIDを登録するため、DynamoDBのテーブルを用意しておく。
処理概要
処理の概要を図にしてみました。
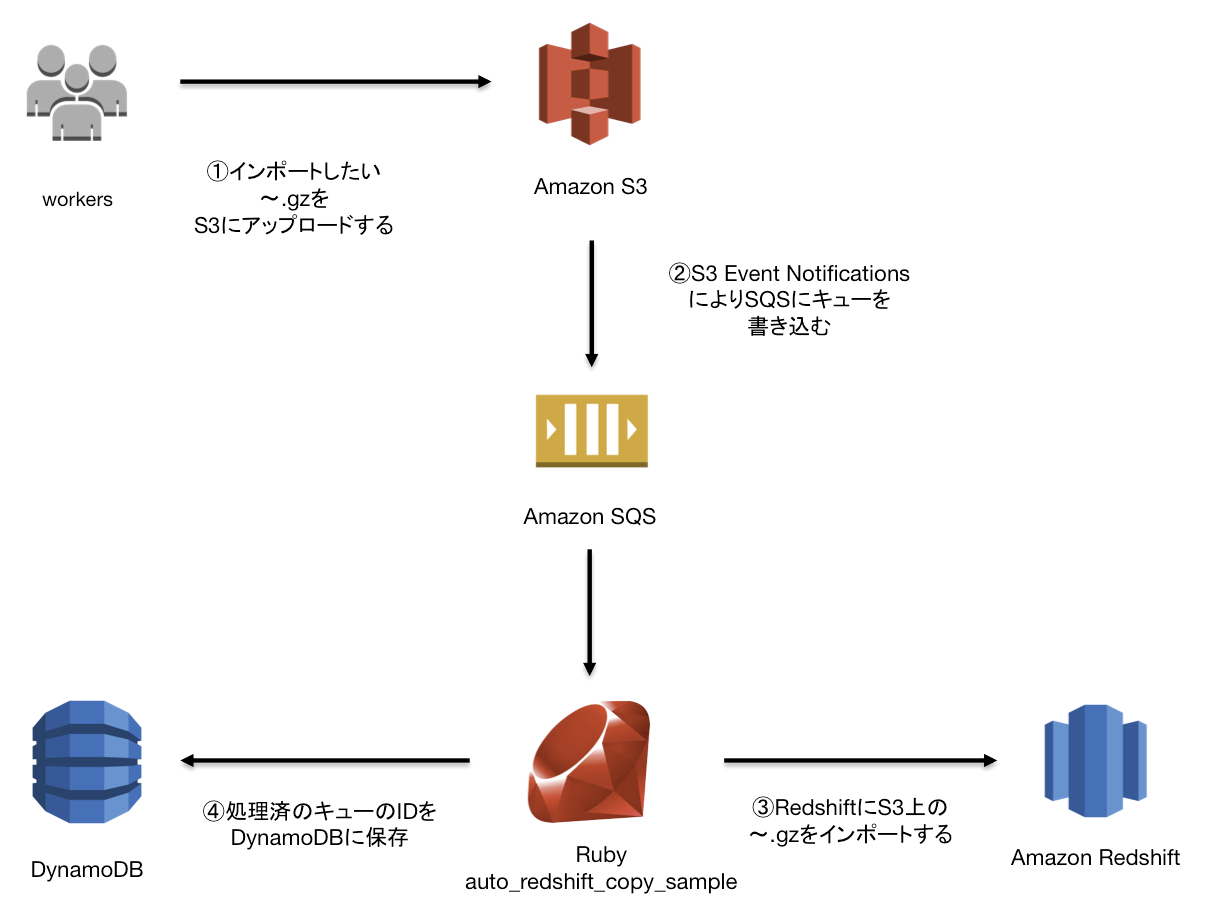
図にも書きましたが、処理の流れは以下のようになります。
- RedshiftにインポートしたいデータファイルをS3にアップロードする。
- S3 Event Notificationsにより、アップロードされたファイル名がSQSにキューとして登録される。
- サンプルプログラムはSQSのキューを監視し、キューが来た場合は処理を開始する。
- データファイルに対応するCopyコマンドを実行してRedshiftへのインポートを行う。
- インポート完了時、SQSよりキューを消し、DynamoDBに処理済みのキューのIDを書き込む。
実行方法
1.サンプルプログラムの配置
以下よりサンプルプログラムを取得し、任意のフォルダに配置します。
auto_redshift_copy_sample
※gemプロジェクトの形とはなっていますが、特にgemとなっているわけではないです。
2.定義ファイルの作成
以下のファイルを予め定義しておきます。
- config/application.yml・・・アプリの各種定義を記述
- config/command.yml・・・データファイル毎のcopyコマンドのパスを記述
- command/Copyコマンドファイル・・・copyコマンド
順に書き方を説明していきます。
config/application.yml
defaults: &defaults
wait:
second: 10 #処理をポーリングする間隔(秒)
sqs: #SQSに関する定義
url: 'https://sqs.ap-northeast-1.amazonaws.com/xxxx/yyyy' #SQSのURL
region: ap-northeast-1 #リージョン
profile: your_profile #~/.aws/credentialsのプロファイル名
dynamodb: #DynamoDBに関する定義
region: ap-northeast-1 #リージョン
profile: your_profile #~/.aws/credentialsのプロファイル名
message_ids_table: message_ids #DynamoDBのテーブル名
pgsql: #Redshiftに関する定義
host: 'xxxx.yyyy.ap-northeast-1.redshift.amazonaws.com' #RedshiftのHost名
user: your_user_name #Redshiftのユーザ名
password: your_passoword #Redshiftのパスワード
dbname: your_db_name #RedshiftのDB名
port: your_port #Redshiftのポート
s3: #データファイルを配置するS3に関する定義
bucket: your_bucket_name #S3のバケット名
folder: your_folder_name #S3のフォルダ名
credential: #Copyコマンドで指定するcredential
access_key: your_aws_access_key #AWSのaccess_key
secret_access_key: your_aws_secret_access_key #AWSのsecret_access_key
config/command.yml
defaults: &defaults
path:
sample1.csv.gz: command/sample1.sql #データファイル名:Copyコマンドのフルパス
sample2.csv.gz: command/sample2.sql #データファイル名:Copyコマンドのフルパス
command/sample1.sql(Copyコマンドファイル)
COPY sample1
FROM 's3://{$BUCKET}/{$FOLDER}/{$FILE_NAME}' -- {$BUCKET}、{$FOLDER}、{$FILE_NAME}はapplication.ymlに定義した値で置き換えられる
DELIMITER ','
CSV QUOTE AS '"'
gzip
IGNOREHEADER 0
CREDENTIALS 'aws_access_key_id={$AWS_ACCESS_KEY_ID};aws_secret_access_key={$AWS_SECRET_ACCESS_KEY}'; -- {$AWS_ACCESS_KEY_ID}、{$AWS_SECRET_ACCESS_KEY}はapplication.ymlに定義した値で置き換えられる
※CREDENTIALSの値は〜/.aws/credentialsに定義できるようしたほうが良いかもしれません。サンプルなので、取り敢えずはこのままで。
3.サンプルプログラムの起動
ターミナルでサンプルプログラムのフォルダに移動し、以下のコマンドでgemをインストールします。
$ bundle install --path vendor/bundle
以下のコマンドでアプリを起動します。サンプルなので無限にループしているだけなので、停止はcontrol+cでお願いします。(実運用するならDaemon化などを考えないといけないかもです。)
$ bundle exec ruby lib/start.rb
これでS3にデータファイルをアップロードすると、Redshiftへインポートされるはずです。
まとめ
実運用を考えると幾つか足りない箇所もありますが、S3へのアップロードを検知し、Redshiftへインポートを自動的に行うことはできました。何かの参考になれば幸いです。