
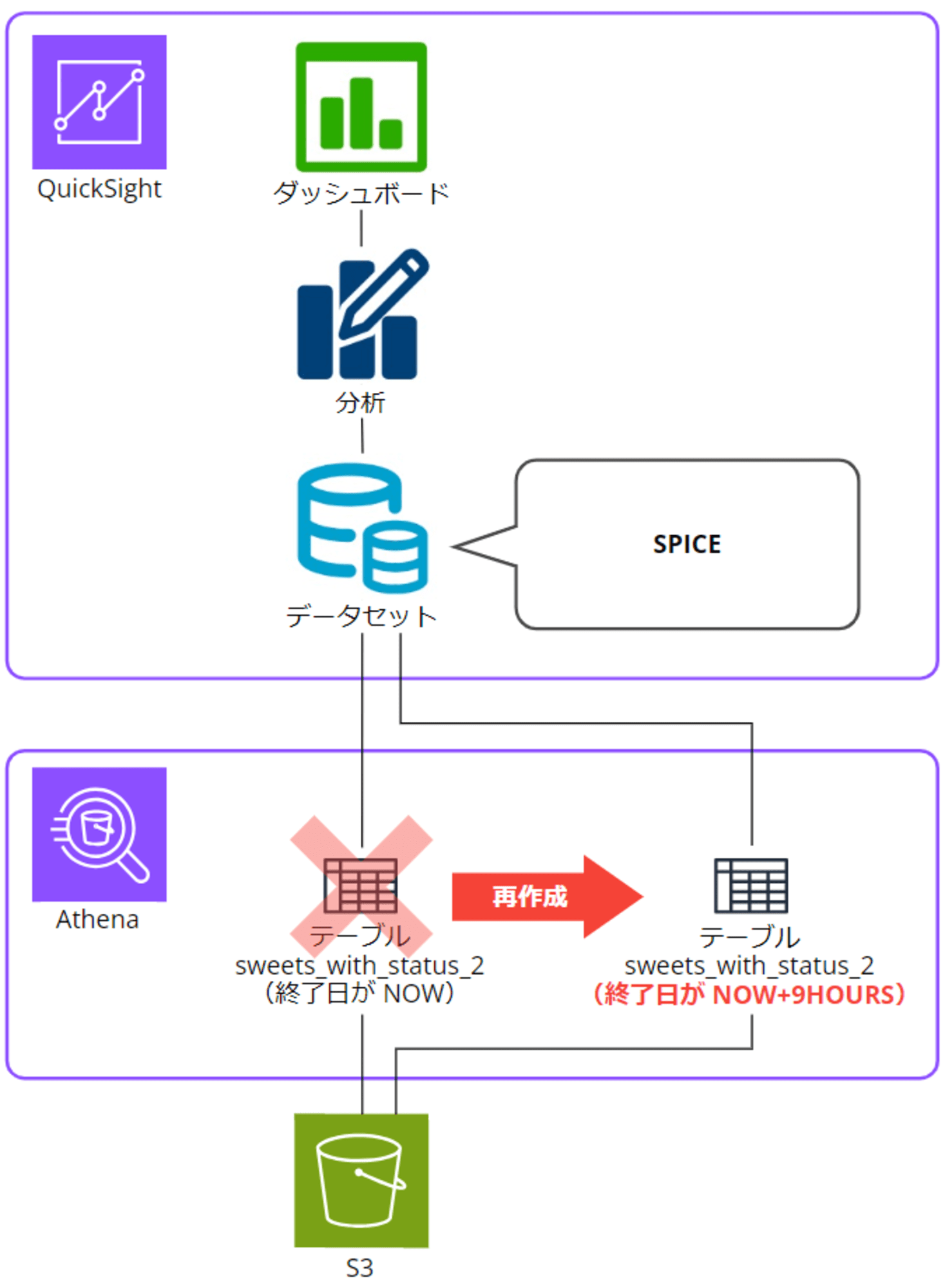
QuickSight データセットに設定した Athena で Partition Projection の終了日を変更したテーブルを同じ名前で再作成しても大丈夫かやってみた

コーヒーが好きな emi です。
以下ブログの通り、Athena の Partition Projection(パーティション射影)で range の終了日を NOW にしてしまい、日本時間の最新データが読み込めないテーブルを作成してしまいました。そしてそのまま QuickSight データセットのデータソースに設定してしまいました。
Athena 側で一度テーブルを削除し、 Partition Projection で range の終了日を変更した同じ名前のテーブルを再作成したいと思ったのですが、分析やダッシュボードが壊れたりしないか心配になったので、大丈夫か試してみました。
S3 に CSV データを配置
以下のようなパスに、
s3://<S3 バケット名>/sweets_with_status/jst/2024/10/22/05/0500_sweets_with_status.csv
以下のようなデータを日付を変えていくつか入れています。検証時間は 2024/10/22 05:00 JST くらいです。
datetime,department,section,status,chocolate,donut,osenbei
2024-10-22 05:00:00.000,コンピューティング部,EC2課,不調,1,1,1
2024-10-22 05:00:00.000,コンピューティング部,Lambda課,不調,1,1,1
2024-10-22 05:00:00.000,コンピューティング部,Lightsail課,不調,1,1,1
2024-10-22 05:00:00.000,ストレージ部,EFS課,超ごきげん,1,1,1
2024-10-22 05:00:00.000,ストレージ部,FSx課,ごきげん,1,1,1
2024-10-22 05:00:00.000,ストレージ部,S3課,不調,1,1,1
2024-10-22 05:00:00.000,データベース部,RDS課,普通,1,1,1
2024-10-22 05:00:00.000,データベース部,DocumentDB課,不調,1,1,1
2024-10-22 05:00:00.000,データベース部,DynamoDB課,超ごきげん,1,1,1
Athena テーブルの作成(NOW)
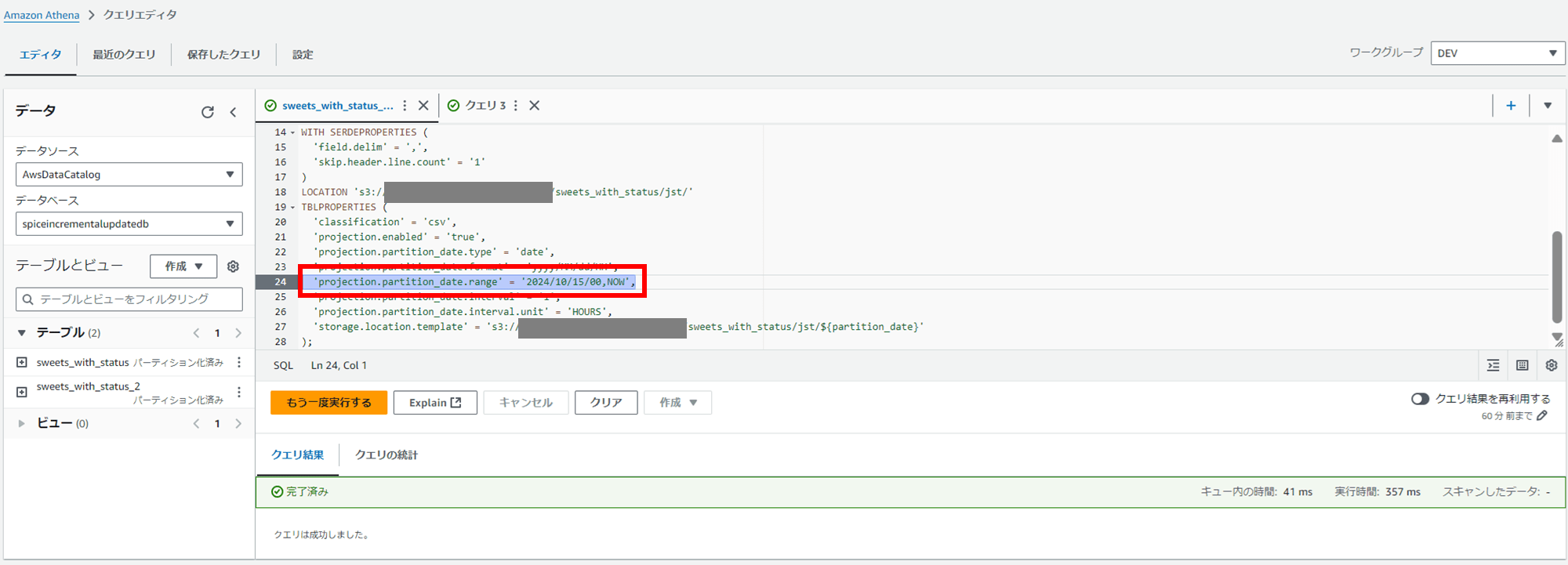
Athena テーブル sweets_with_status_2 を作成します。projection.partition_date.range の終了日を NOW にしておきます。これで、日本時間の最新データは取り込めない想定です。
CREATE EXTERNAL TABLE IF NOT EXISTS `spiceincrementalupdatedb`.`sweets_with_status_2` (
`datetime` timestamp,
`department` string,
`section` string,
`status` string,
`chocolate` int,
`donut` int,
`osenbei` int
)
PARTITIONED BY (
`partition_date` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim' = ',',
'skip.header.line.count' = '1'
)
LOCATION 's3://<S3 バケット名>/sweets_with_status/jst/'
TBLPROPERTIES (
'classification' = 'csv',
'projection.enabled' = 'true',
'projection.partition_date.type' = 'date',
'projection.partition_date.format' = 'yyyy/MM/dd/HH',
'projection.partition_date.range' = '2024/10/15/00,NOW',
'projection.partition_date.interval' = '1',
'projection.partition_date.interval.unit' = 'HOURS',
'storage.location.template' = 's3://<S3 バケット名>/sweets_with_status/jst/${partition_date}'
);
できました。
S3 からデータを取得できるか試します。
SELECT * FROM "spiceincrementalupdatedb"."sweets_with_status_2";
できました。古い日付のデータは持ってこれていますが、最新時間の 2024/10/22 05:00 時点のデータは取得できていません。ここまで想定通りです。
QuickSight データセット、分析、ダッシュボードの作成
作成した Athena をデータソースとして、QuickSight データセット、分析、ダッシュボードを作成します。
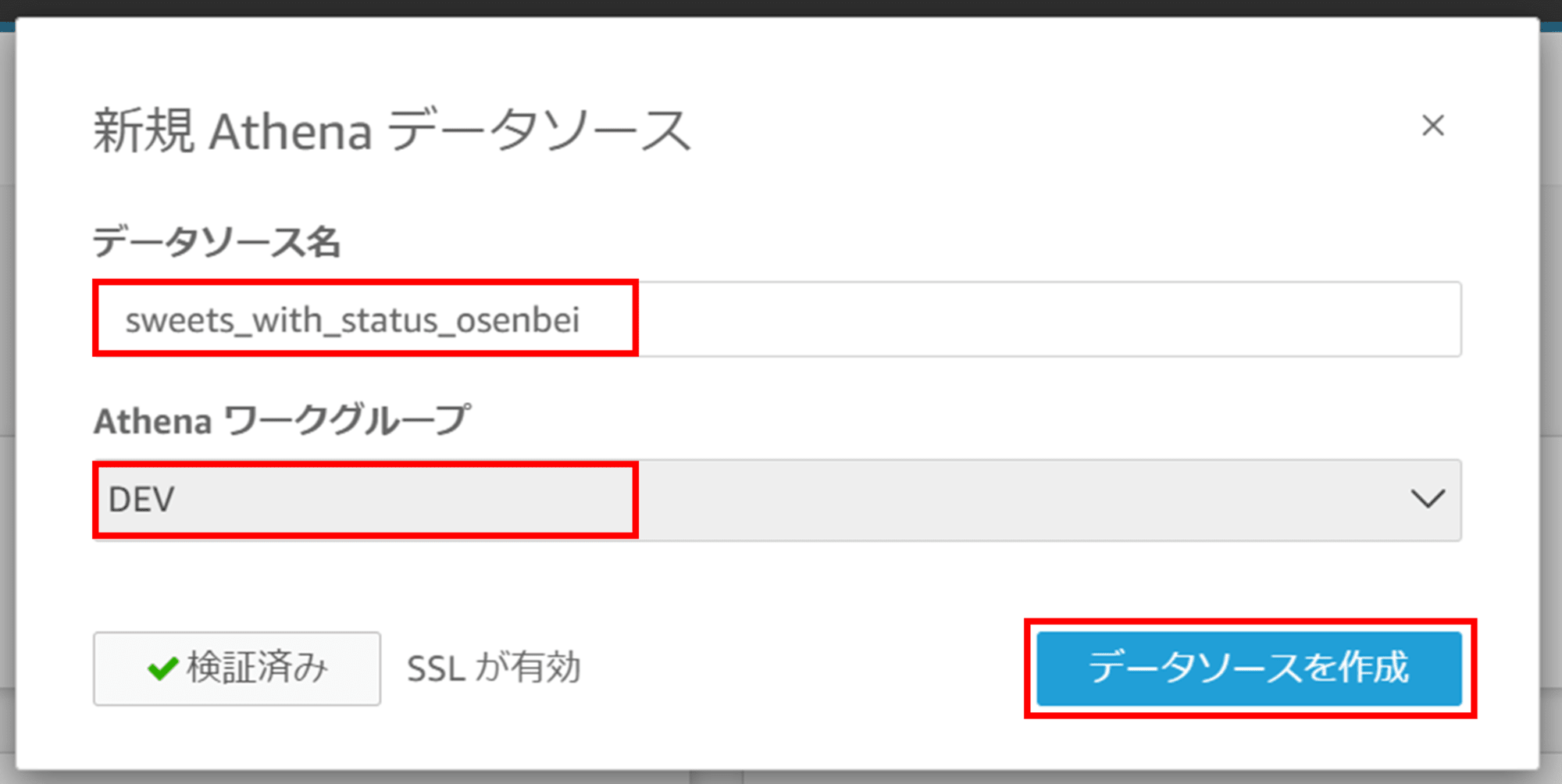
データソース名を指定しワークグループを選択します。データソースを作成します。
カスタム SQL を設定します。
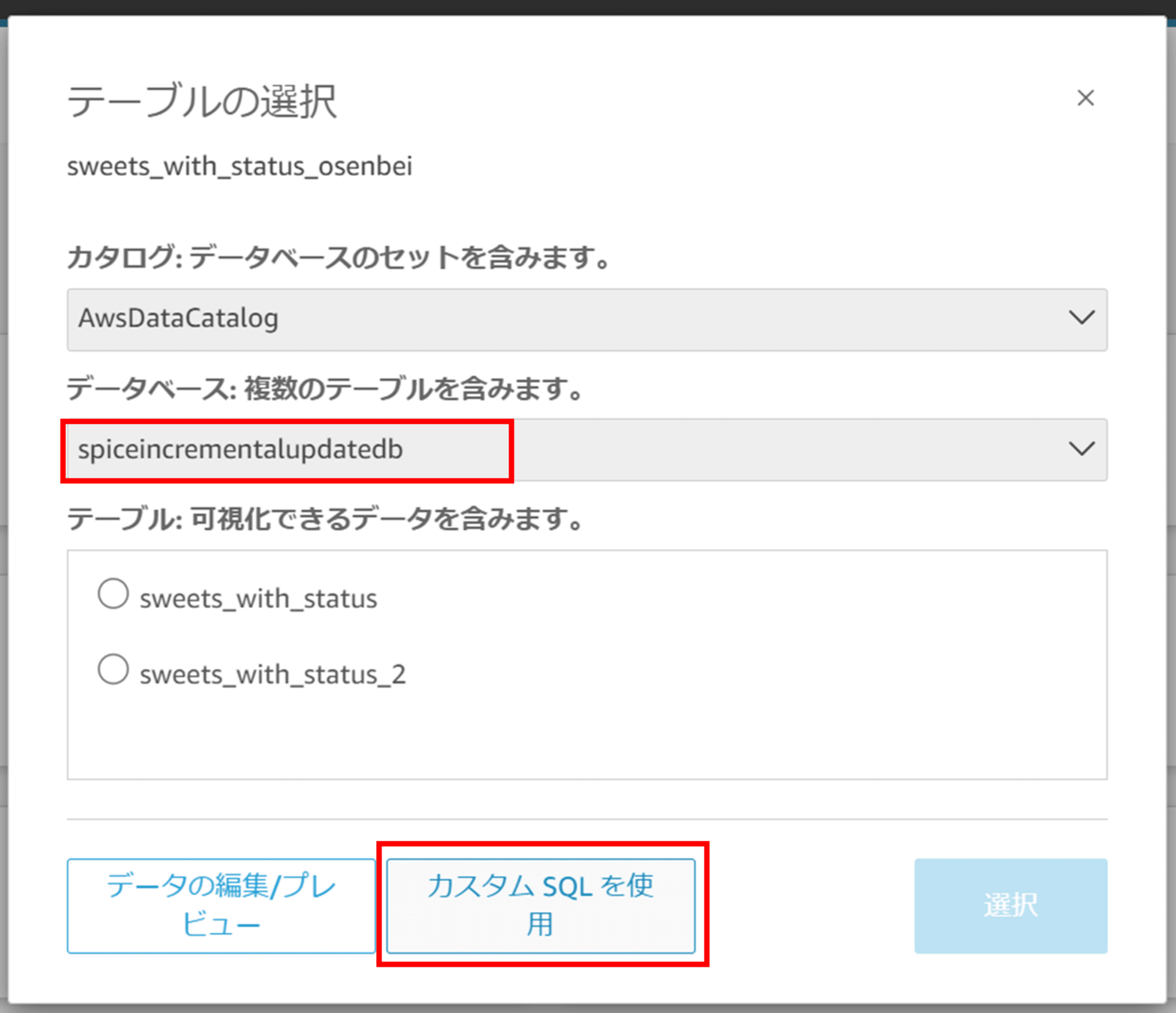
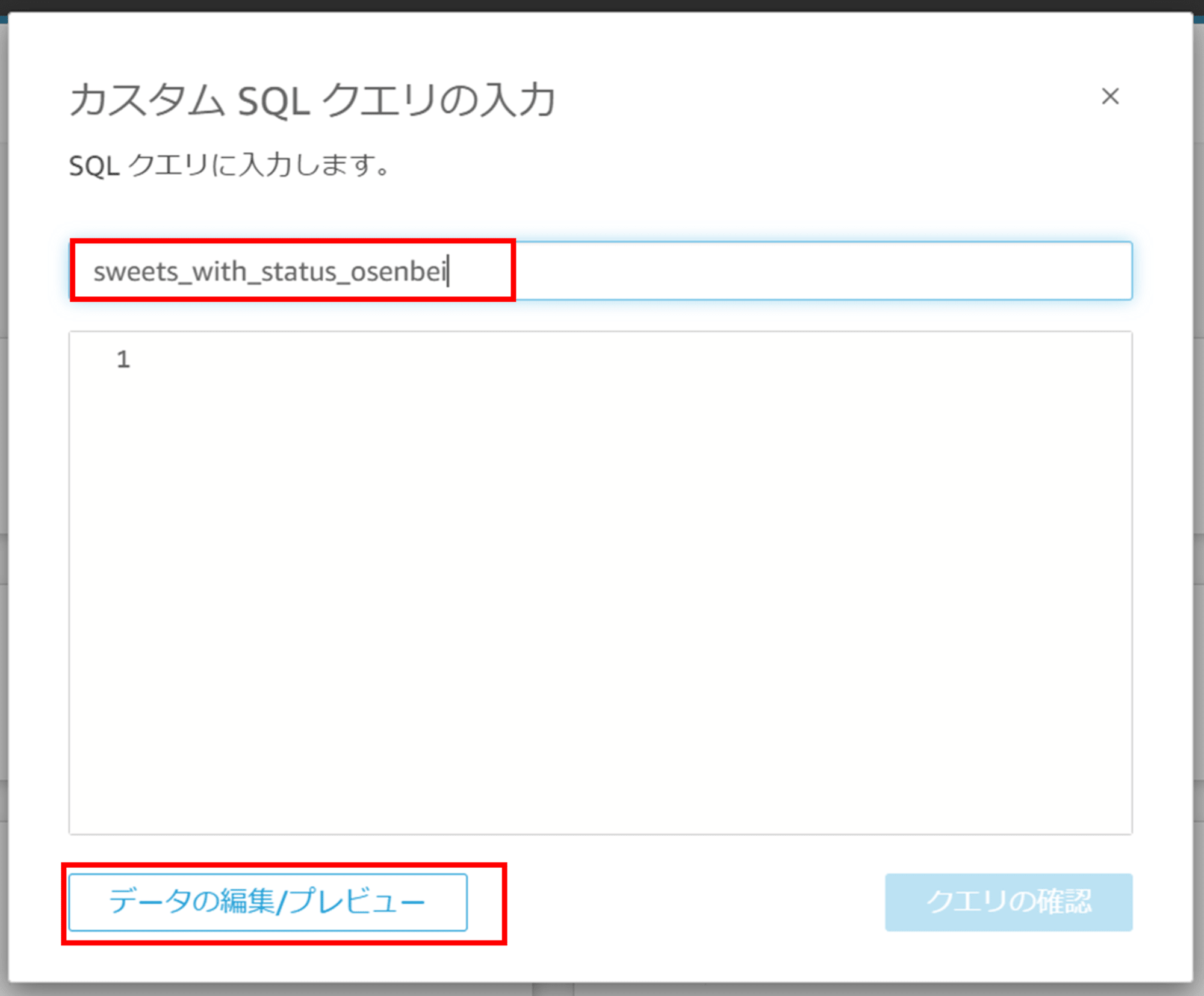
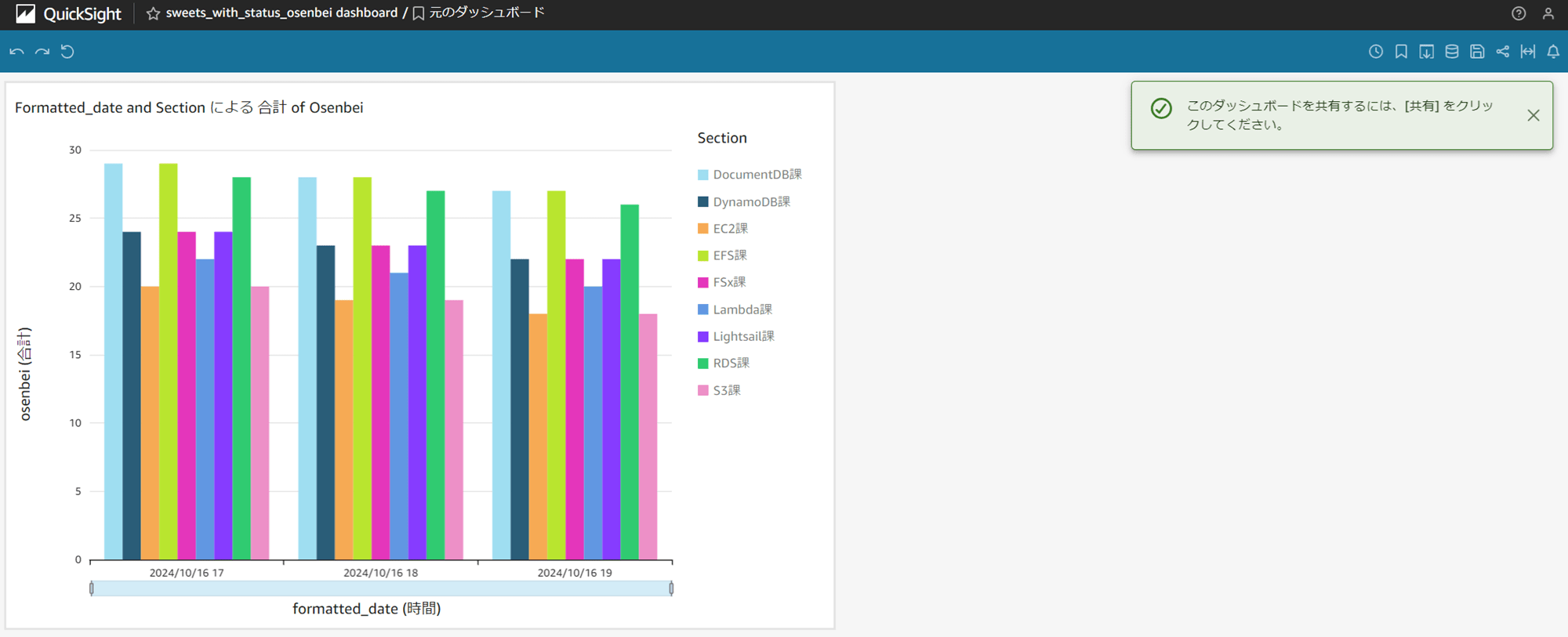
以下のようなカスタム SQL を作成しました。課ごとのおせんべいの枚数を取得するクエリです。
SELECT
date_parse(partition_date, '%Y/%m/%d/%H') AS formatted_date,
department,
section,
status,
osenbei
FROM
spiceincrementalupdatedb.sweets_with_status_2
GROUP BY
partition_date,
department,
section,
status,
osenbei
ORDER BY
formatted_date,
department,
section
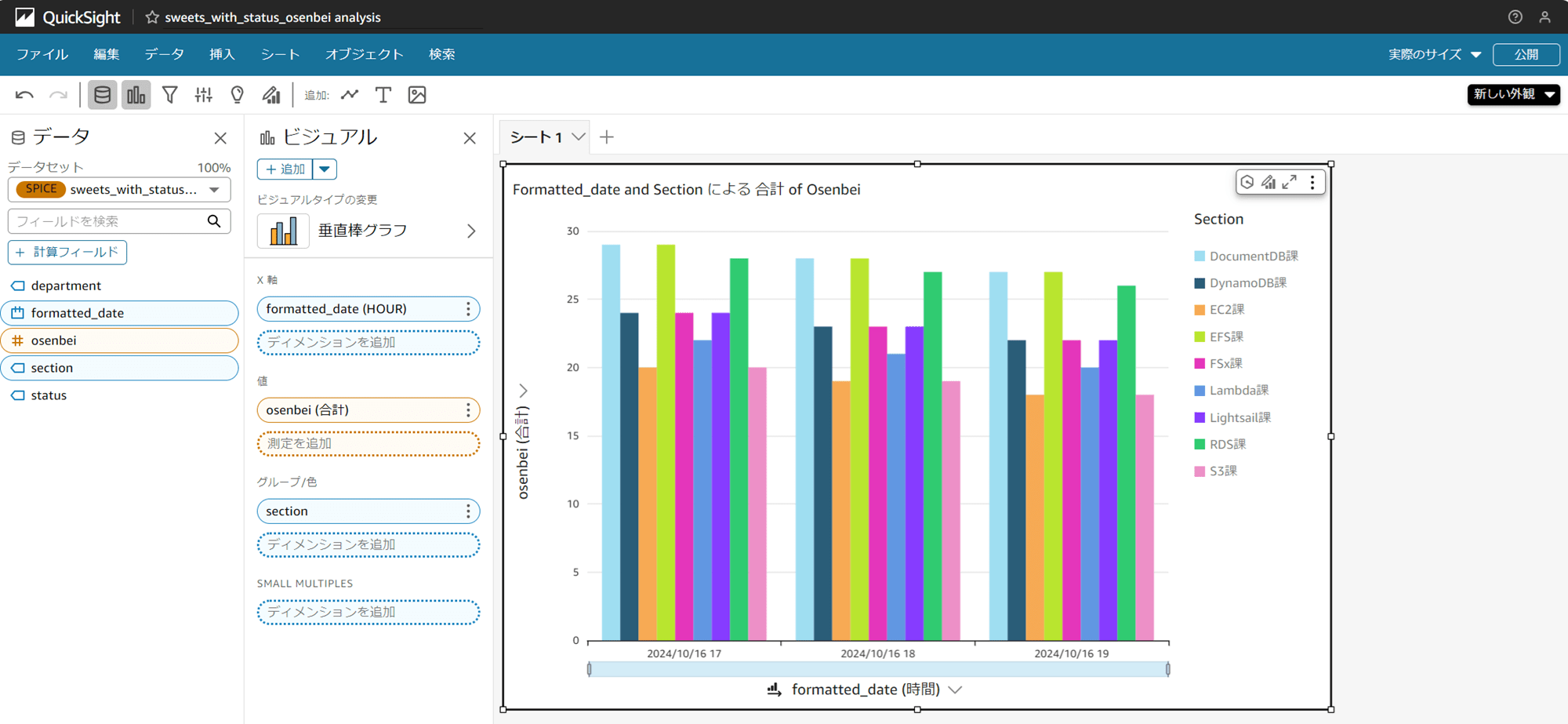
おせんべいの枚数を取得できました。日付は古い日付のデータのみ取得されています。
クエリモードを「SPICE」にして、「保存して視覚化」で分析も作成します。
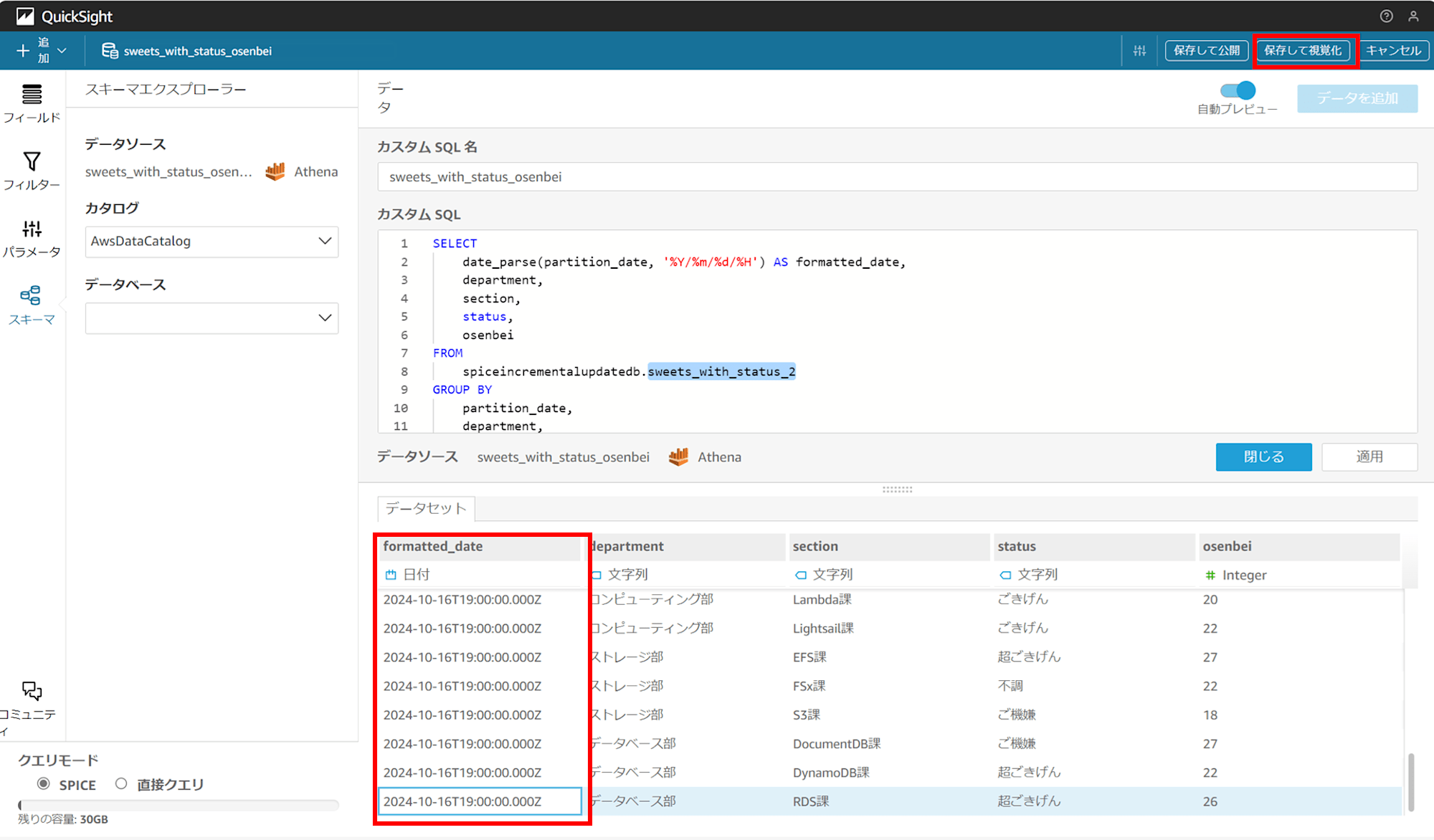
分析を作成したら「公開」でダッシュボードを作成します。
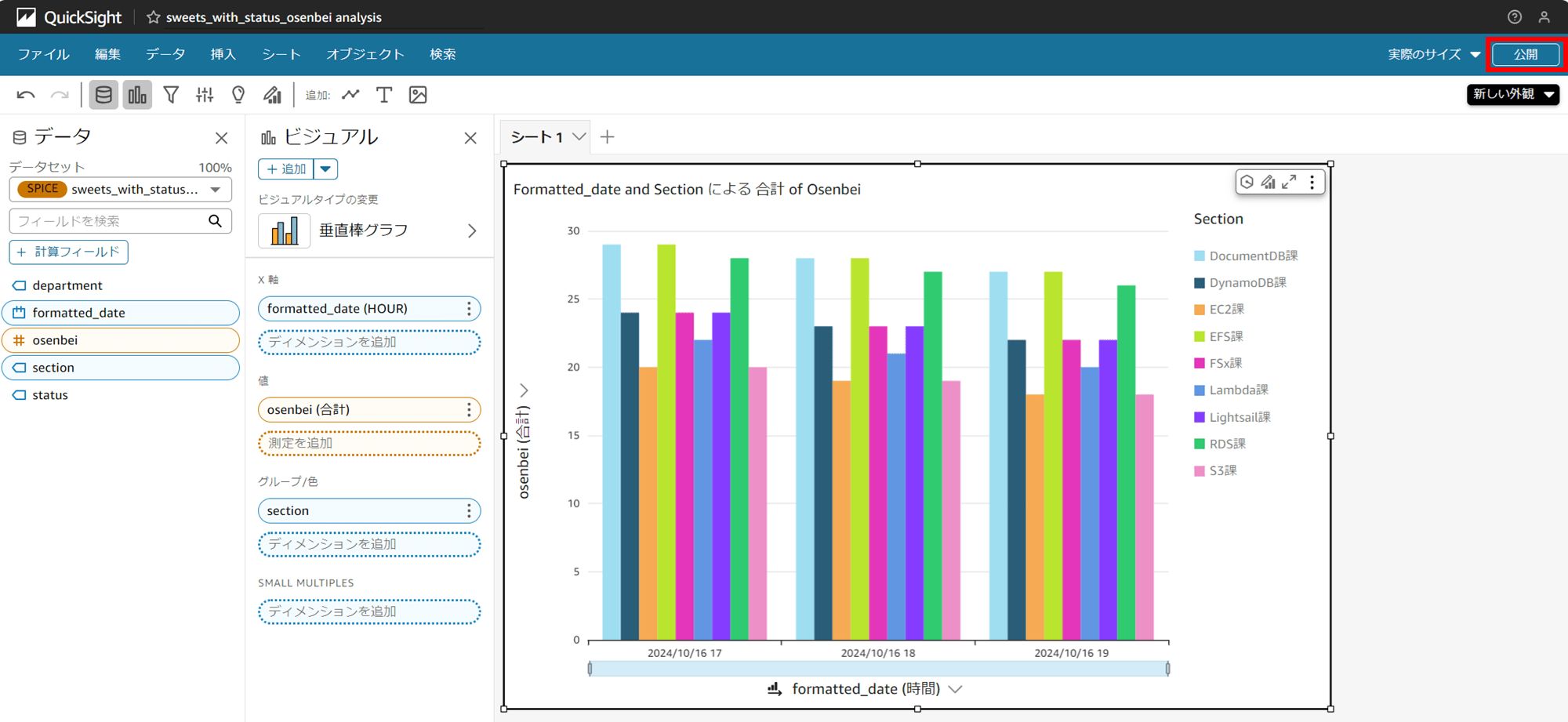
ダッシュボード名を付けます。
できました。
Athena テーブルの削除(NOW)
では、Athena 側で作成した sweets_with_status_2 テーブルを削除します。
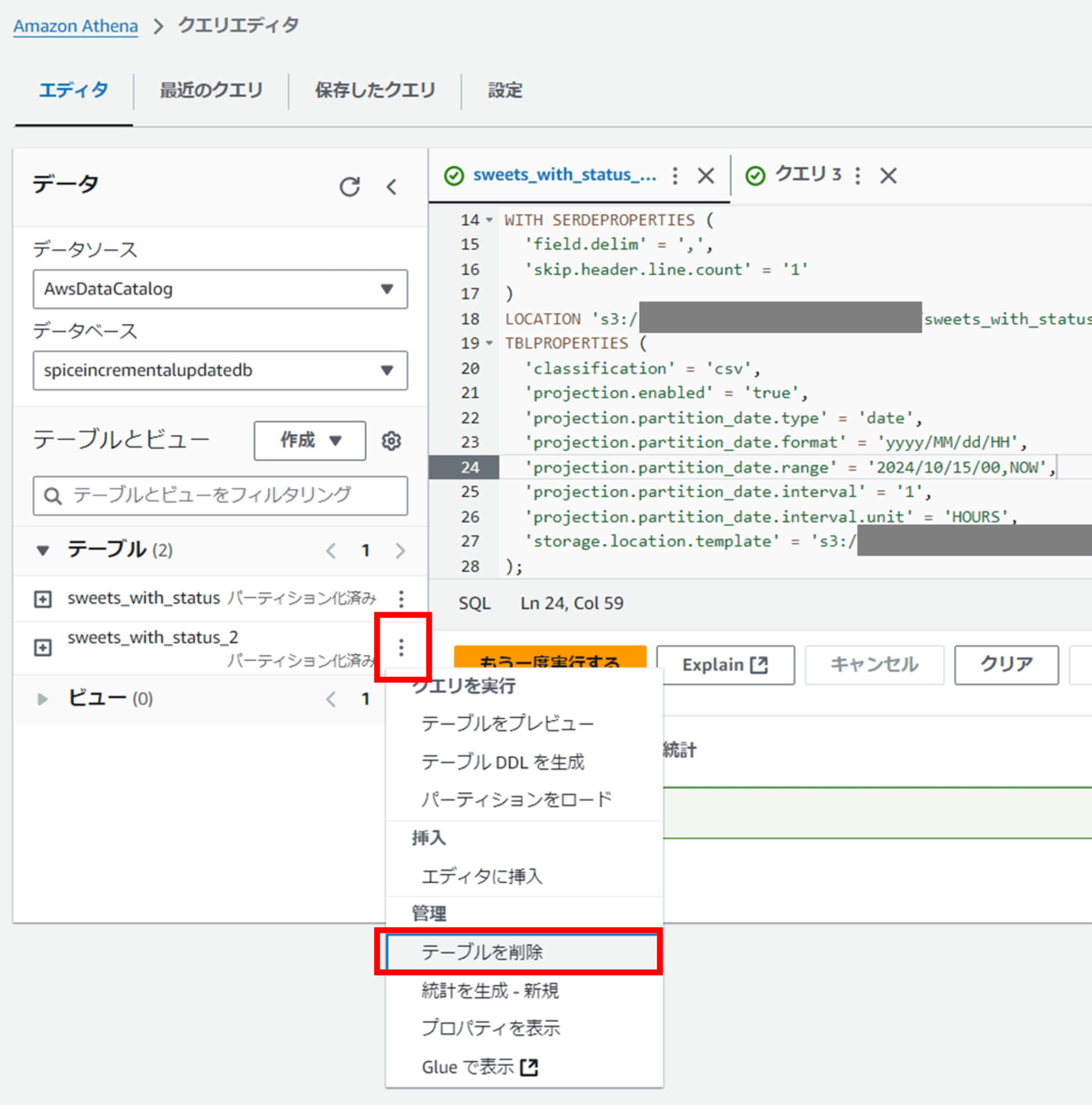
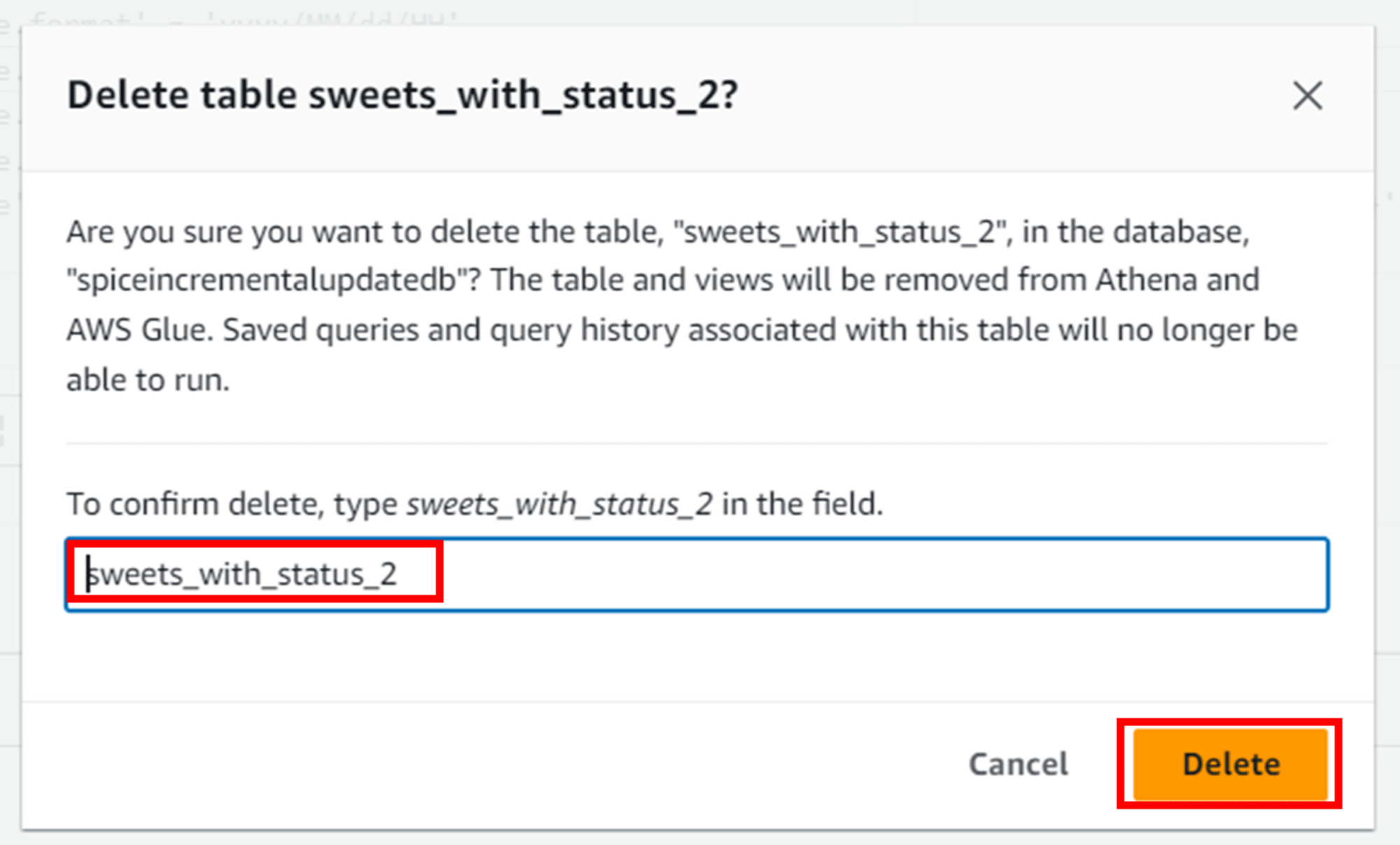
「テーブルを削除」からテーブル削除を進めると、以下のクエリが生成され実行されます。
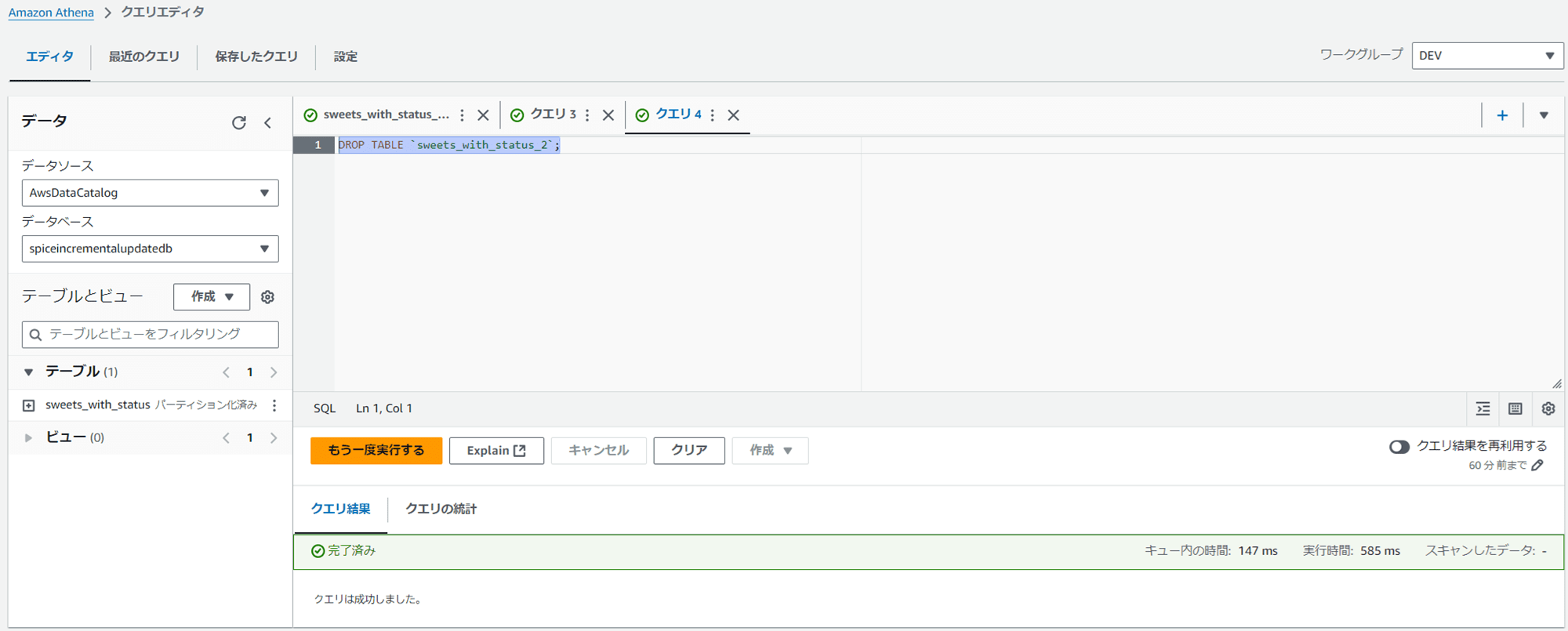
DROP TABLE `sweets_with_status_2`;
テーブルを削除しました。
ここで、QuickSight コンソールに移動してデータセット、分析、ダッシュボードの様子を確認します。
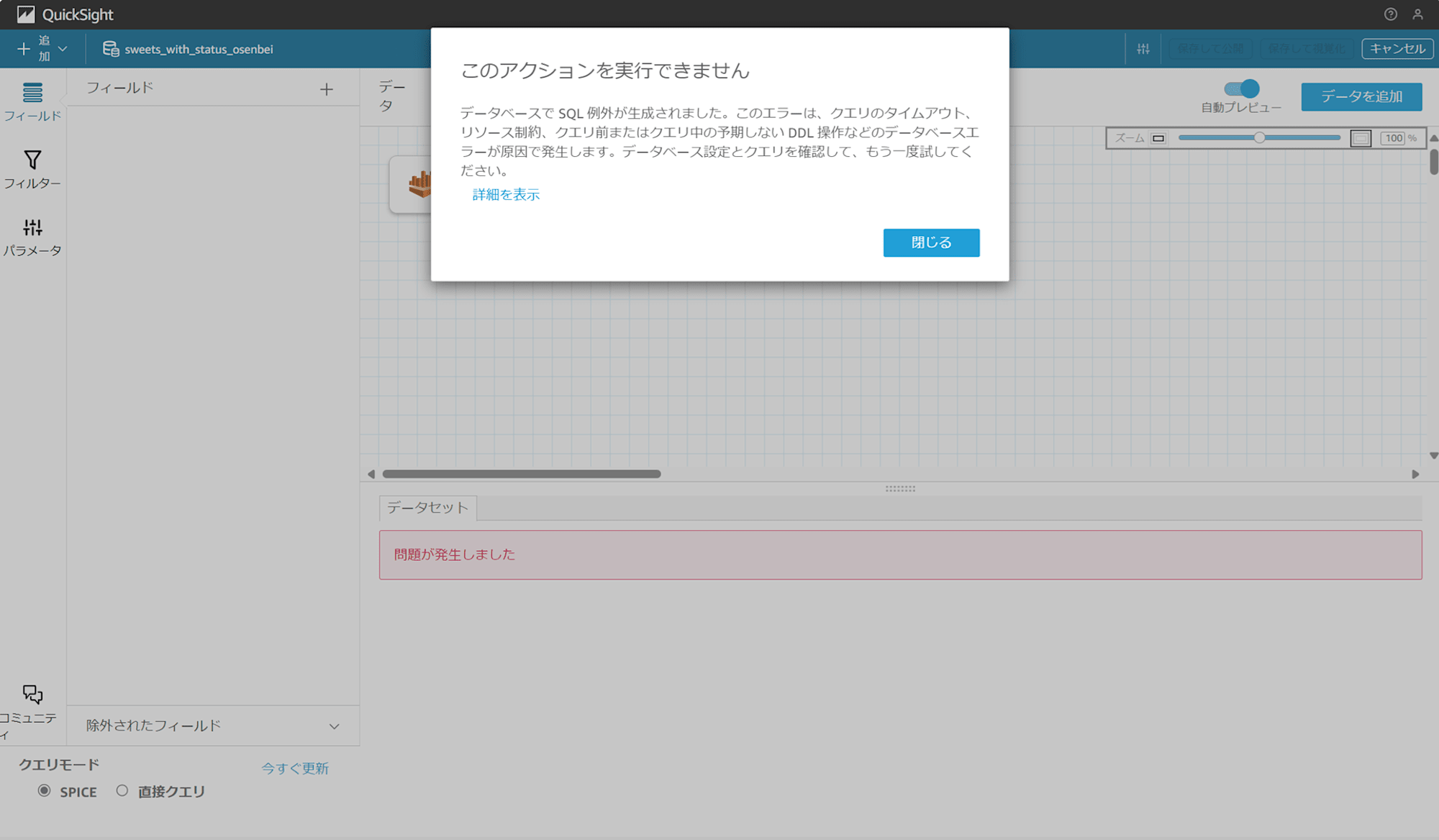
SPICE にデータを取り込んでいるので、分析とダッシュボードは影響ありません。
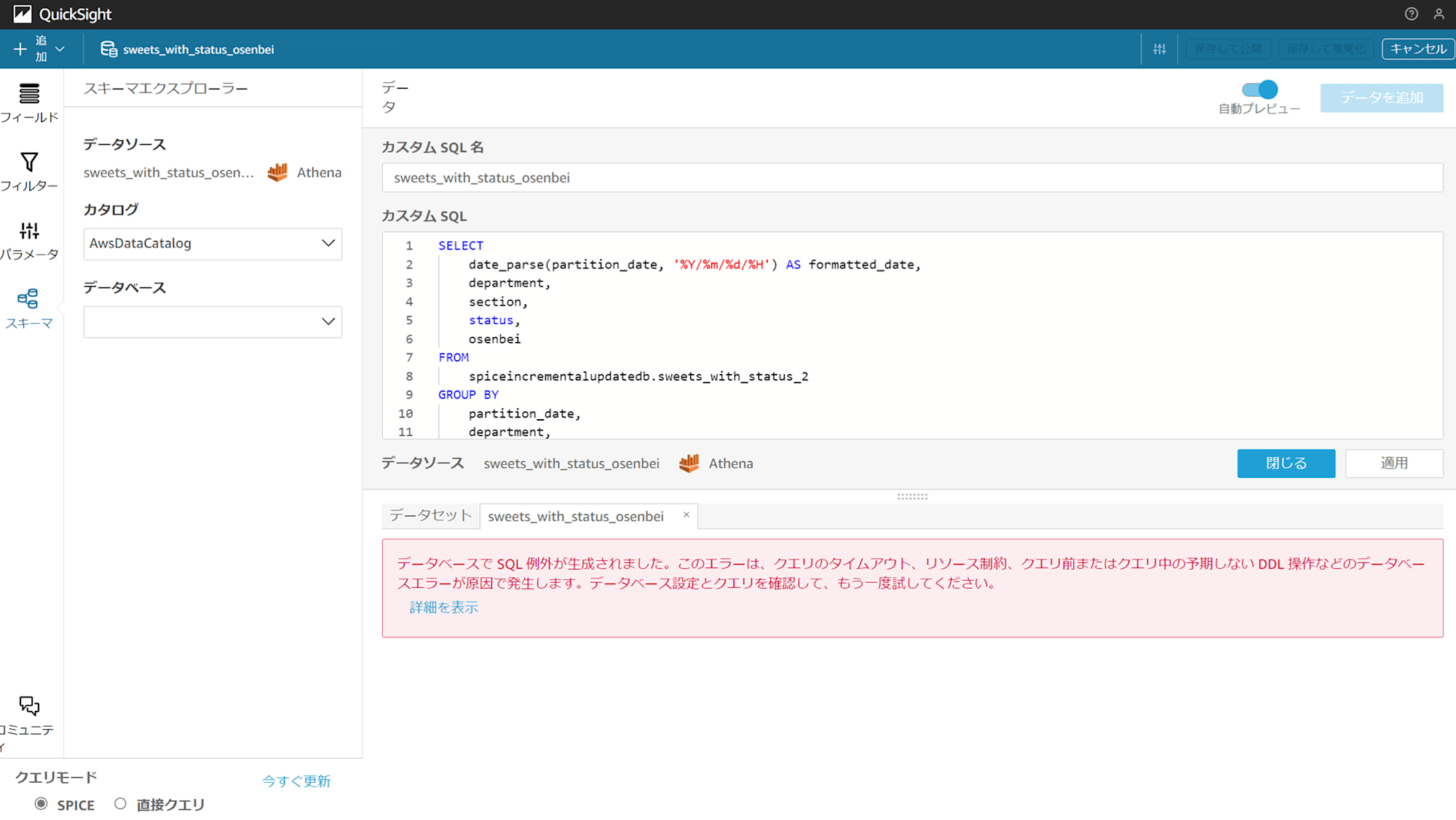
データセットの編集をクリックすると、エラーで Athena にデータを取りに行けなくなっているのが分かります。
エラー詳細
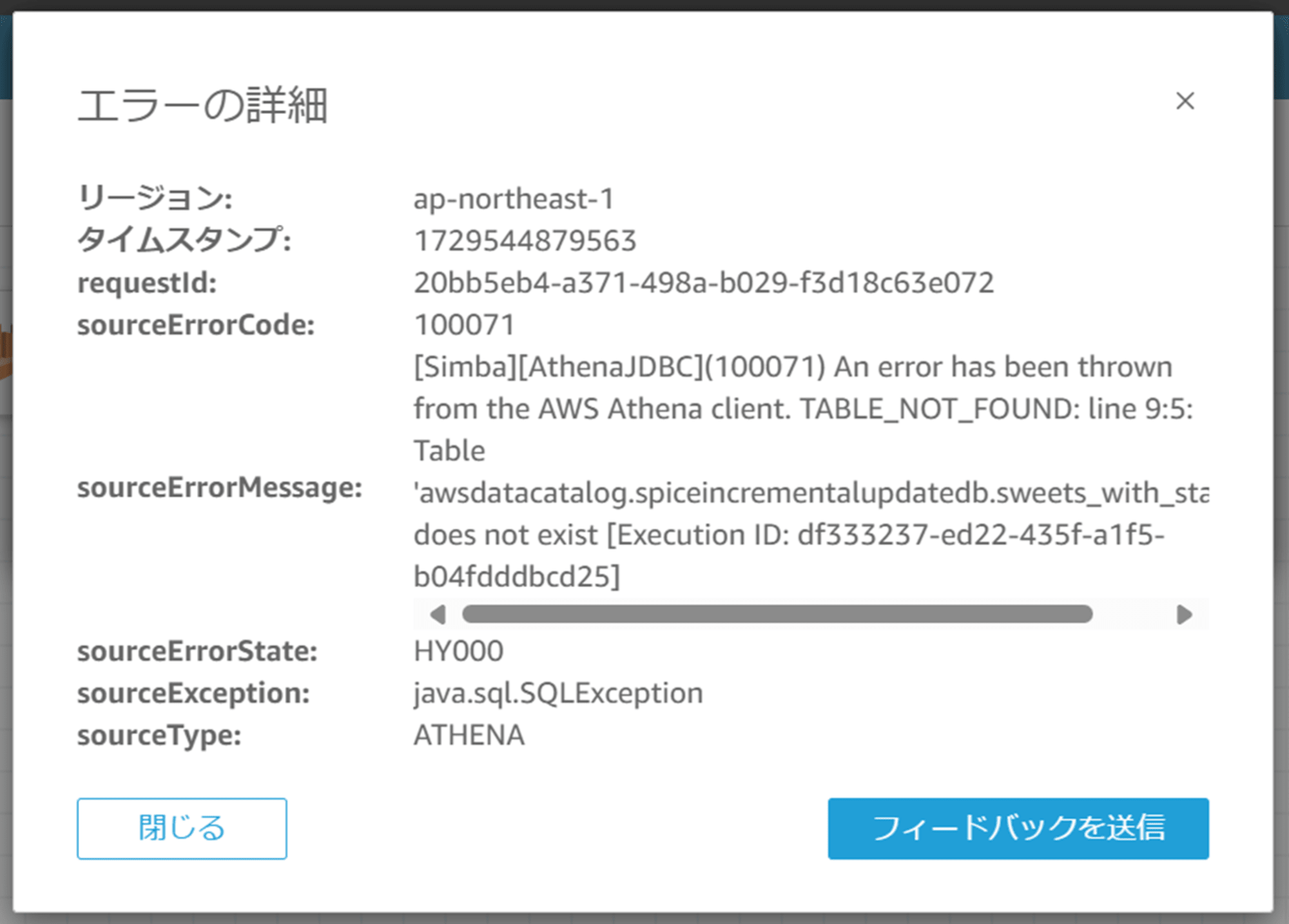
sourceErrorMessage:
[Simba][AthenaJDBC](100071) An error has been thrown from the AWS Athena client.
TABLE_NOT_FOUND: line 9:5: Table 'awsdatacatalog.spiceincrementalupdatedb.sweets_with_status_2' does not exist [Execution ID: xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx]
カスタム SQL も見てみます。
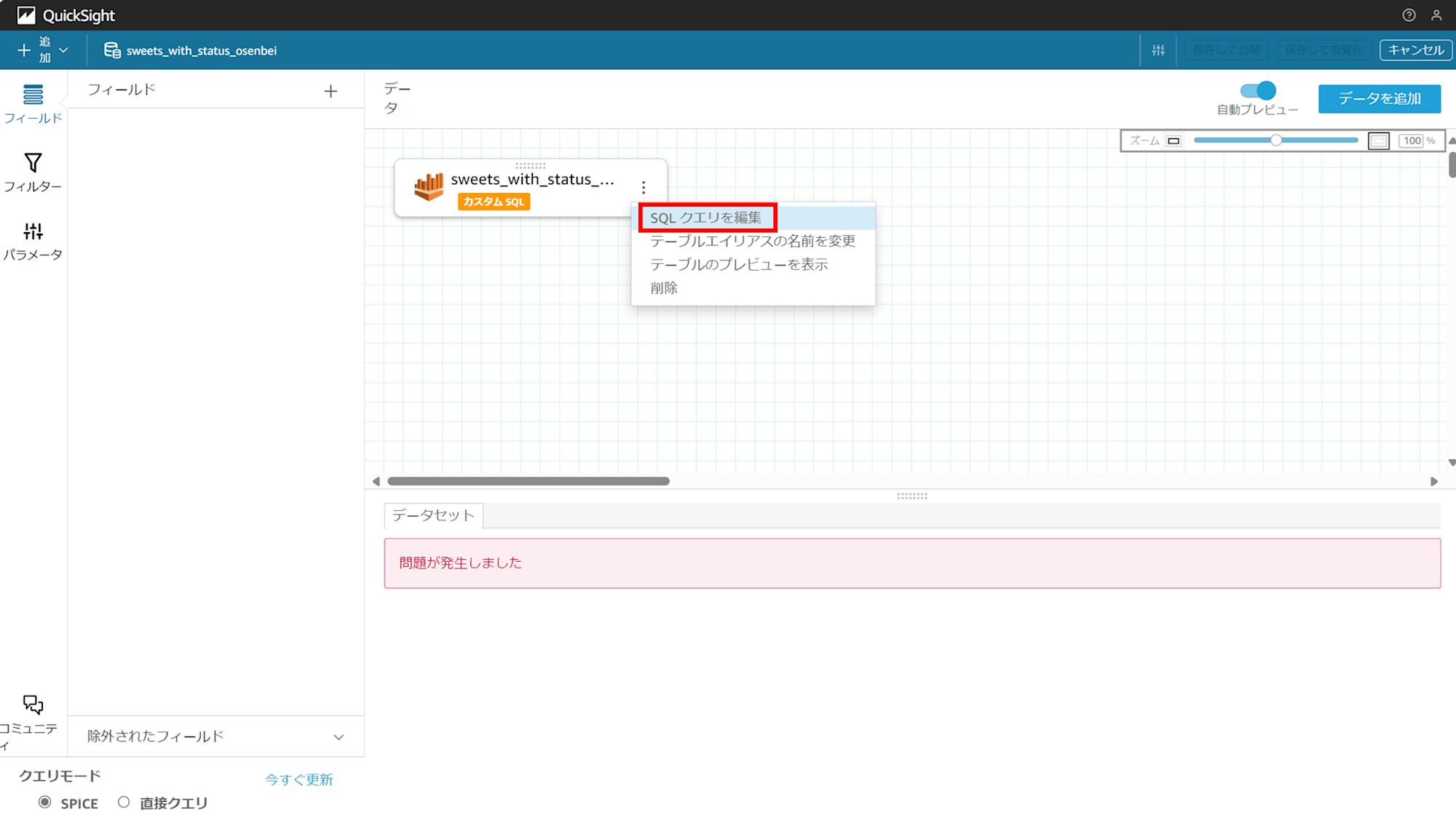
カスタム SQL は表示されますが、やはりデータは Athena に取りに行けなくなっています。
Athena テーブルの再作成(NOW+9HOURS)
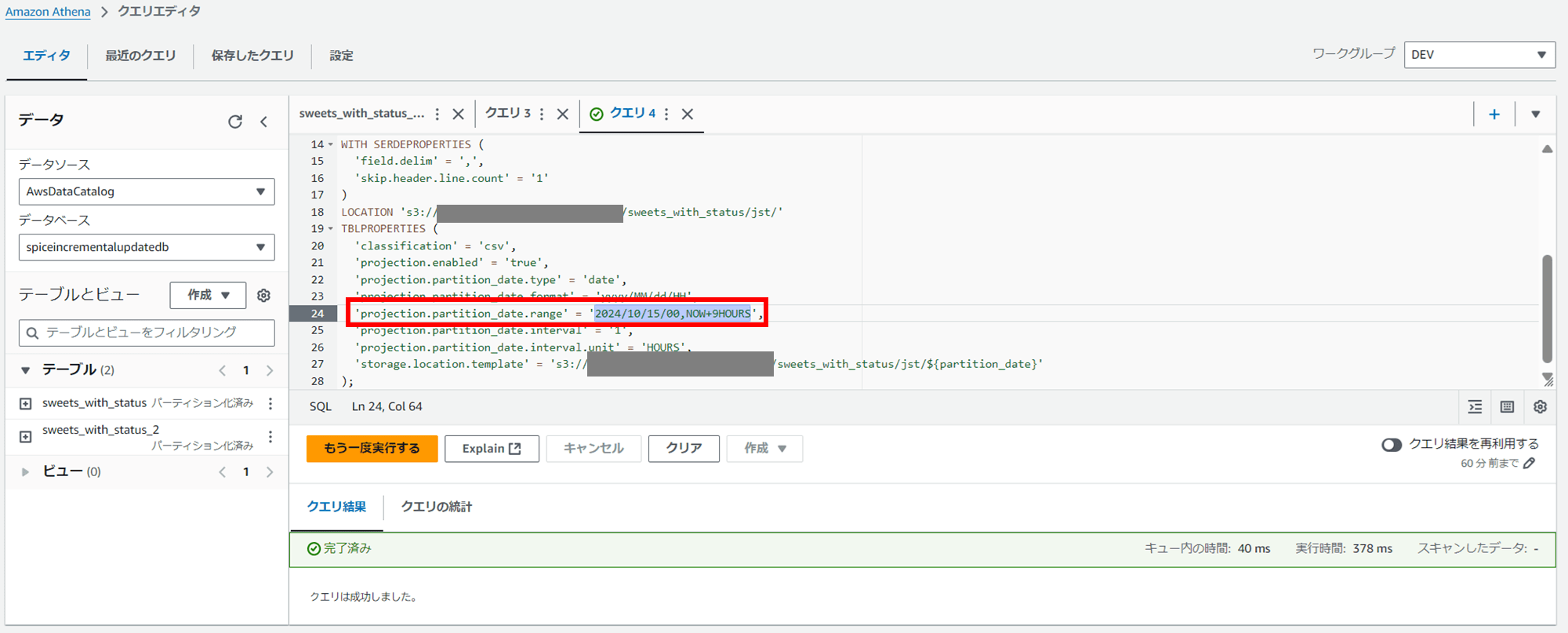
先ほどと同じ名前の Athena テーブル sweets_with_status_2 を、今度は projection.partition_date.range の終了日 NOW+9HOURS で再作成します。
Athena テーブル sweets_with_status_2 再作成用のクエリは以下です。
CREATE EXTERNAL TABLE IF NOT EXISTS `spiceincrementalupdatedb`.`sweets_with_status_2` (
`datetime` timestamp,
`department` string,
`section` string,
`status` string,
`chocolate` int,
`donut` int,
`osenbei` int
)
PARTITIONED BY (
`partition_date` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim' = ',',
'skip.header.line.count' = '1'
)
LOCATION 's3://<S3 バケット名>/sweets_with_status/jst/'
TBLPROPERTIES (
'classification' = 'csv',
'projection.enabled' = 'true',
'projection.partition_date.type' = 'date',
'projection.partition_date.format' = 'yyyy/MM/dd/HH',
'projection.partition_date.range' = '2024/10/15/00,NOW+9HOURS',
'projection.partition_date.interval' = '1',
'projection.partition_date.interval.unit' = 'HOURS',
'storage.location.template' = 's3://<S3 バケット名>/sweets_with_status/jst/${partition_date}'
);
テーブルを再作成しました。
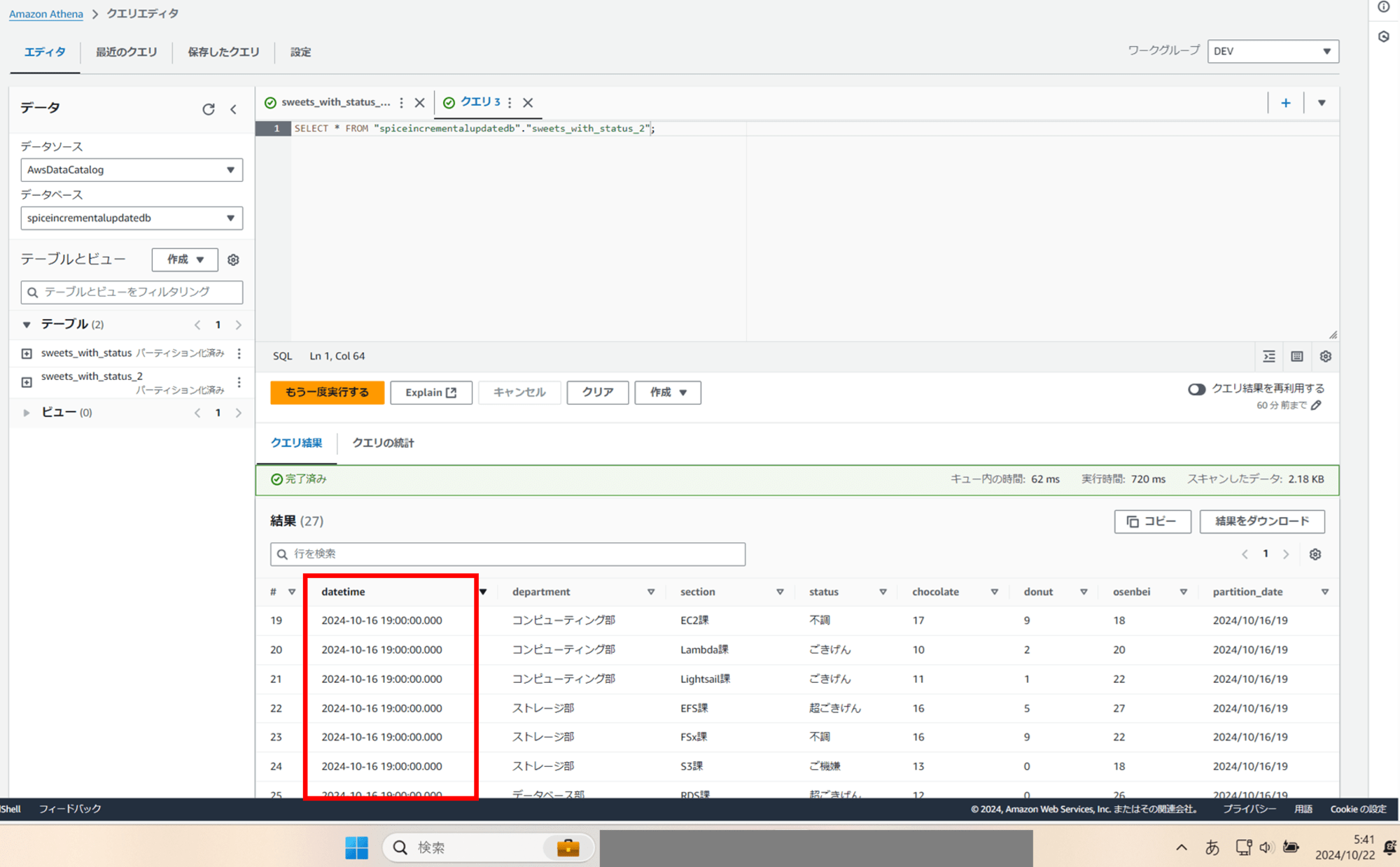
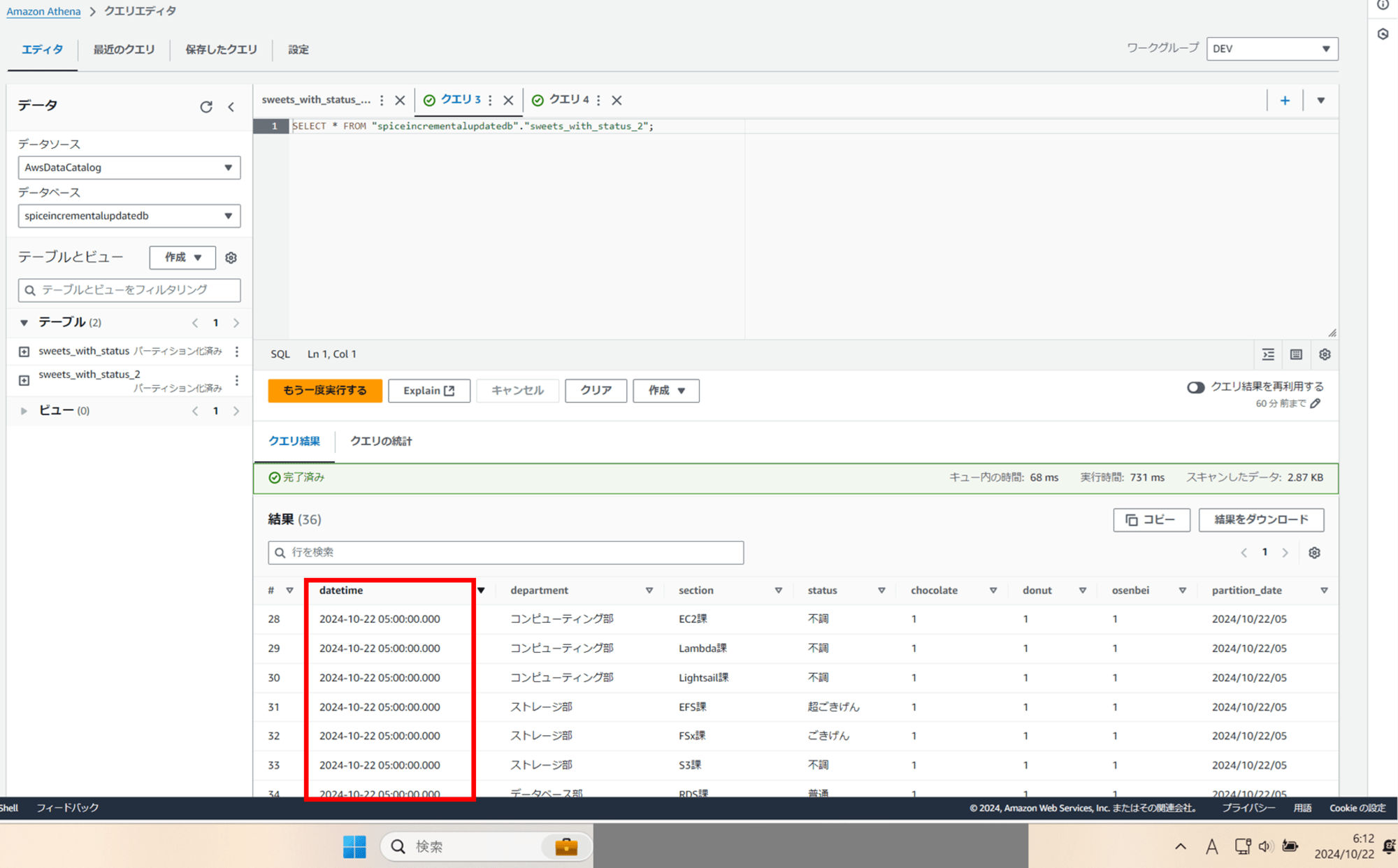
S3 からデータを取得できるか試します。
SELECT * FROM "spiceincrementalupdatedb"."sweets_with_status_2";
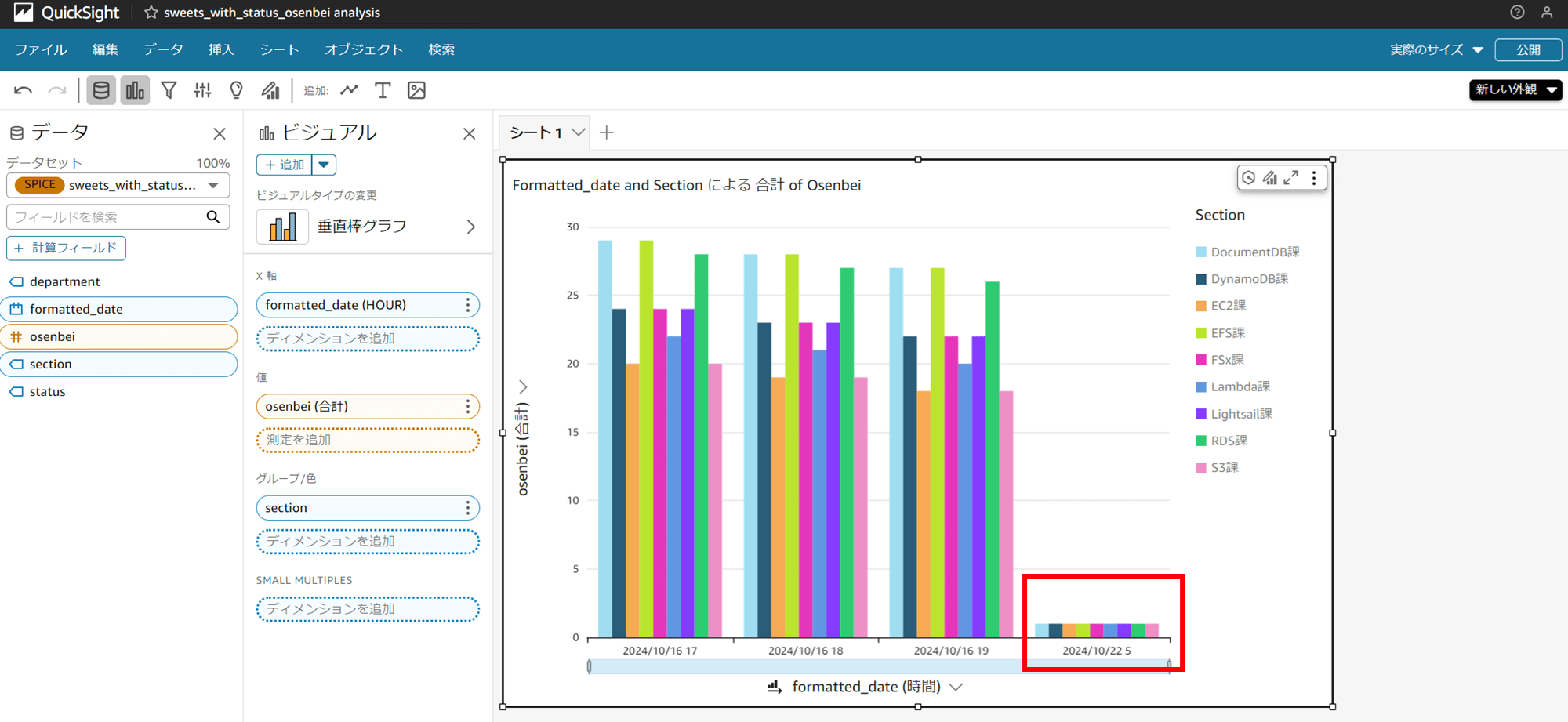
できました。今度は日本時間最新時間の 2024/10/22 05:00 時点のデータが取得できています。
QuickSight データセットの編集画面に戻り、ブラウザを再読み込みすると……データが表示されました!こちらも、日本時間最新時間の 2024/10/22 05:00 時点のデータが取得できています。
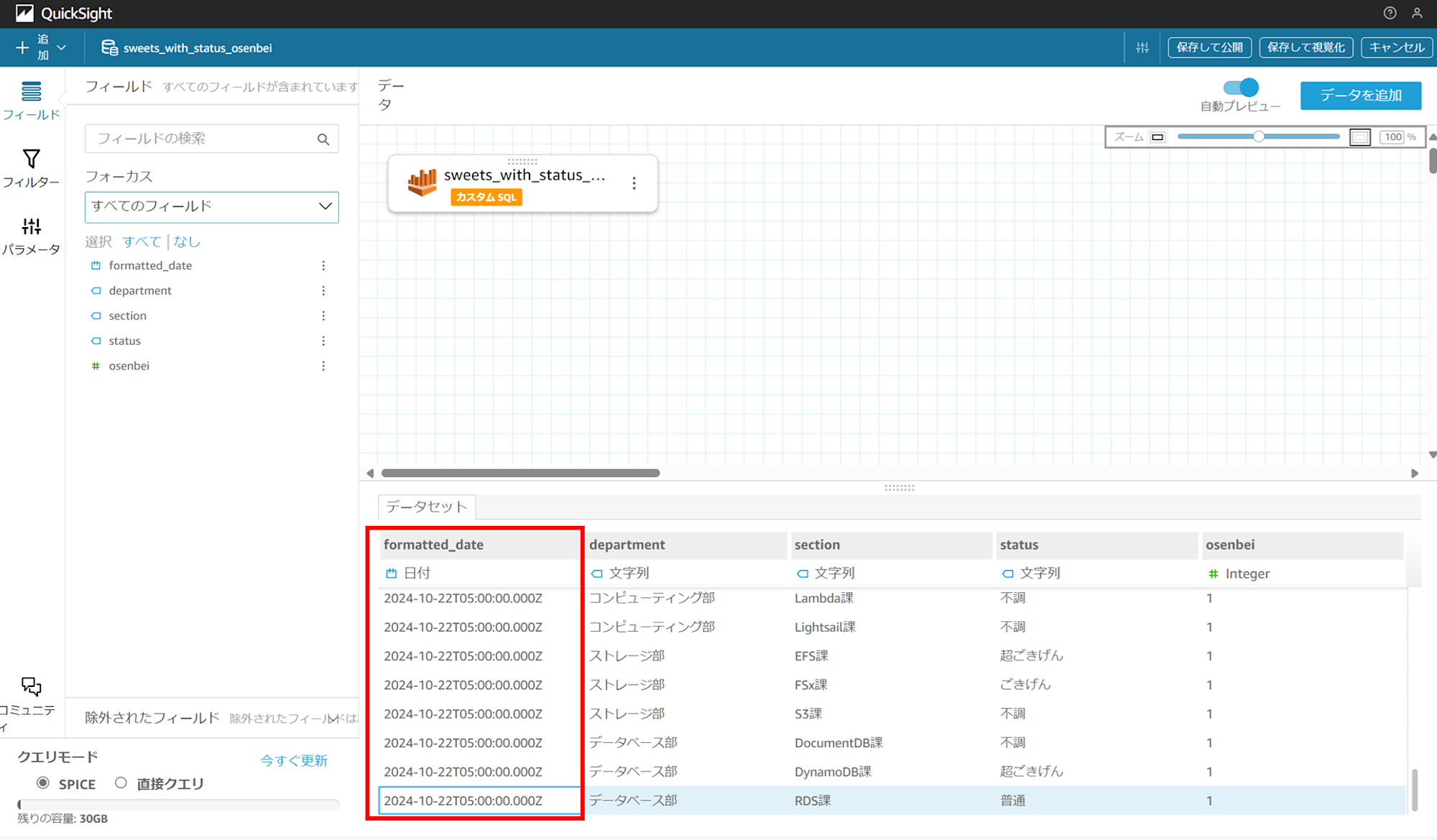
ここまでで QuickSight データセットが Athena 経由で S3 のデータを再取得できるようになりました。
分析とダッシュボードに日本時間の最新データを反映させるには、SPICE に読み込む必要があります。
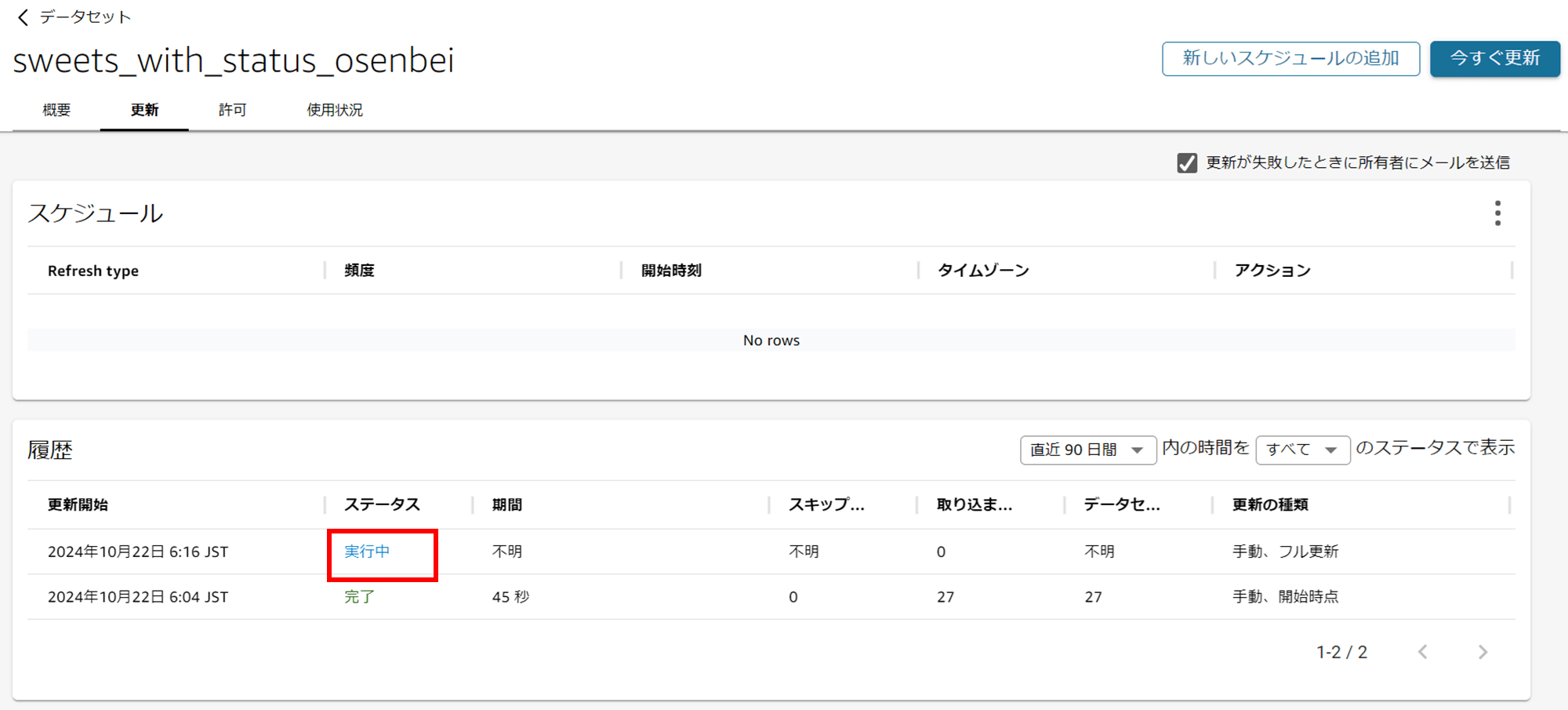
データセットの詳細画面で「更新」タブを開き、「今すぐ更新」をクリックします。
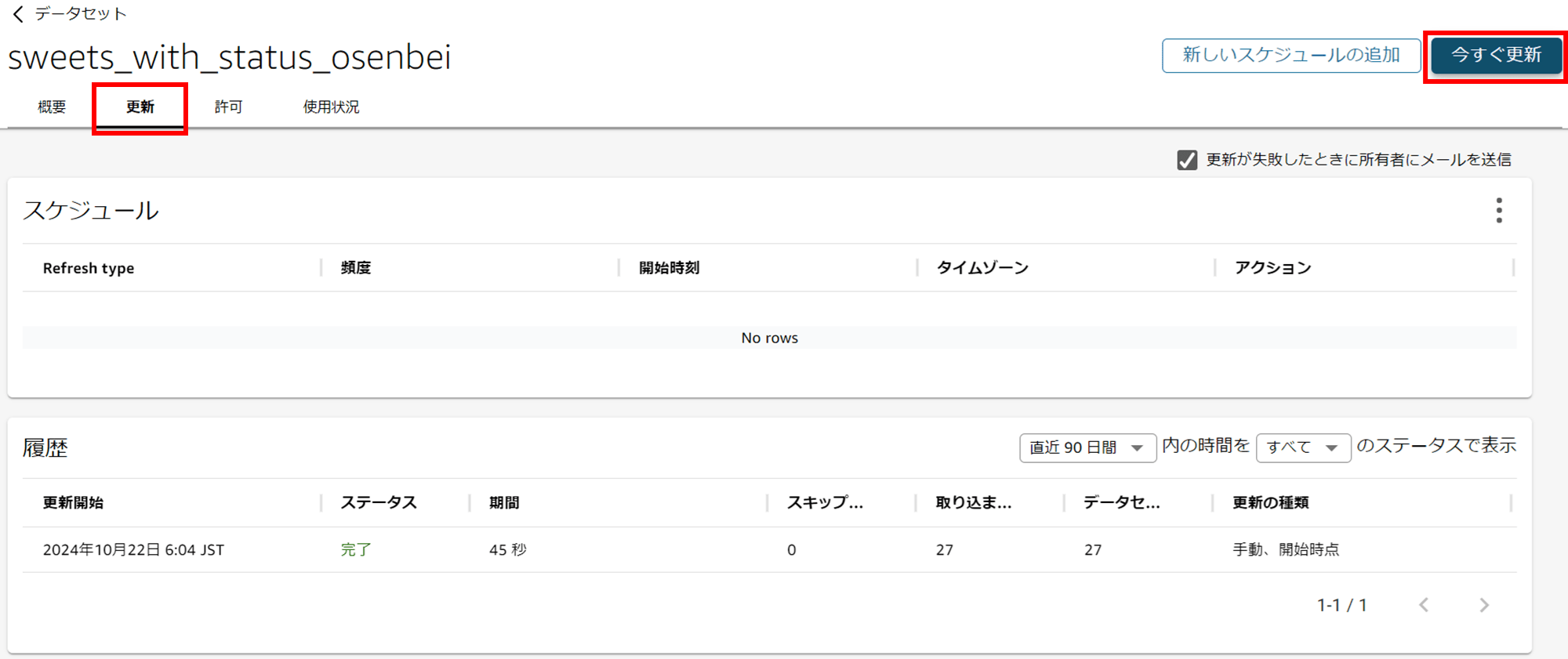
フル更新を選択して SPICE のデータを更新します。

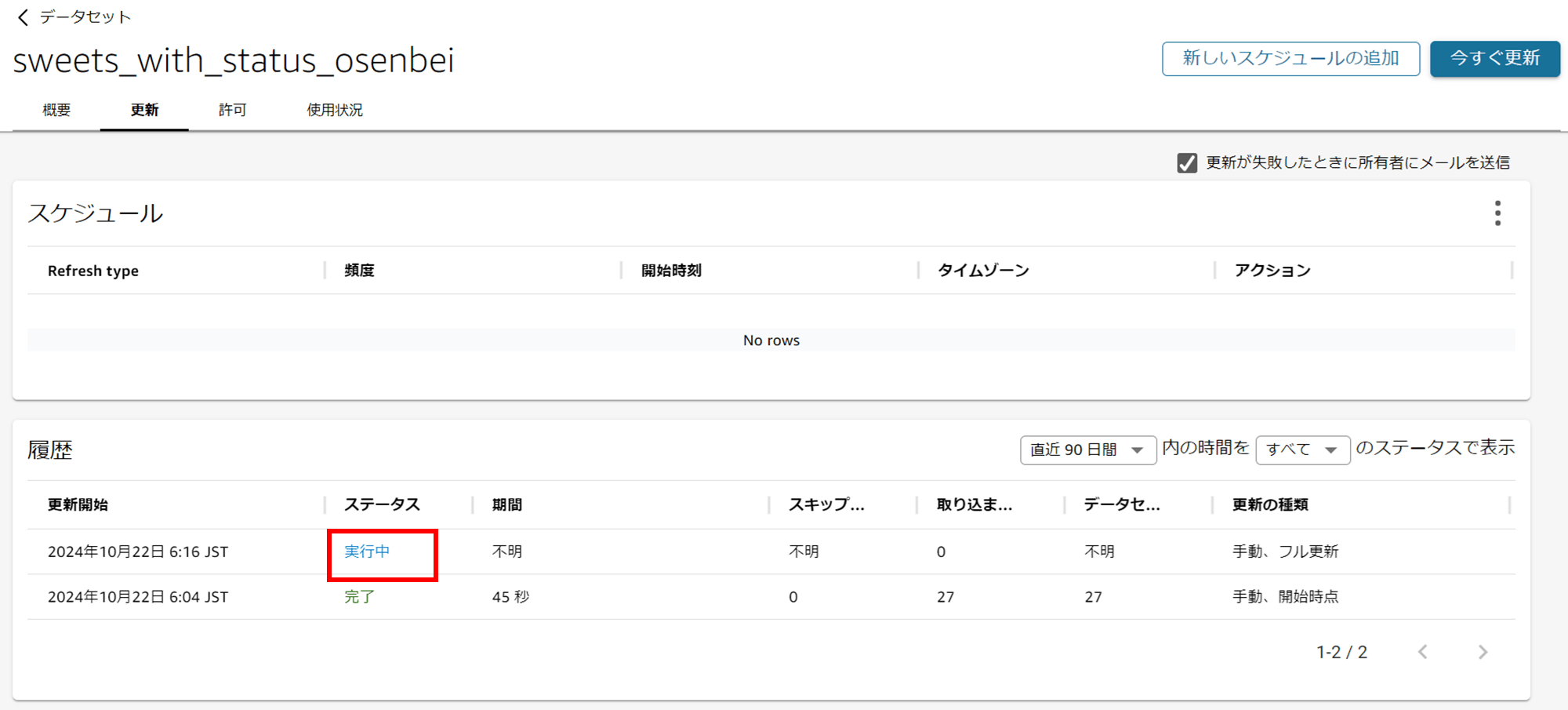
ステータスが「実行中」→「完了」になれば OK です。
分析にも最新日付のおせんべいの枚数が表示されました!
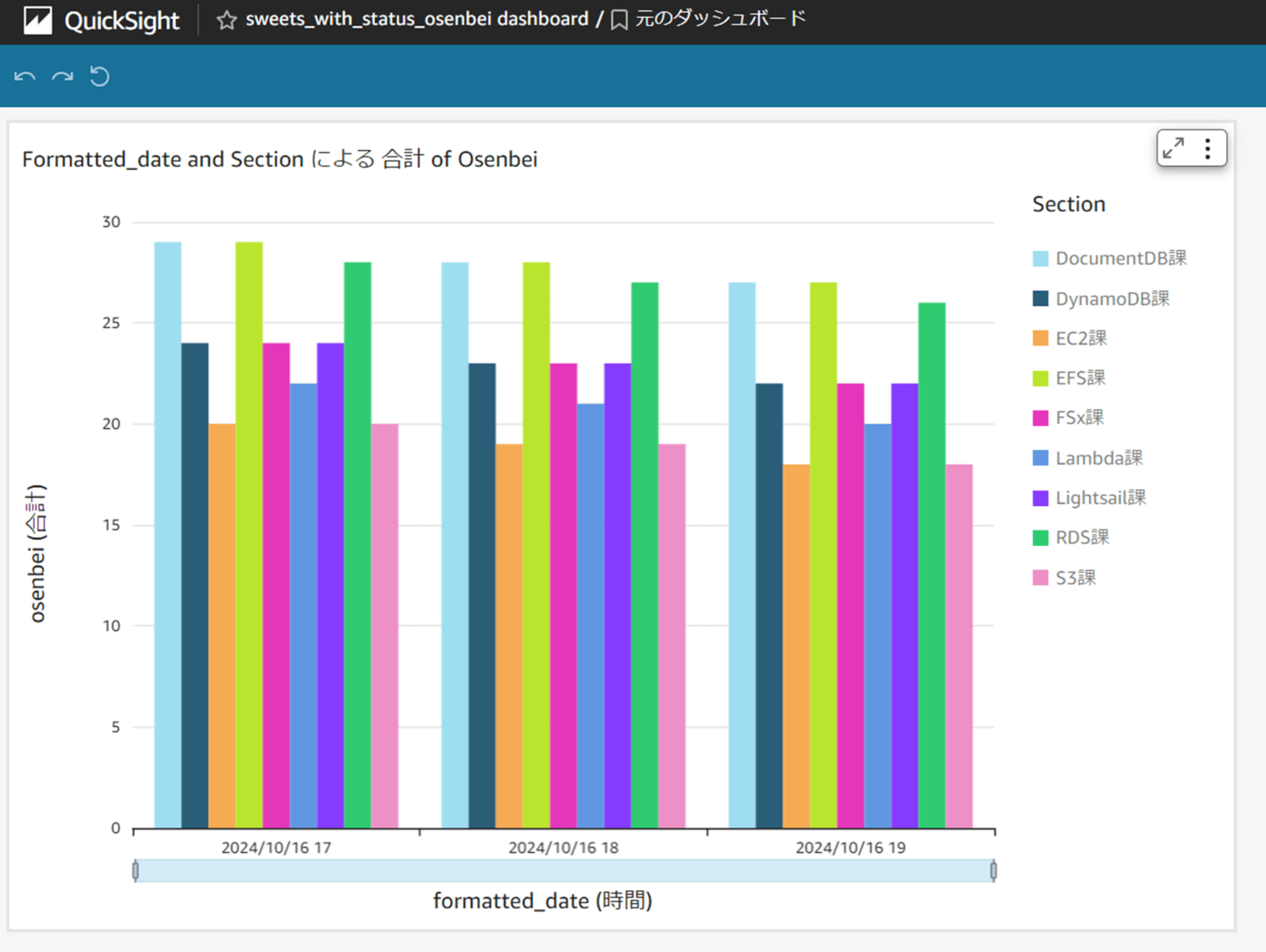
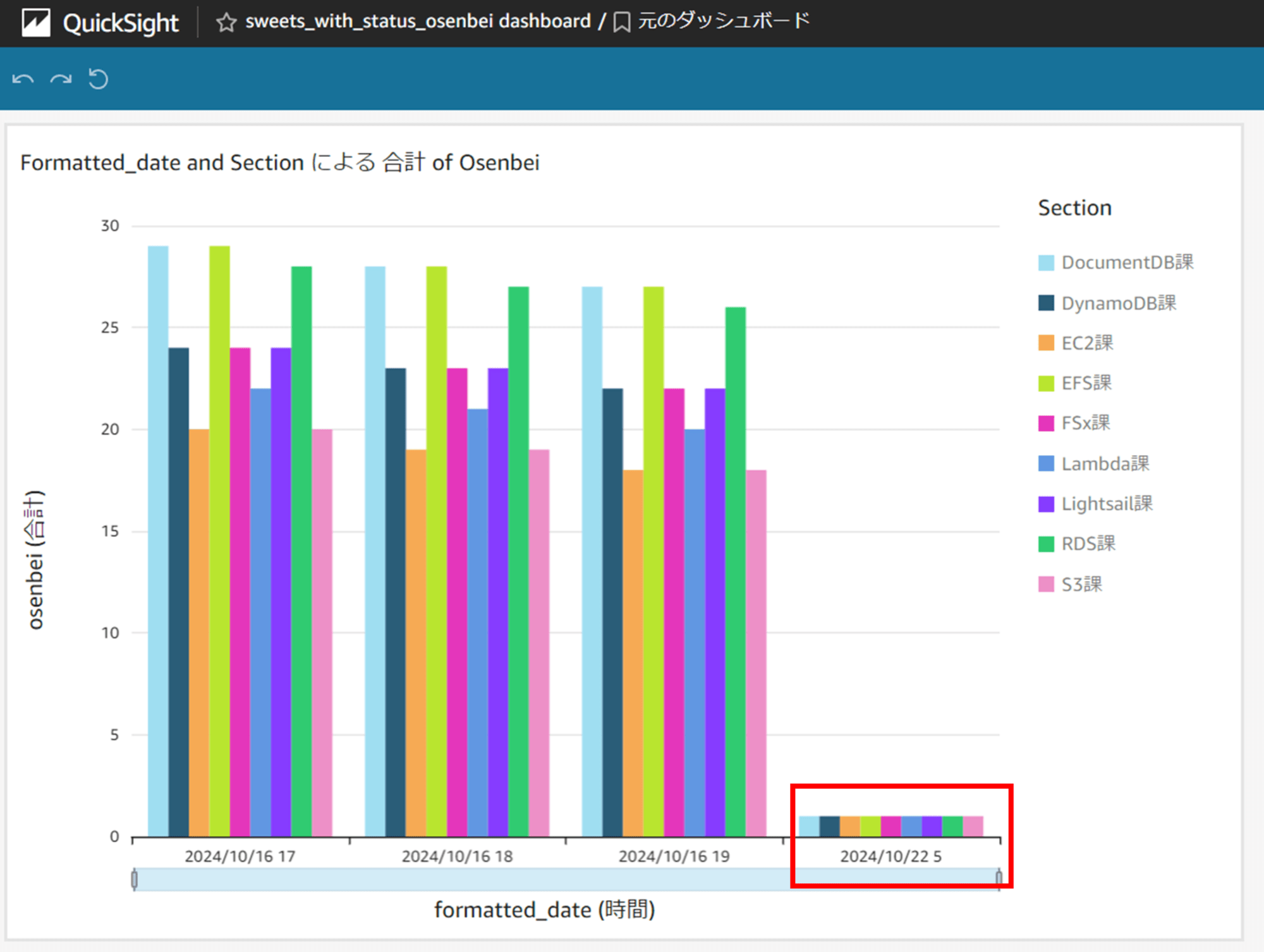
ダッシュボードにも反映されました。
おわりに
同じ名前の Athena テーブルを再作成しても、テーブルの構造が同じなら問題なくデータが持ってこられることが確認できて良かったです。
Athena のテーブルはデータの実態を持たない View のようなもの(データの実態は S3 にある)なので再作成しても大丈夫であろうことは大先輩に確認したのですが、念のため挙動も確認しました。
どなたかのお役に立てば幸いです。
