![[セッションレポート] DVO401 AWSでのブルー・グリーン・デプロイメントに関するディープダイブ #reinvent](https://devio2023-media.developers.io/wp-content/uploads/2015/09/aws-reinvent2015.png)
[セッションレポート] DVO401 AWSでのブルー・グリーン・デプロイメントに関するディープダイブ #reinvent

ウィスキー、シガー、パイプをこよなく愛する大栗です。 re:Invent 2015のセッションをレポートします。
レポート
このセッションへの期待
- 一般的なデプロイのリスクの概要
- Blue/Greeデプロイの概念
- AWSでのBlue/Greenの利点
- AWS上でのアプリデプロイでののBlue/Greenパターン
- データ層のベストプラクティス
- コスト最適化
デプロイは簡単ではない
- 伝統的な環境では適切なアップグレードを好む
- リソースの制約
- ダウンタイム
- 依存性
- プロセスの協調
- 難しいロールバック
一般的なデプロイのリスク
課題
- アプリケーションの失敗
- インフラノ失敗
- 容量の問題
- スケーリングの問題
- 人の失敗
- プロセスの失敗
- ロールバックの問題
ビジネスインパクト
- ダウンタイム
- データ損失
- 悪いカスタマ・エクスペリエンス
- 収入源
- 気難しいマネージャー
- 燃え尽きたスタッフ
- 無駄にした時間/資源
AWS上のBlue/Greenデプロイの定義
Blue/Green Deploymentとは?
- Blue:既存の商用環境
- Green:アプリケーションの異なるバージョンを動作させる並列環境 ->例えば、アプリケーションコンポーネント、アプリ層、マイクロサービス
- デプロイ:二つの環境を切り替える機能 ->例えば、DNS、ロードバランサ
AWSでの環境のスコープ
狭い ↑ AMI、Auto Scaling Group | Amazon EC2 Container Service | AWS Elastic Beanstalk | AWS OpsWorks ↓ AWS CloudFormation 広い
環境境界の定義
| 要因 | 基準 |
|---|---|
| アプリケーションアーキテクチャ | 依存関係、疎/密結合 |
| 組織 | スピートと反復回数 |
| リスクと複雑さ | 爆発半径と失敗したデプロイの影響 |
| 人 | チームの専門性 |
| プロセス | テスト/QA、ロールバック機能 |
| コスト | 運用予算 |
全てのデプロイはスコープとリスクがあり難しい ->決まったパワフルな自動ツールのプラットフォームが必要
AWSでのBlue/Greenデプロイの利点
- 素早いデプロイ
- 柔軟なオプション
- スケーラブルな容量
- 使った分だけの課金
- 自動化機能
アプリデプロイでののBlue/Greenパターン
EC2インスタンスを使う場合
- 古典的なDNSカットオーバー
- Auto Scaling Groupの交換
- ローンチ・コンフィグレーションの交換
ECSを使う場合
- DNSを経由したECSサービスの交換
- ELBの背後のECSサービスの交換
- ECSタスク定義の交換
一般的なシナリオ:環境自動化
デプロイの成功は以下のリスクに依存します。
- アプリケーションの問題
- アプリケーションの性能
- 人/プロセスのエラー
- インフラストラクチャーの失敗
- ロールバック機能
- 大きなコスト
特に「人/プロセスのエラー」、「インフラストラクチャーの失敗」に対して自動化プラットフォームの強みが有ります。
CloudFormationは最も包括的な自動化プラットフォームです。
- ネットワークからソフトウェアまでのスタックの範囲
- 高レベルな自動化サービスコントロール:Elastic Beanstalk、ECS、OpsWorks、Auto Scaling
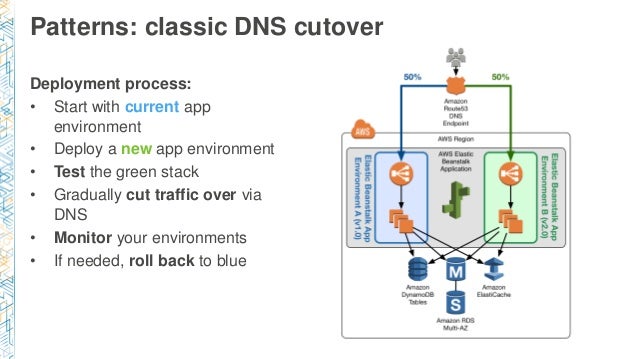
パターン:古典的なDNSカットオーバー
- 現在のアプリケーション環境を開始する
- 新しいアプリケーション環境をデプロイする
- Greenスタックをテストする
- DNS経由のトラフィックを徐々に減らす
- 環境を監視する
- 必要であればBlueへロールバックする
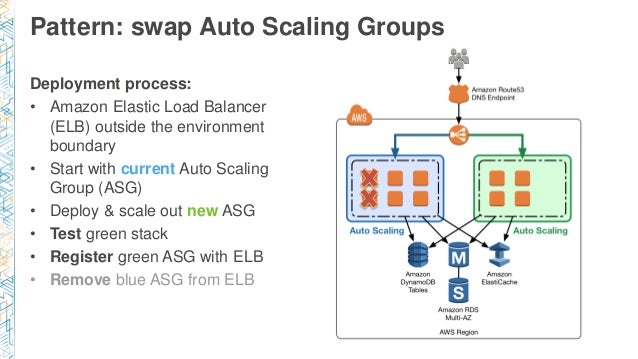
パターン:Auto Scaling Groupの交換
次はDNS使わない方法です。
- 環境境界の外側にELBを配置します
- 現在のAuto Scaling Groupを開始します。
- 新しいAuto Scaling Groupをデプロイ、スケールアウトします。
- Greenスタックをテストします
- GreenスタックをELBに登録し、Blueスタックを切り離します。
パターン:ローンチ・コンフィグレーションの交換
更に環境境界を減らします。
- ELBの背後で現在のオート・スケーリング・グループとローンチ・コンフィグレーションで起動します
- オート・スケーリング・グループにBlue/Greenのローンチ・コンフィグレーションを取り付けます
- 元のサイズの2倍まで徐々にオート・スケーリング・グループを拡張します
- 元のサイズにオート・スケーリング・グループを縮小します
- さらなるコントロールのために、古いインスタンスを待機します

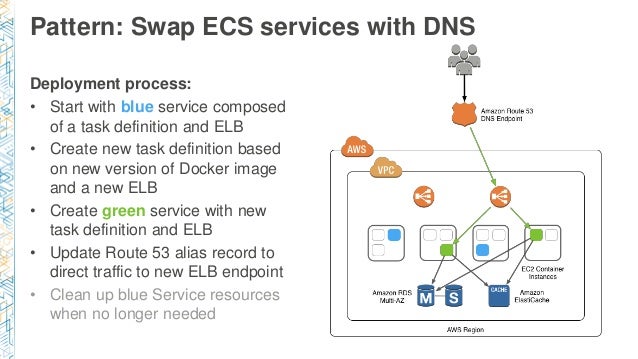
DNSを経由したECSサービスの交換
コンテナを起動している場合はどうなるか?
- タスク定義とELBで構成されるBlueサービスを開始します
- Docker imageの新しいバージョンと新しいELBで新しいタスク定義を作成します
- 新しいタスクの定義とELBでGreenサービスを作成します
- トラフィックを新しいELBエンドポイントからRoute 53のエイリアスレコードを更新します
- 不要になったらBlueサービスをクリーンアップします
ELBの背後のECSサービスの交換
- タスク定義とELBで構成されるBlueサービスを開始します
- Docker imageの新しいバージョンで新しいタスク定義を作成します。
- 新しいタスク定義とGreenサービスを作成し、既存のELBに取り付けます
- タスクの数をインクリメントすることにより、Greenサービスをスケールアップします
- タスク数を0に設定することでBlueサービスの使用を停止します

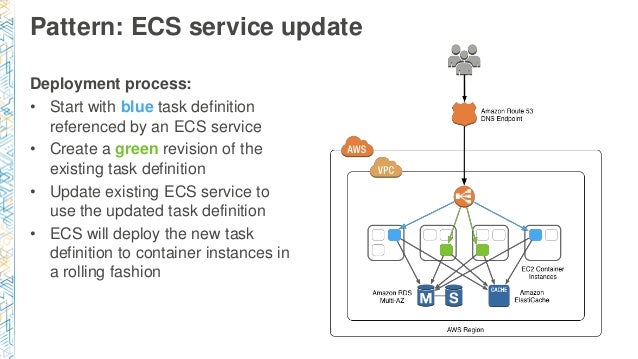
ECSサービスのアップデート
- ECSサービスで参照されるBlueタスク定義を開始します
- 既存のタスク定義のGreenリビジョンを作成します
- 更新されたタスク定義を使用するために既存のECSサービスを更新します
- ECSはローリング方式でコンテナインスタンスに新しいタスク定義をデプロイします
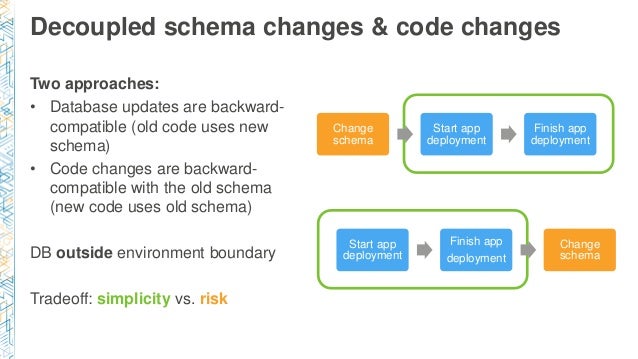
スキーマ変更はどうするか?
スキーマ変更とコード変更を切り離すには2つのアプローチが有ります。
- データベース更新が後方互換性を持つ
- コード変更は古いスキーマに対して後方互換性を持つ
DB外部の環境境界 シンプルさとリスクのトレードオフ
スキーマ変更が切り離せないか、リージョン間でデプロイする場合はどうするのか?
書き込みプロセスの一元化
- 書き込みプロセスを一元化して集約しデプロイします
- 共通のデータ基準:データストア特有のレプリケーションを使用します
- 集約したワーカーは両環境ノデータ変更に影響します。
- 遅れ/待ち時間を配慮するアカウント

一元化した書き込みプロセスをシンプルにします
- Greenアプリは両方のDBに書き込みます。 非同期でGreenアプリがBlueデータベースに変更を行います 一貫性の要件に不一致が有るか(古いアプリは強い一貫性を必要とします)
- 各アプリは各々のDBへ書き込みます 非同期で他のDB変更をプッシュします 完全に分離したアーキテクチャ 例えば、DynamoDBのテーブル+Stream+triggers+Lambdaファンクション

Blue/Greenデプロイパターンのまとめ
パターン
| リスク軽減 | 古典的なDNSカットオーバー | Auto Scaling Groupの交換 | ローンチ・コンフィグレーションの交換 | DNSを経由したECSサービスの交換 | ELBの背後のECSサービスの交換 | ECSサービスの更新 |
|---|---|---|---|---|---|---|
| アプリケーションの問題 | カナリア分析 | カナリア分析 | 混在したフリート | カナリア分析 | カナリア分析 | 混在したフリート |
| アプリケーションパフォーマンス | きめ細かいトラフィック切り替え | インスタンスレベルの粒度 | 混在したフリート | ELBは事前ウォーミングが必要な場合有り | コンテナレベルの粒度、ウォーミングしたELB | トラフィック管理無し、ウォーミングしたELB |
| 人/プロセスエラー | 自動化:CloudFormationと共にElastic Beanstalk、OpsWork、サードパーティを使用 | 自動化:CloudFormationと共にElastic Beanstalk、OpsWork、サードパーティを使用 | 自動化:CloudFormationと共にElastic Beanstalk、OpsWork、サードパーティを使用 | シンプルなプロセスのDNS切り替え | 多段階プロセス | ECSの自動化 |
| インフラストラクチャの障害 | 自動化フレームワーク | オートスケーリング、ELB | オートスケーリング、ELB | CloudWatch、オートスケーリング、ELB | CloudWatch、オートスケーリング、ELB | CloudWatch、オートスケーリング、ELB |
| ロールバック機能 | DNS | ELB | ELB | DNS | ECSの自動化 | ECSの自動化 |
| 原価管理 | 段階的なスケーリング | 段階的なスケーリング | いくつかのオーバープロビジョニング | クラスタインスタンスの追加が必要 | リソースの再利用 | ローリングデプロイ |
| デプロイの複雑さ | シンプル、DNSの重み付け | オートスケーリング制御 | スケールインの調整 | シンプル、DNSの重み付け | 多段階プロセス | 高度な自動化 |
デプロイプロセスに慣れる
デプロイは常にリスクと関連します
- デプロイと自動化フレームワークはプロセスエラーとヒューマンエラーを低減します
- 商用環境のような複製環境を使用してデプロイに慣れます
- AWSは迅速はプロビジョン済みリソース、新しいアプローチを実験する柔軟性を手頃な価格で提供します
さいごに
デプロイ方法の解説では、アプリケーション層の切り替えについて言及することは多いですが、スキーマ変更を伴うDB変更についての解説は少ないと思います。今回のセッションはDB変更時の考え方が学べたので、ほんとうに勉強になりました。






![[レポート] インシデント発生に備えるための議論をする tabletop「Incident response tabletop: Supply chain」 #GHJ205-R #AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/3IQLlbdUkRvu7Q2LupRW2o/edff8982184ea7cc2d5efa2ddd2915f5/reinvent-2024-sessionreport-jp.jpg)
