
특정 지표에 따라 Aurora RDS 인스턴스 승격(페일오버)하기

안녕하세요 클래스메소드의 이수재입니다.
이번에 Aurora 클러스터의 인스턴스를 CPU 사용률에 따라 인스턴스를 승격시키는 방법을 조사할 일이 있었습니다.
해당 내용을 조사하며 생각했던 내용이나 설정 방법 등을 공유하려 합니다.
결론부터
cloudwatch 에서 알람을 설정하고 failover-db-cluster 라는 API를 실행시키는 람다 함수를 싱행하여 페일오버가 가능합니다.
그림으로 보면 다음과 같습니다.

Aurora의 페일오버
우선 Aurora는 최대 15개의 읽기 전용 Aurora 복제본(리더 인스턴스)을 생성할 수 있습니다.
리더 인스턴스란 SELECT 쿼리를 처리할 수 있는 인스턴스입니다.
읽기 작업이 많은 워크 플로우에서 일부 작업을 리더 인스턴스에서 처리하여 기본 인스턴스의 부하를 낮출 수 있습니다.
리더 인스턴스는 단순히 읽기 작업 뿐만 아니라 기본 인스턴스(라이터 인스턴스)에 문제가 발생하면 리더 인스턴스 중 하나가 기본 인스턴스로 승격되어 클러스터의 내구성도 향상시킬 수 있습니다.
각 복제본에 우선 순위를 지정하여 장애 이후 기본 인스턴스로 승격할 Aurora 복제본 순서를 지정하는 것도 가능합니다.
둘 이상의 Aurora 복제본이 동일한 우선 순위를 공유하면 Amazon RDS는 크기가 가장 큰 복제본을 승격시킵니다.
만약 DB 클러스터에 Aurora 복제본이 포함되어 있지 않으면 기본 인스턴스가 실패 이벤트 중에 동일한 AZ에 다시 생성하게 됩니다.
페일 오버는 콘솔과 API 둘 다 가능합니다.
공식 문서에서는 수동으로 페일 오버하는 방법에 대해 설명되어 있습니다.
설정 방법
CPU 사용률이 수준을 넘어가면 자동으로 리더 인스턴스가 승격되도록 해보겠습니다.
- Aurora를 페일오버 시키는 람다 함수를 작성합니다. 코드는 다음과 같습니다.
import boto3
def lambda_handler(event, context):
rds_client = boto3.client('rds')
cluster_identifier = 'test'
response = rds_client.failover_db_cluster(
DBClusterIdentifier=cluster_identifier
)
최소 권한으로는 rds:FailoverDBCluster 액션만 가능하면 됩니다.
-
CloudWatch에서 Aurora 의 CPU 사용률에 따라 경보를 생성하도록 설정합니다. 저는 현재 라이터 인스턴스의 CPU 사용률이 90을 넘어가면 경보가 발생하도록 설정하였습니다. 인스턴스가 아닌 클러스터의 지표에 대해 설정하는 등 필요에 따라 수정합니다.
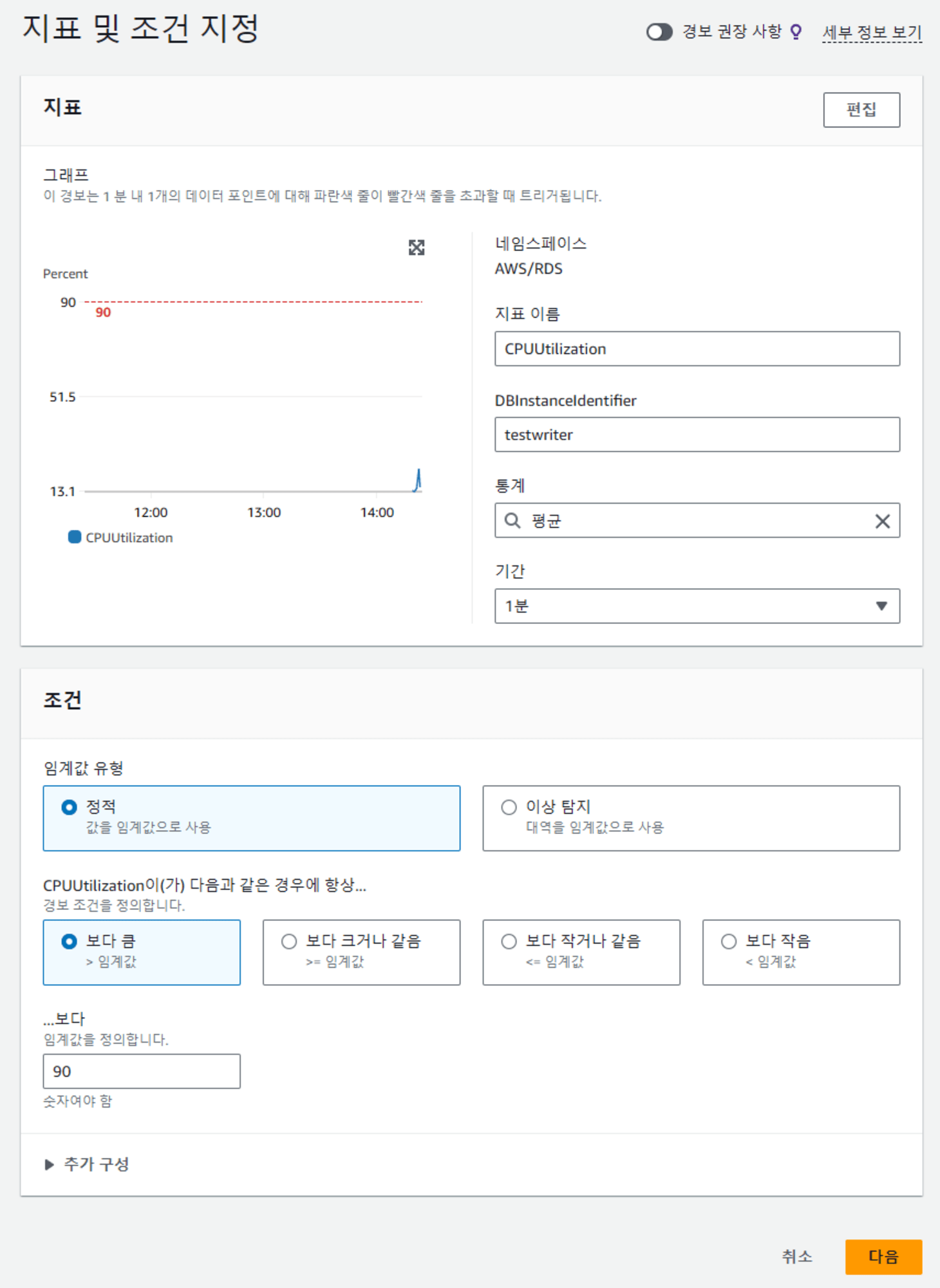

-
설정은 이걸로 끝입니다. 일시적으로 경보치를 수정하여 경보를 발생시키면 다음과 같이 라이터 인스턴스가 변경된 것을 확인할 수 있습니다.
-
경보 발생 전

-
발생 직후

-
변경 후

주의점
만약 다른 인스턴스를 승격하는 것으로 문제가 해결 된다면 이 방법은 유효한 대응 방법입니다.
하지만 리더 인스턴스를 승격한 후에도 CPU 상승률이 지속되어 다시 트리거가 실행된다면 상황이 끝날 때 까지 계속 승격이 반복되어 워크로드 전체에는 악영향을 미칠 가능성이 높습니다.
따라서 근본적인 문제 해결(쿼리의 수정, 스펙 변경 등)을 검토하는 것이 우선되어야 합니다.
마무리
Aurora 가 아닌 RDS 클러스터에 대해서는 promote-read-replica 나 promote-read-replica-db-cluster 라는 API 가 있으니 그쪽을 검토해보는 것을 추천합니다.
긴 글 읽어주셔서 감사합니다.
오탈자 및 내용 피드백은 must01940 지메일로 보내주시면 감사합니다.