![[レポート]オープンソースの可観測性 Observability the open source way(COP324)](https://images.ctfassets.net/ct0aopd36mqt/3IQLlbdUkRvu7Q2LupRW2o/edff8982184ea7cc2d5efa2ddd2915f5/reinvent-2024-sessionreport-jp.jpg)
[レポート]オープンソースの可観測性 Observability the open source way(COP324)

はじめに
本記事は「AWS re:Invent 2024 - Observability the open source way (COP324)」のセッションレポートです。
セッション動画は以下で公開されています。
概要
[概要]
Interested in using open source tooling for observability? Setting up an effective observability solution with open source tools can be challenging due to their rapid pace of development. AWS offers the flexibility to implement observability with AWS managed versions of open source tools like Prometheus, Grafana, and OpenTelemetry. This session shows how managed open source services enable a standardized approach to instrumentation, collection, and analysis. Discover recommended architecture patterns for each observability stage, including instrumentation with OpenTelemetry, ingestion with Amazon Managed Service for Prometheus and Amazon OpenSearch Service, and insights with Amazon Managed Grafana.
[機械翻訳]
オープンソースツールによる可視化にご興味はありますか?オープンソースツールは開発のペースが速いため、オープンソースツールを使用して効果的な可視化ソリューションをセットアップするのは難しい場合があります。AWSでは、Prometheus、Grafana、OpenTelemetryなどのオープンソースツールのAWS管理バージョンを使用して、柔軟に可視化を実装できます。このセッションでは、管理されたオープンソースサービスが、インストルメンテーション、収集、分析に対する標準化されたアプローチをどのように実現するかを紹介します。OpenTelemetry によるインストゥルメンテーション、Amazon Managed Service for Prometheus および Amazon OpenSearch Service による取り込み、Amazon Managed Grafana による洞察など、各観測可能性段階における推奨アーキテクチャパターンをご紹介します。
自分なりに要約
以下は私なりの要約です。
OSSって便利だけど、自分たちでインフラ部分まで含めて全部管理するのって大変ですよね。
だからAWSのマネージドサービスを使えば、色々な課題が解決するかもしれませんよ。
じゃあ、具体的にどんな点でAWSのマネージドサービスを使うことでメリットがあるのかみてみましょう。
今回はStripe社が自己管理型のサービスからAWSのManagedサービスへ大規模移行した話も聞けますよ!
みたいな感じです。
こんな人に見てほしい
Prometheus, OpenSearch, Grafanaを自身で管理している方。また自身でアプリケーションを作成してメトリクスなどを可視化している方。
そして、その運用が大変だな〜AWSに移行したら楽になるのかな〜?と考えている方にはおすすめです。
よくあるアーキテクチャの紹介や、デモンストレーションで実際の監視ダッシュボードが見れますよ!
また、実際に自分たちが管理するアプリケーションからオープンソースのサービスに移行した企業の話も聞けるので、実例が聞きたい!という方にもおすすめかと思います。
内容
アジェンダ
アジェンダは以下の通りです。

よくある課題のデモンストレーション
まずはよくありそうなケースの紹介です。
ジェシカというSREチームの一員がいます。
ジェシカはまもなく週末という金曜日の夜にオンコールの当番をしてました。
そんな時、ジェシカの元に通知が届きます。
通知内容はフロントエンドアプリでカナリアテストで色々な所からレスポンスが遅いというアラートの通知です。

ジェシカは思います。
「大丈夫、Grafanaのダッシュボードがあるからすぐに原因を特定して週末を迎えよう!」と。
しかし、なぜかEKS上で管理されたGrafanaにもPrometheusにもアクスできません。
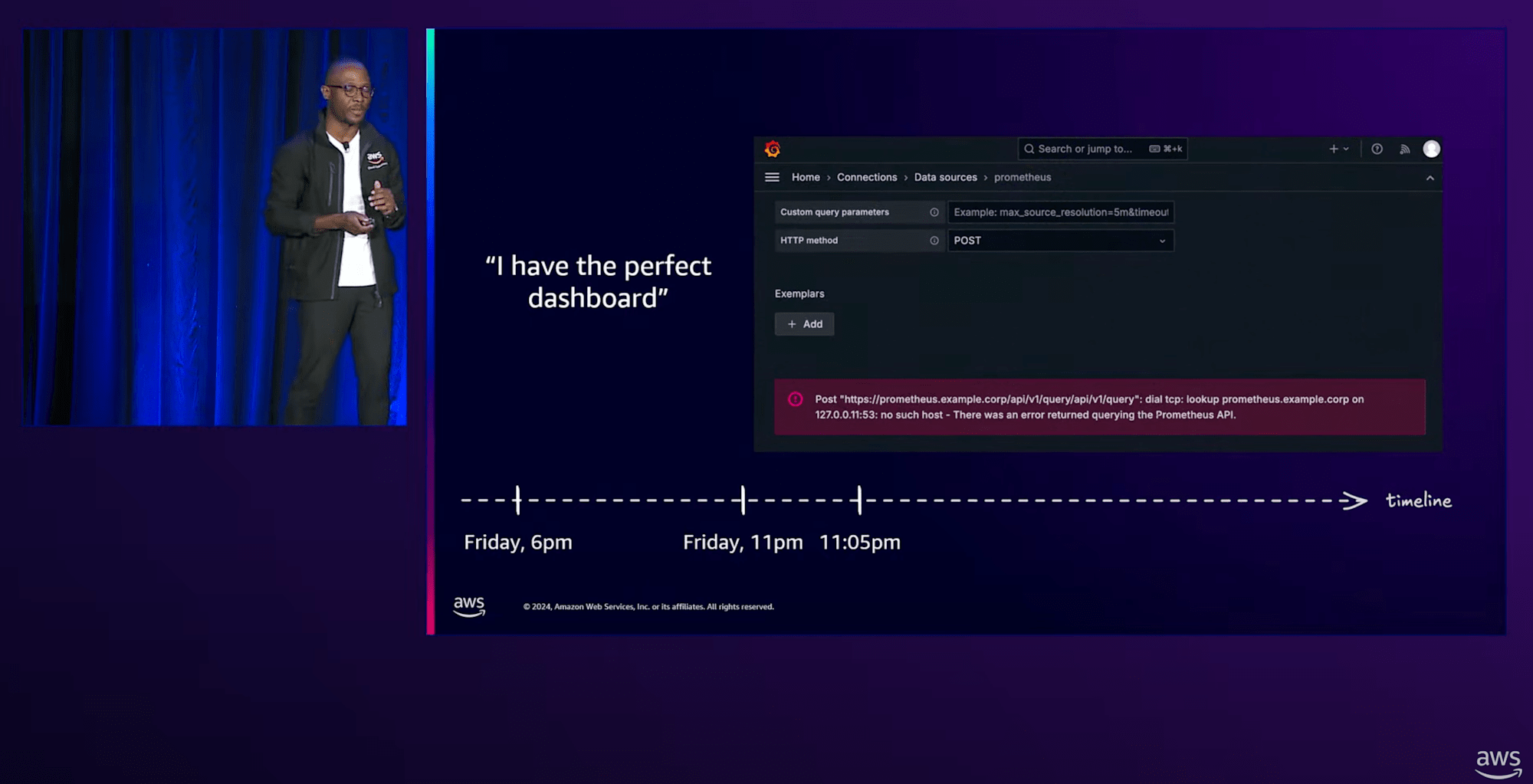
困ったジェシカはブラウザ版のPrometheusにアクセスします。しかしブラウザからもアクセスできません。
するとジェシカの対応が遅れていることで、アラートがエスカレートしてバックアップとして待機しているボブにもアラートが届きます。
ボブ:「大丈夫大丈夫、僕はアプリケーションログを確認するからジェシカはPrometheusで何が起こってるか確かめてみて〜」
しかし、簡単には原因の特定ができませんでした。
アプリケーションは大規模なマイクロサービスアプリケーションで構成されていて、どのアプリケーションログを調査すればいいか分かりません。

数分後...
ジェシカ:「Prometheusがメモリ不足かもしれない、ログにOMM killがたくさん見られるし、ディスク容量も不足してそう」
ボブ:「ログを見た感じだと、接続プールエラーがカードサービスで発生していて、他のサービスでも同じ問題が起きているみたいだ」

手がかりが見つかったので、彼らはサービスの再起動など、必要な対策を講じ無事に回復に向かいました。
この例ではOSSを自身で運用することの難しさを伝えたかったのだと思います(おそらく)
今回の例ではPrometheusが適切にスケールして、多くのメトリクスを参照するための十分なリソースがありませんでした。

OSSはリリースサイクルが速く、常に変化しています。
また、サポートが限られているため問題解決のために相談できる人も限られています。
これが自身でOSSを利用する辛い部分です。
AWSのマネージドサービス
そこで、AWSのマネージドサービスを使うことでOSSを使う負担が軽減します。
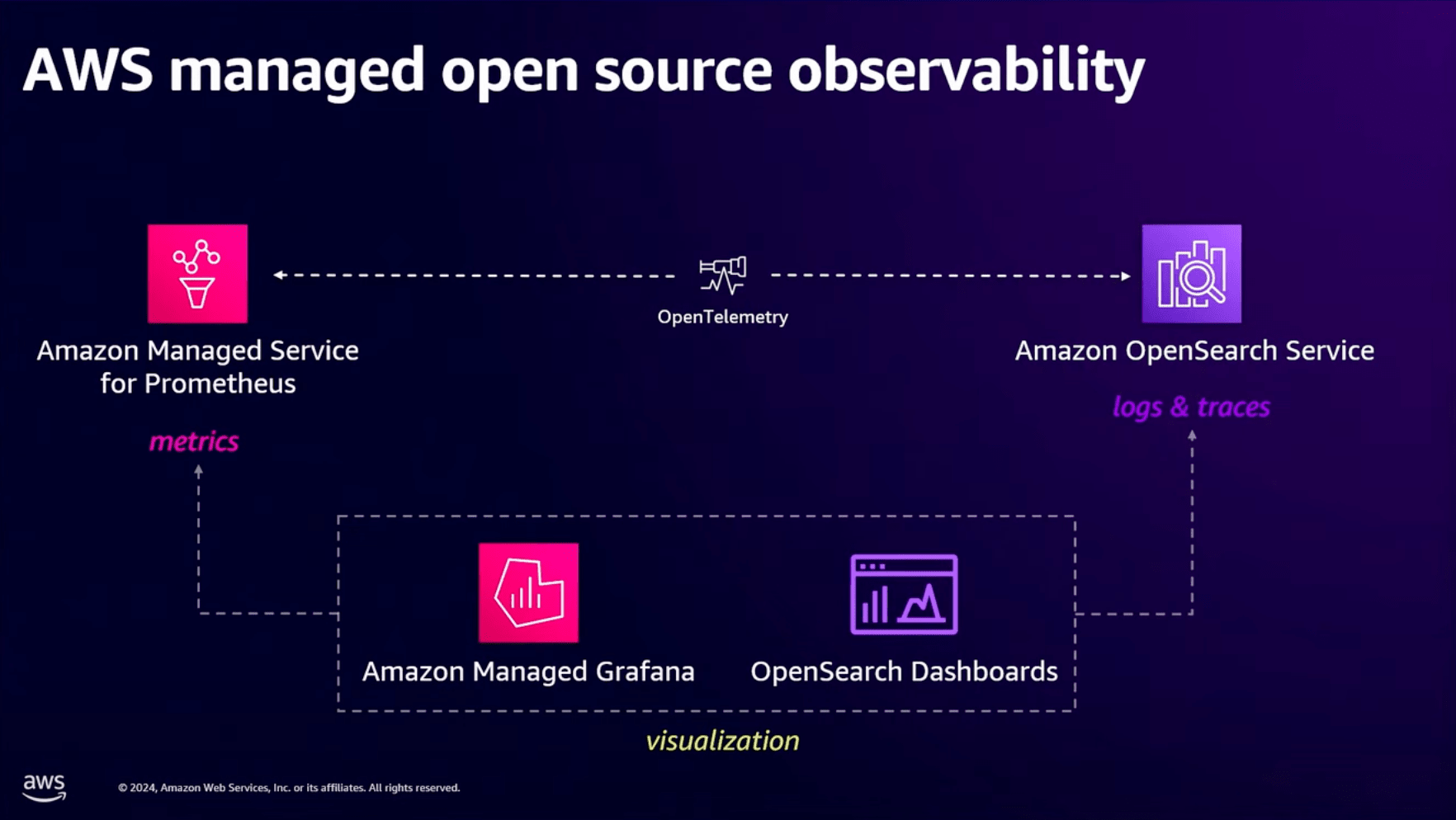
今回の例に出てきたPrometheusは、互換性のあるAmazon Managed Service for Prometheus(以下、Managed Prometheus)を使うこで必要に応じで自動でスケーリングするなど管理の手間が省けます。
また、ログのトレースはAmazon OpenSearch Service(以下、OpenSearch Service)が利用できます。
OpenSearch Serviceはメトリクスも監視できますが、メトリクス監視はより適したPrometheusを使うのがベストでしょう。
これらのデータの可視化にはAmazon Managed Grafana((以下、Managed Grafana)やOpenSearch Dashboaardsを利用することでデータの可視化まで実現できます。
よく見られるリファレンスアーキテクチャは以下の図のようなものです。
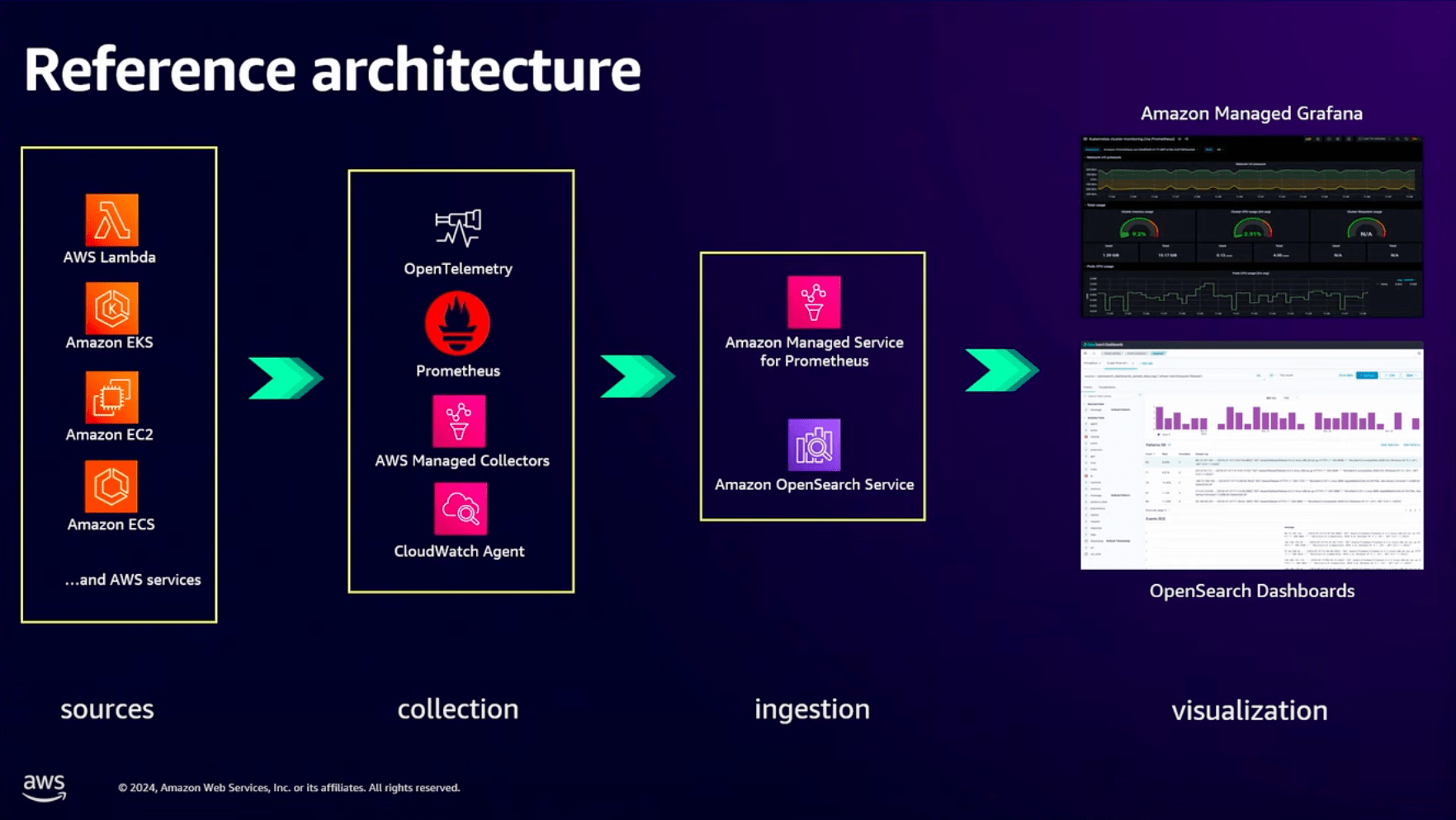
データ多くはLambda, ECSなどのAWSサービスを含め、アプリケーションから送られてきます。
これをOpenTelemetryやPrometheusを使用して収集し、
Managed PrometheusやOpenSearch Serviceにデータを格納します。
そして最後にManaged GrafanaやOpenSearch Dashboaardsで可視化します。
Managed Prometheusのメトリクス収集
Managed PrometheusはOpenTelemetryから送られてきたデータをIngesterモジュールを使ってS3に保存しています。
またデータへのクエリはVPCエンドポイントを通してManaged GrafanaやHTTPエンドポイントからアクセス可能です。
通知に関してもユーザーはVPCエンドポイントを経由してSNSにセキュアに通知することができます。
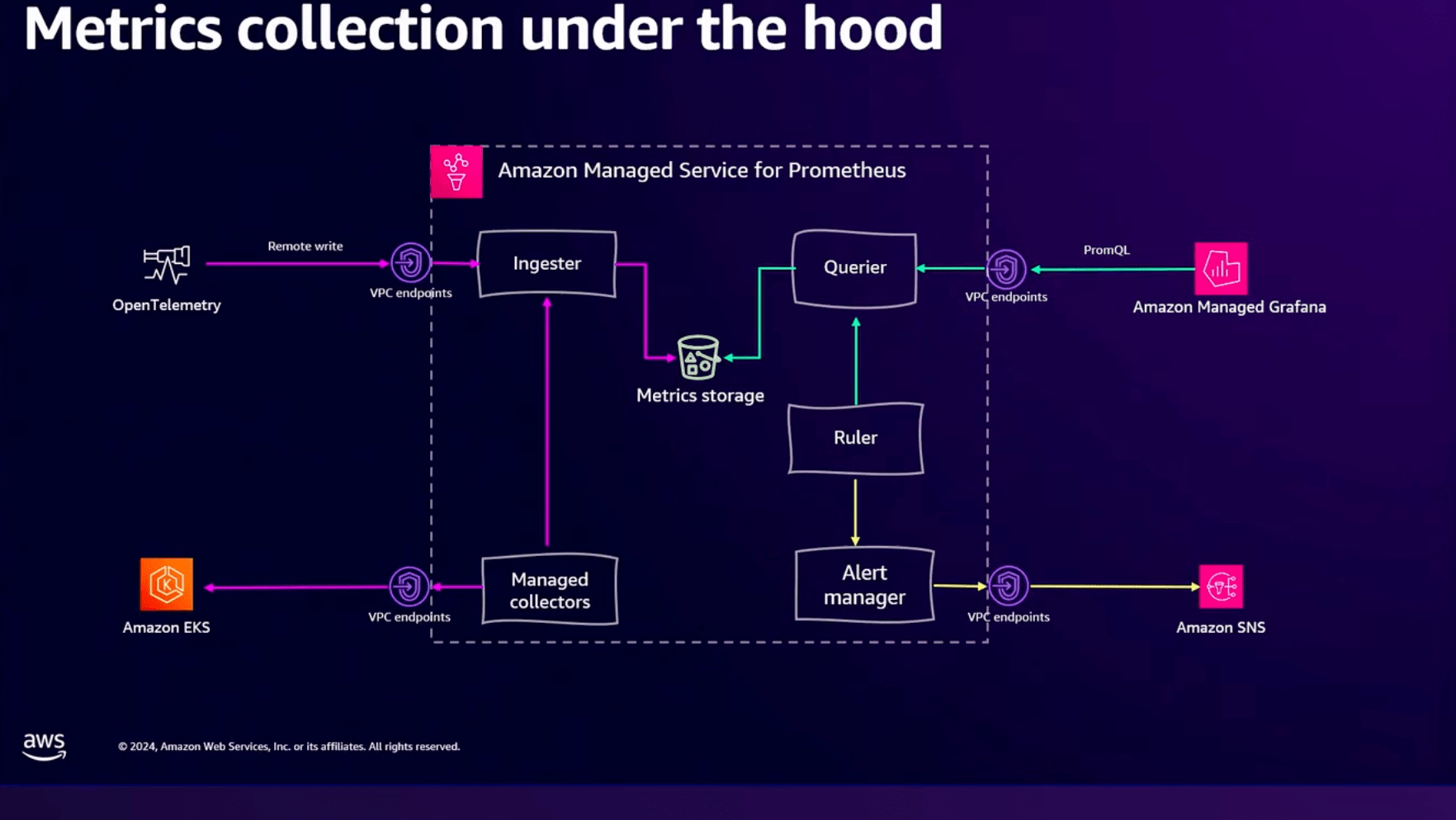
ストレージレイヤやクエリレイヤといった部分はAWSが管理してくれているので、管理コストが下がります。
こういった他のサービスとの連携はAWSのマネージドサービスの強みですね。
この辺りはManaged Grafanaも同じでデータソースとの接続や通知はAWSのサービスと簡単に連携できるので、オープンソースのサービスを使うよりも管理コストが削減できます。
OpenSearch Serviceのログトレースと取り込み
ログの取り込みにはOpenSearch Ingestion Pipelinesが便利です。
ログを扱うFluent BitやOpenTelemetry, S3などからデータを収集して、一連の処理を行った後、OpenSearch Serviceにデータを渡すことができます。
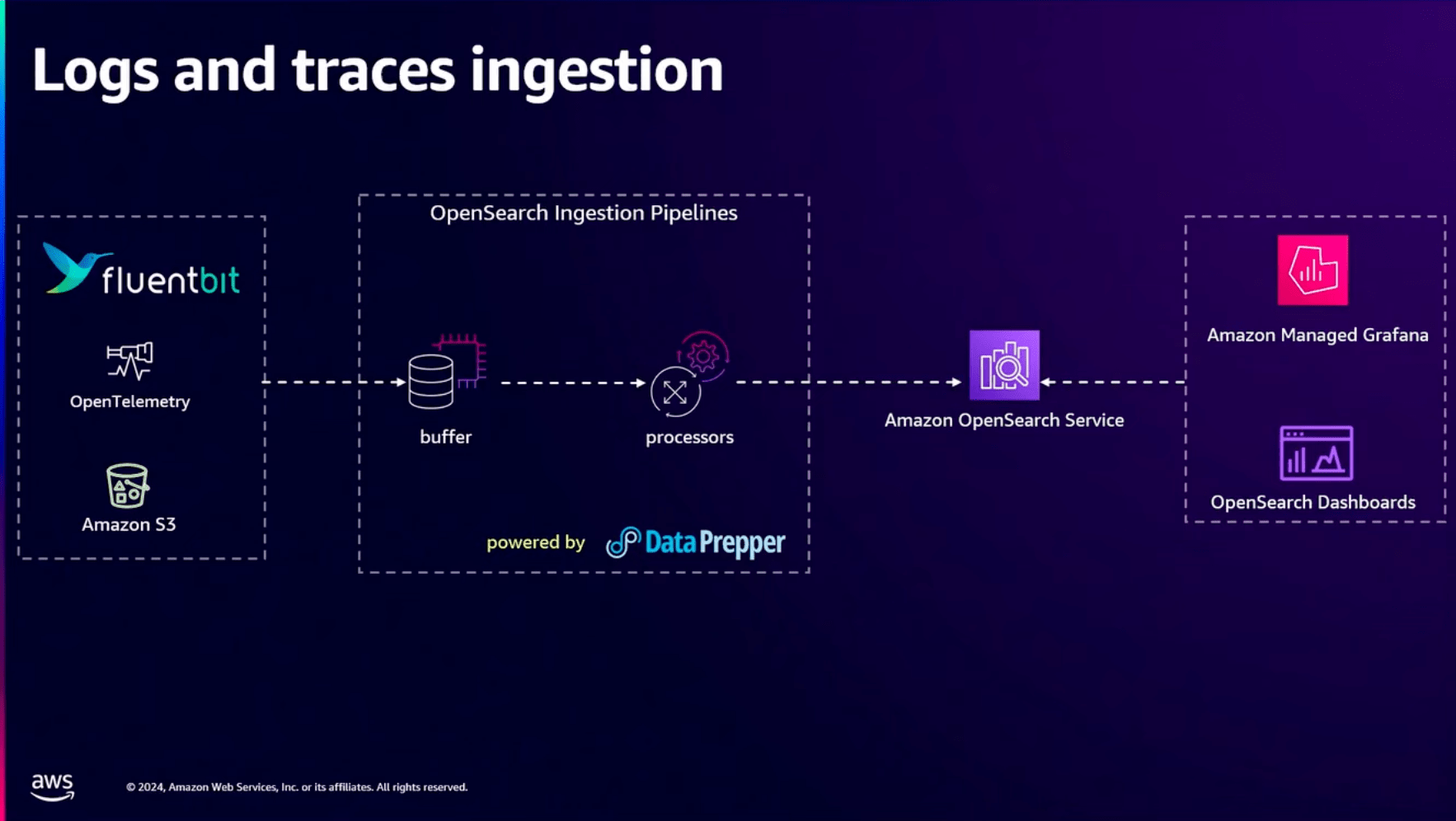
このOpenSearch Ingestion Pipelinesの部分はAWSが管理しておりサーバレスな仕組みになっています。
データ集約型のオブザーバビリティアーキテクチャ
データは1アカウントからのみ送られてくるわけではありません。
複数のアカウントやオンプレミス環境または別のクラウドサービスから送られてくる可能性もあります。
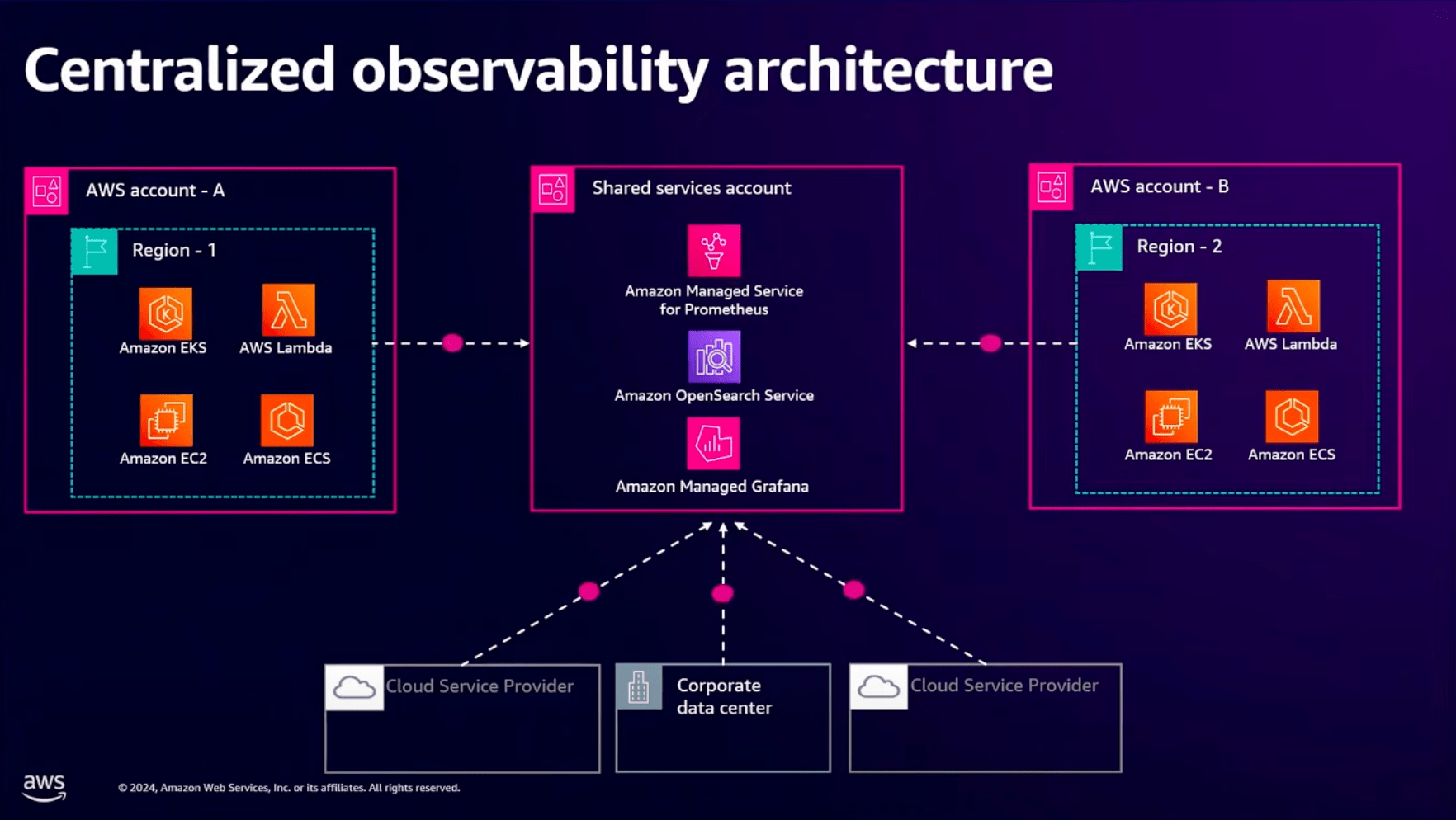
こういったケースでも、AWSのマネージドサービスをコレクターとしてデータをAWSに集約させることができます。
デモ
次に実際のアプリケーションを使ったデモです。
少し複雑ですが、こちらがアプリケーションのアーキテクチャ図のようです。
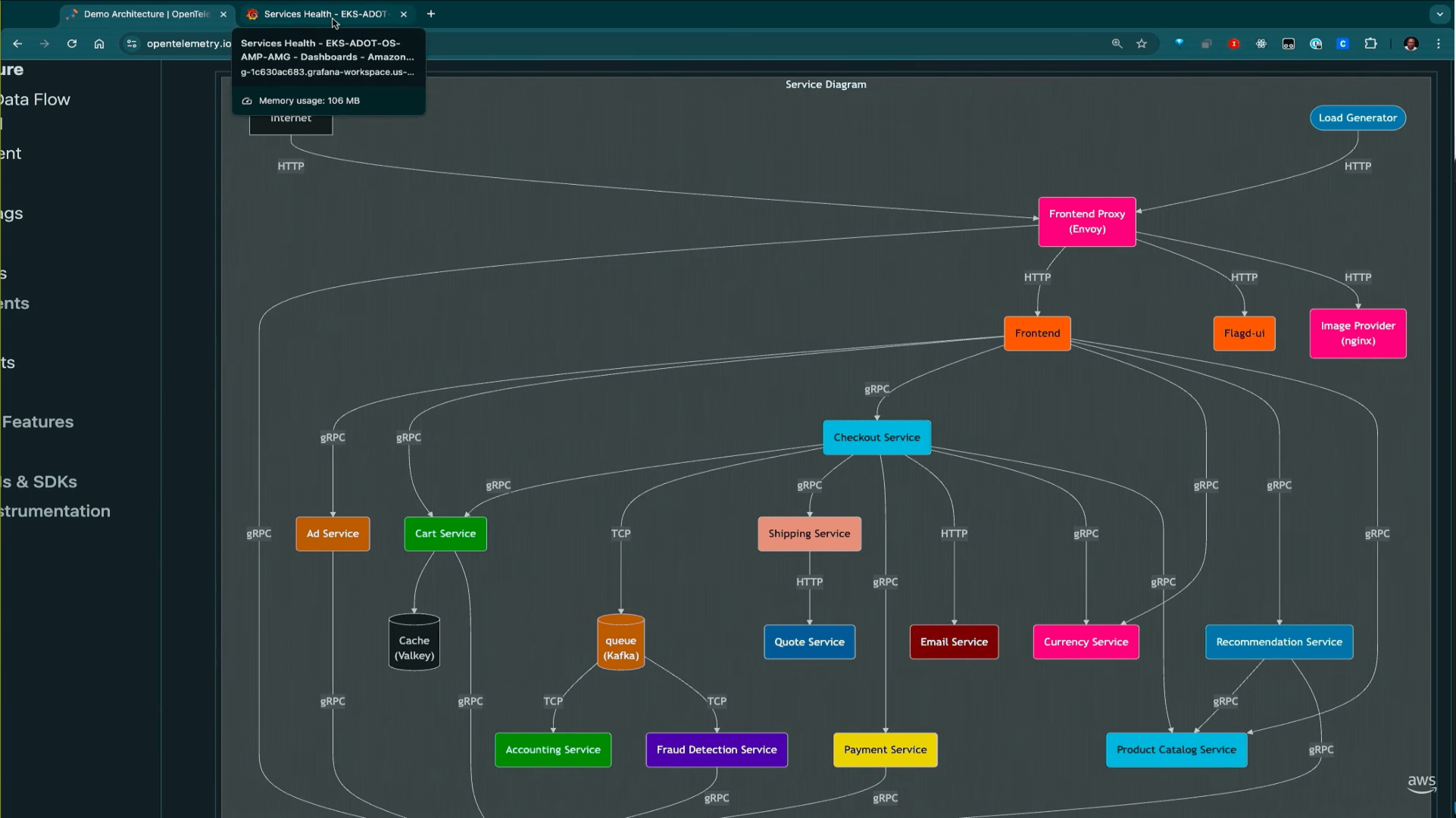
Grafanaにはすべてのサービスのすべてのリクエストが表示されています。
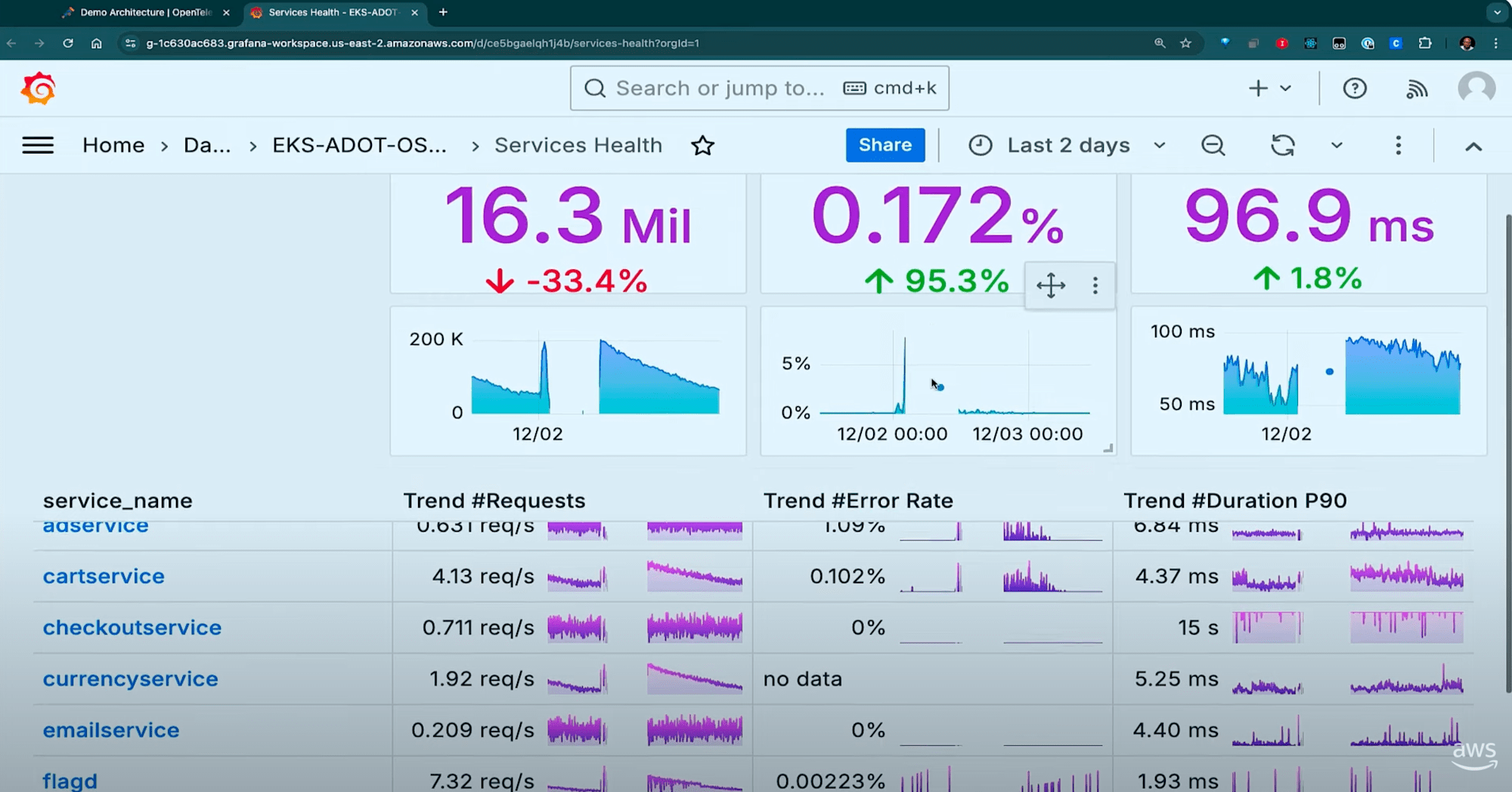
内容はサービス毎のリクエストトレンド、エラー数などが表示されています。
データソースはManaged Prometheusです。
ログはデータソースとしてManaged Prometheusと一緒にOpenSearch Serviceを使っていて、メモリ、CPU、その他の一般的な情報やトレースの情報もあります。
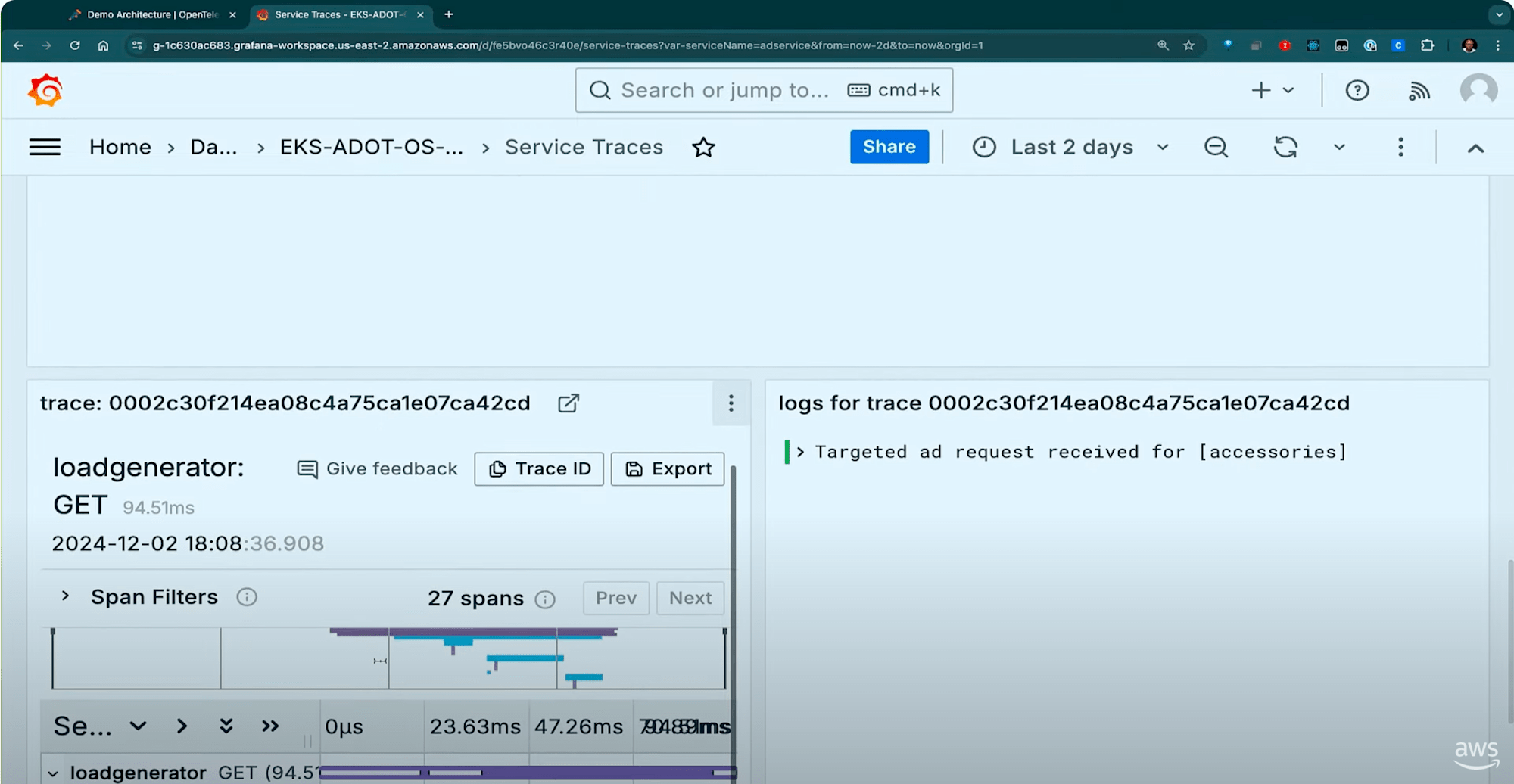
Managed Grafanaを使っているので、トレースデータをフィルタリングしてアプリで何が起こっているかを観察することもできます。
例えばリクエストが遅いデータのみをフィルタリングすることも可能です。
下の画像では高レイテンシのリクエストのみをフィルタリングした画像です。
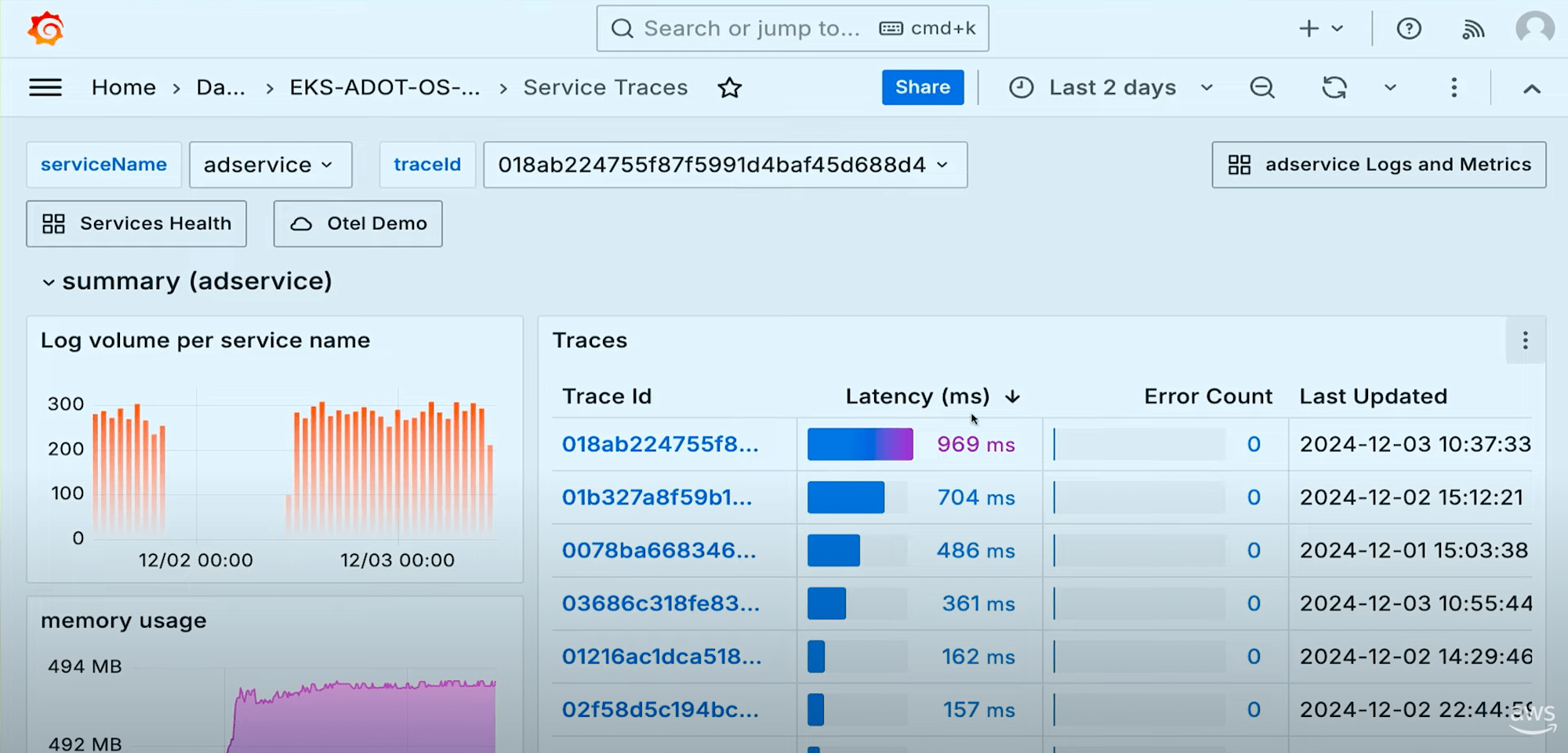
このダッシュボードの素晴らしいところは、Managed Prometheusで発見した情報と、OpenSearch Serviceで発見した情報の相関関係を発見できるという点です。
これは一つのダッシュボードでデータを可視化する大きなメリットだと思います。
マイグレーションの問題
このセッションではStripeのエンジニアであるCody氏の話も聞けるようでうす。
Cody氏はStripeのログ、メトリクス、トレース、プロファイリングデータを扱うチームのテックリードです。
Stripeは2023年に以下を達成しました。
- 1兆ドルの取引
- 5億件のAPIリクエスト
- 99.999%の信頼性

Cody氏が2022年に入社時点でStripeにはオブザーバビリティに関してコスト削減をしなければならないという課題がありました。
そこで選んだのがManaged Prometheusです。
しかし、移行といっても簡単ではありません。
既存のシステム(ベンダーの開発したシステム)には
- 40,000のアラート
- 150,000のダッシュボードクエリ
- 数えきれないコンポーネント
- 2億7000万のメトリクス
があり、これを手動で移行するのは現実的ではないので、自動化する必要がありました。
そこで、既存のアラートとダッシュボードを解析して、変換するためのツールを開発することにしました。
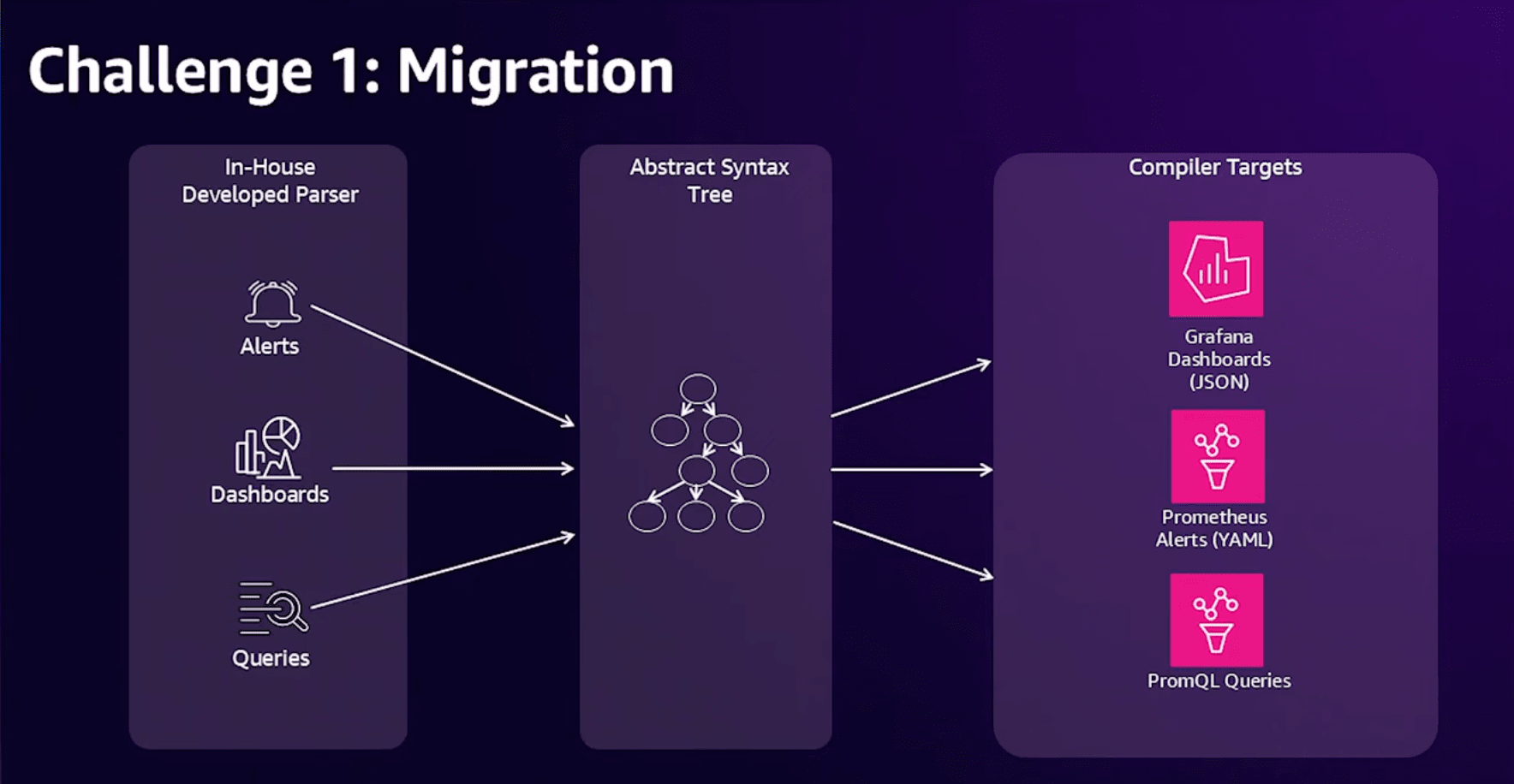
この過程で気づきがありました。
既存のクエリはパターンが限定的であることに気づき、それを利用して効率的な変換ツールを作成することができたようです。
また、類似したアラートやクエリをグループ化する方法を発見したことで、一つの問題を修正をすると、他の問題も自動的に修正されることも発見しました。
この経験から、大規模な移行を行う際にはできるだけ早くシステムの移行に関する自動化プロセスを確立することが重要であると感じたそうです。
この問題は規模が大きければ大きいほど起こりそうですね。
話の中でもありましたが、実は使ってないダッシュボードやアラートなんかもたくさんありそうな気がします。
今回はManaged Prometheusですが、AWSのサービスによってはクエリに料金が発生するDBもあるため、定期的にダッシュボードの棚卸しをしてコスト削減はやっておいた方がいいと思います。
ユーザー体験の問題
2つ目の問題はユーザー体験の問題です。
OSSのGrafanaがPrometheusからアラートを管理する場合、アラートセット全体をダウンロードしてからクライアント側でフィルタリングを行います。
つまり、アラートの数が少ない(10,000個程度)場合は問題になりません。
しかし、Stripeでは100,000個以上のアラートがあります。
そのため、クライアント側は長いローディング画面を見せられ、最終的にはエラーが表示されます。
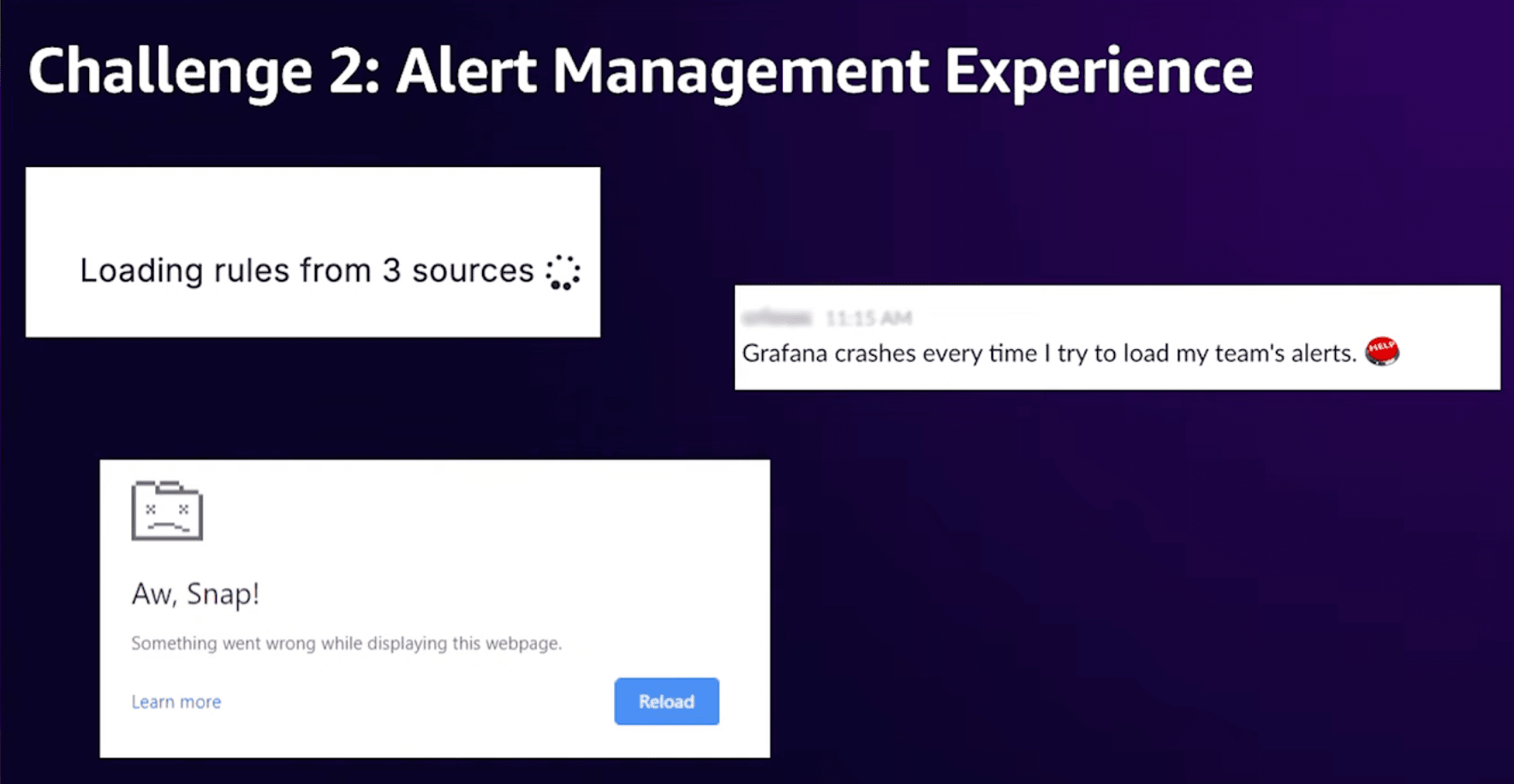
そこで、この問題に対処するために以下のアプローチを取りました。
移行中: 移行専用のUIを用意し、古いシステムから新しいシステムへのアラートとダッシュボードの移行を管理しやすくした
移行後: Stripeの管理パネルに独自のアラート管理ツールを組み込んだ
はて?ここでは何が言いたかったのだ?と思いましたが、
恐らくOSSは完璧ではないので、特に大規模環境ではユーザー体験を向上させるために自分たちで実装が必要な場合もある。
また、多くのOSSでは非常に大規模な環境を想定して設計されていない場合が多い。
ということが言いたかったのではないかと思います。
データの多様性
3つ目の問題はデータの多様性や一意性に関する問題です。
Stripeは2億7000万のメトリクスを持っていました。
これを古いシステムからManaged Prometheusに移行し始めた際、メトリクスの数が予想以上に増加し続けました。
原因を調査すると、エラー情報、タイムスタンプ、IPアドレス、URLなどの具体的な値を一つの属性として保存していたようです。
この問題は古いシステムでは不適切なデータを自動的にフィルタリングしていましたが、PrometheusのようなOSSではデータをそのまま受け入れるという違いが原因だったようです。
解決策として、データの収集と保存の間にMantisというストリーム処理を行うソフトウェアを使いました。
ストリーム処理の中でフィルタリングを行い、必要なデータのみを保存するように構成を変更しました。
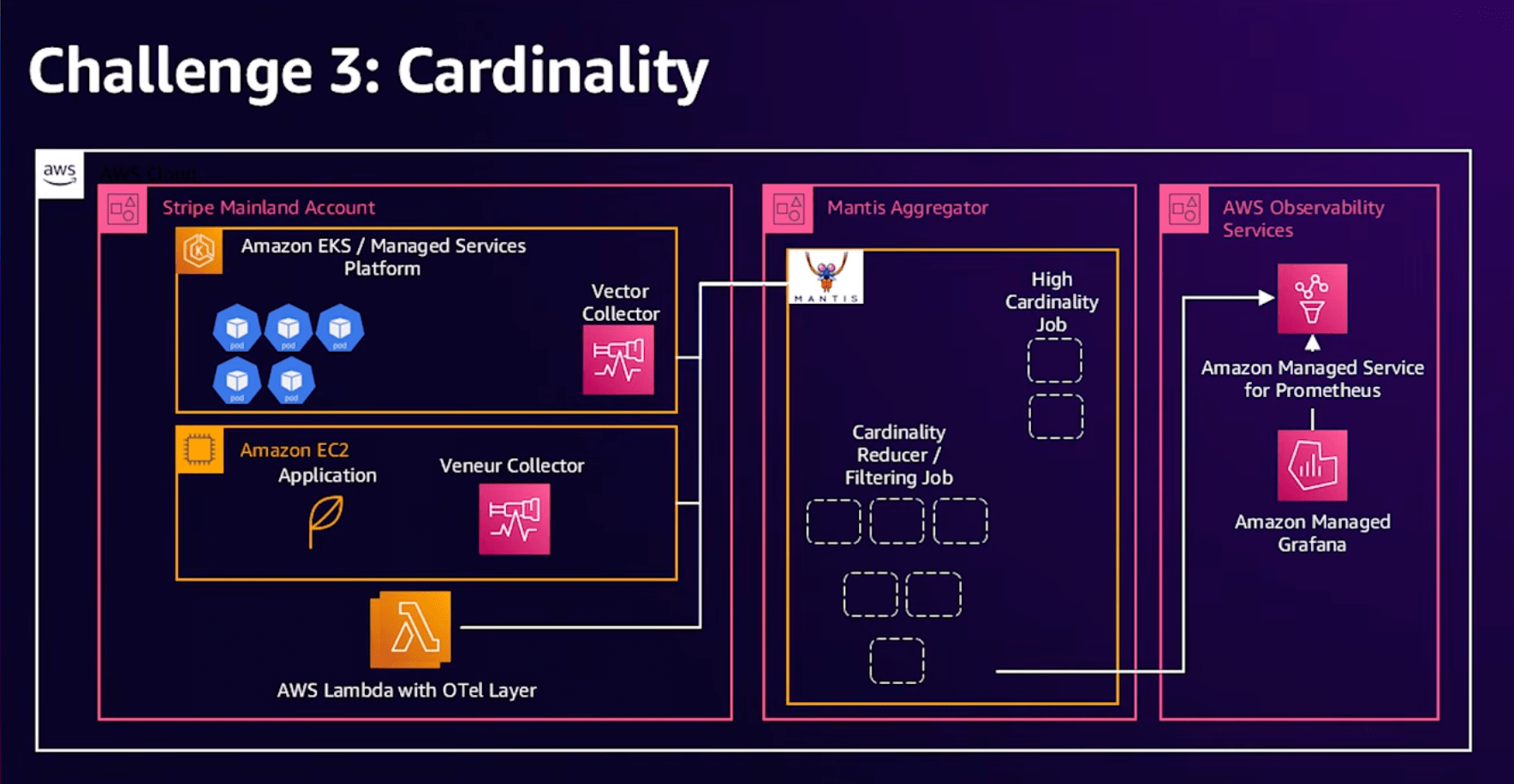
教訓として大規模なシステムを運用する際はデータ保存に関して問題が発生することがあるので、そういった問題が発生した場合でも柔軟に対応できるシステムを構築することが重要だと感じたそうです。
これらの問題を解決したことで、オブザーバービリティに関するコストを約80%削減できたそうです。
また、アクティブなデータが2倍になりました。
これは悪いことではなくStripeの監視対象が拡大して、より多くのメトリクスを収集するようになったからだそうです。
他にもアラートルールの数が3倍に増えました。
これは監視を強化したことで問題を早期に発見できるようになったことでアラートルールが増えたようです。

つまり、Managed Prometheusに移行したことでコストの大幅な削減と、より多くのデータ収集、より広範囲の監視ができるようになったということです。
Prometheus、Grafana、OpenSearchの新機能
それぞれのマネージドサービスに関して、分野ごとに去年からのアップデートを紹介します。
スケーラビリティ
【昨年】
ワークスペースあたり5億のアクティブなタイムシリーズメトリクス
30,000のルール
をサポートすると発表しました。
ちなみにワークスペースは、メトリクスの取り込み、クエリ、保存を行う場所です。
【現在】
ワークスペースあたり10億のアクティブなタイムシリーズ
100,000のルール
をサポートすると発表しました。
これにより、EKSクラスター、EC2環境、すべてのアカウント、ハイブリッド環境、さらにマルチクラウド環境など、様々なメトリクスを統合できるようになりました。
次にManaged Grafanaでは以前は同時ユーザー数は500人まででしたが、現在は1000人までサポートしているようです。

コスト
データを統合してより多くの価値を引き出し、同時にコストを削減するためには全体像を可視化して、多くの情報を相関させる必要があります。
そのために次の3つのログが必要になります。
- VPCフローログ
- CloudTrailイベント
- AWS WAFログ

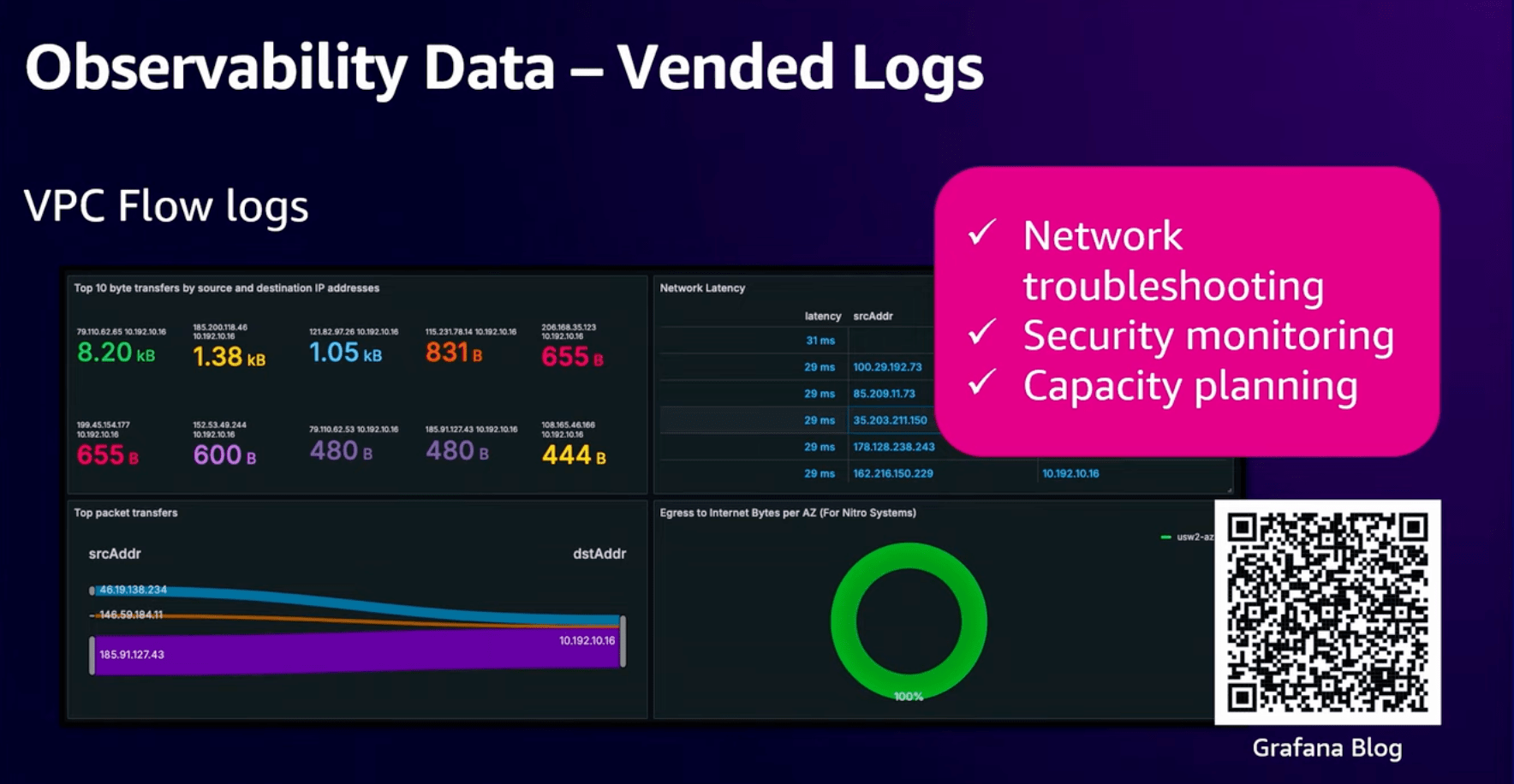
【VPCフローログ】
トラフィックの多い通信を確認し、ネットワークレイテンシーやVPC内で使用される帯域幅を把握するのに必要になります。
VPCフローログを取得してネットワークのトラブルシューティング、セキュリティ監視、必要なネットワークリソースの調査を行います。
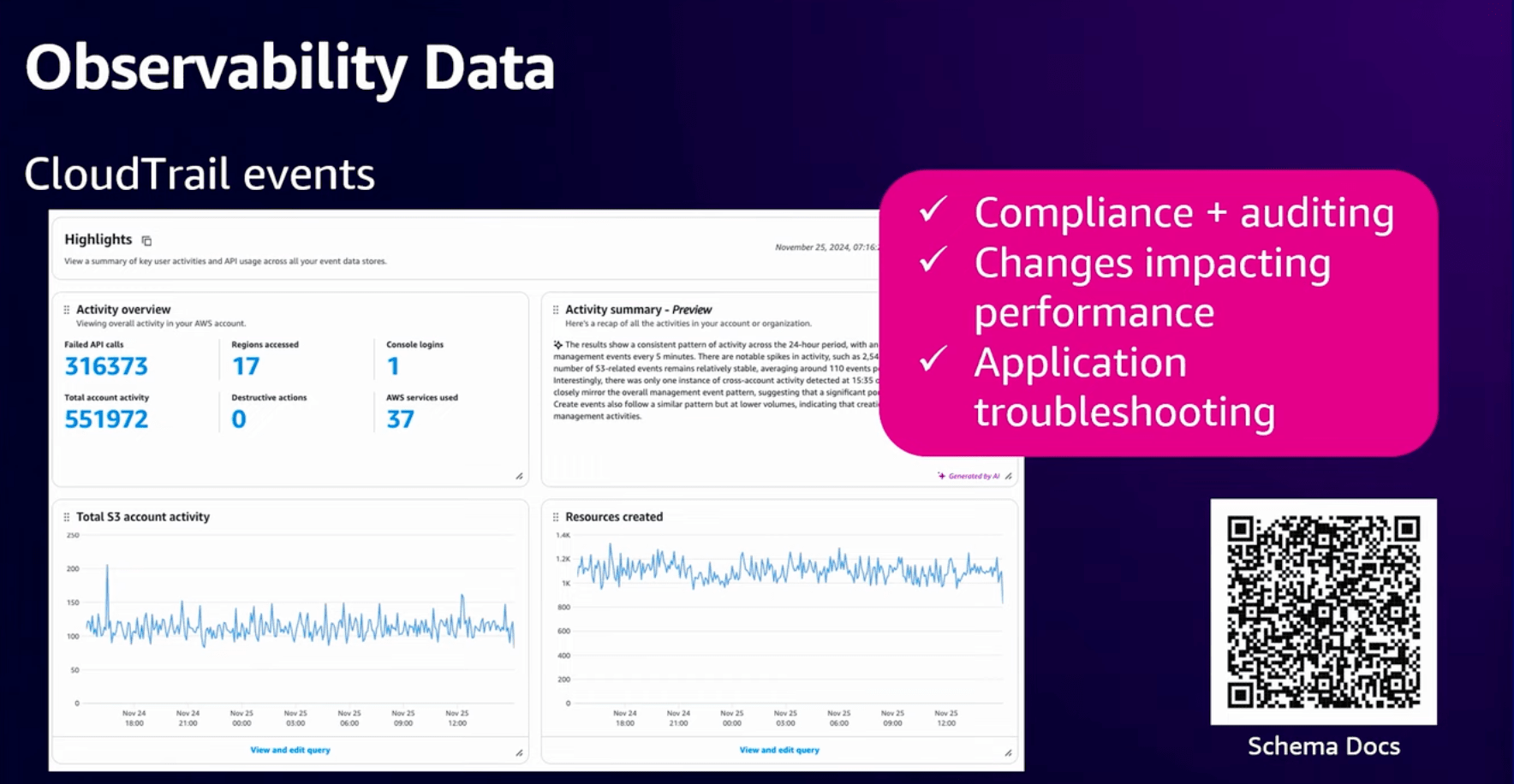
【CloudTrailイベント】
誰が何をどこでなぜ変更したのかを確認し、パフォーマンスに影響を与える変更であるかを確認します。
同時にCloudTrailイベントを監視することでコンプライアンスと監査のニーズを満たすことができます。
【WAFログ】
アプリケーションにアクセスしているIPアドレスやユーザーエージェントなどを理解して、望ましくないトラフィックを監視/ブロッックすることができます。
特にトランザクション処理に多くのリソースを使用しているボットなどをブロックすることでコスト削減に繋がります。

コストという観点では、クエリ言語を学ぶ学習コストもバカにはなりません。
OpenSerchでは上記に述べたような複数のログソースのデータを統合して可視化することができます。
しかし、ここで大きな問題があります。
例えば、CloudTrailイベント、CloudWatch Logsなど、各ログに対するクエリ言語は異なります。
つまりオブザーバビリティを必要とするエンジニアは複数のクエリ言語を覚える必要があります。
この学習コストはバカになりませんね。
そこでAWSの提供するマネージドなOpenSearch Serviceでは統一のクエリ言語で様々なログソースからデータを取得できるような仕組みがあります。
こちらの機能は恐らくこのブログが参考になるかと思います。
ポータビリティ
Mark氏はOSSの可視化ツールは積み木みたいなものだと言ってます。
何を収集する必要があるか、どのように収集するか、何を監視するか、どのアラームを設定するか?など
また、それらが決まったとしても実際の環境にデプロイして継続した運用が必要になります。
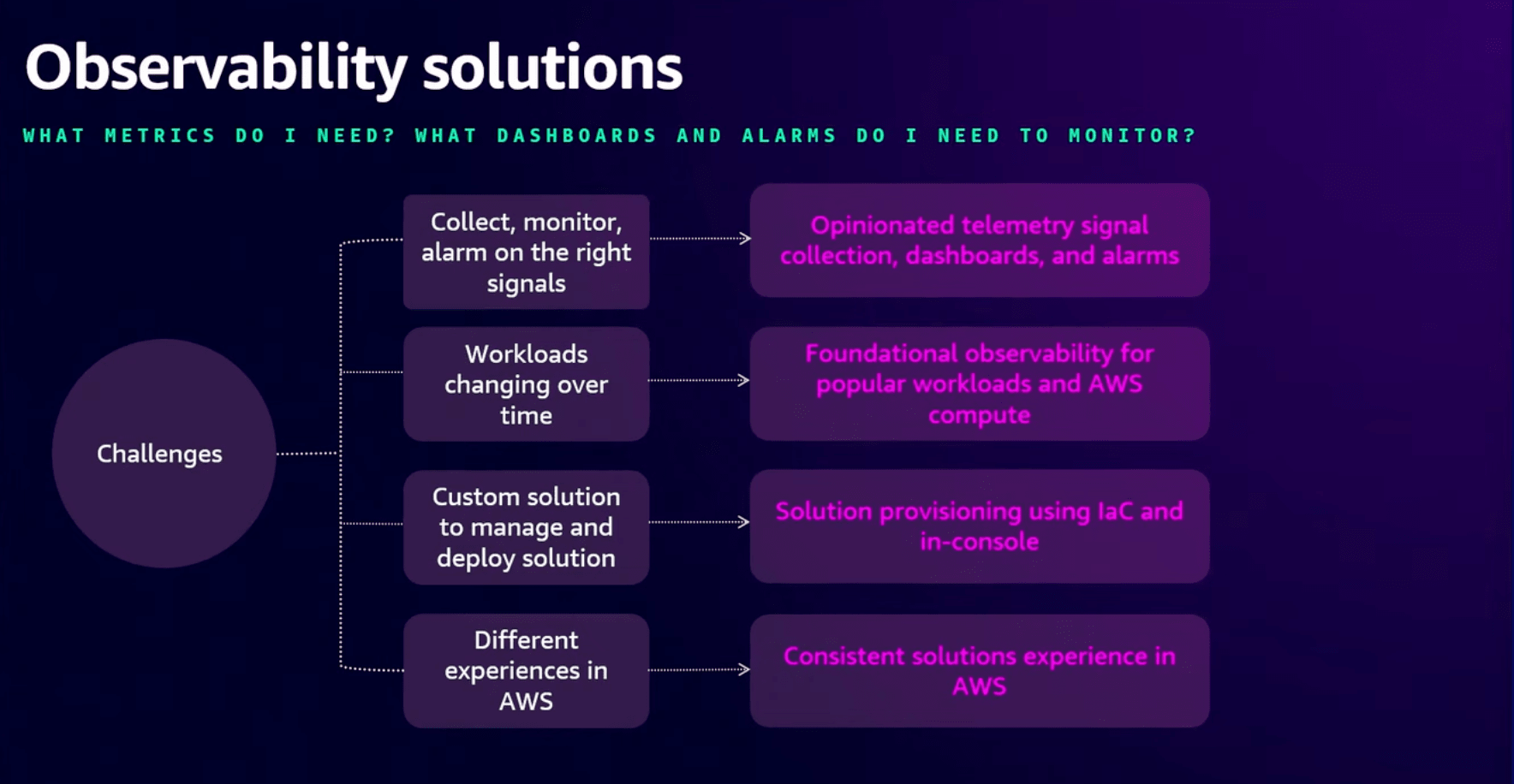
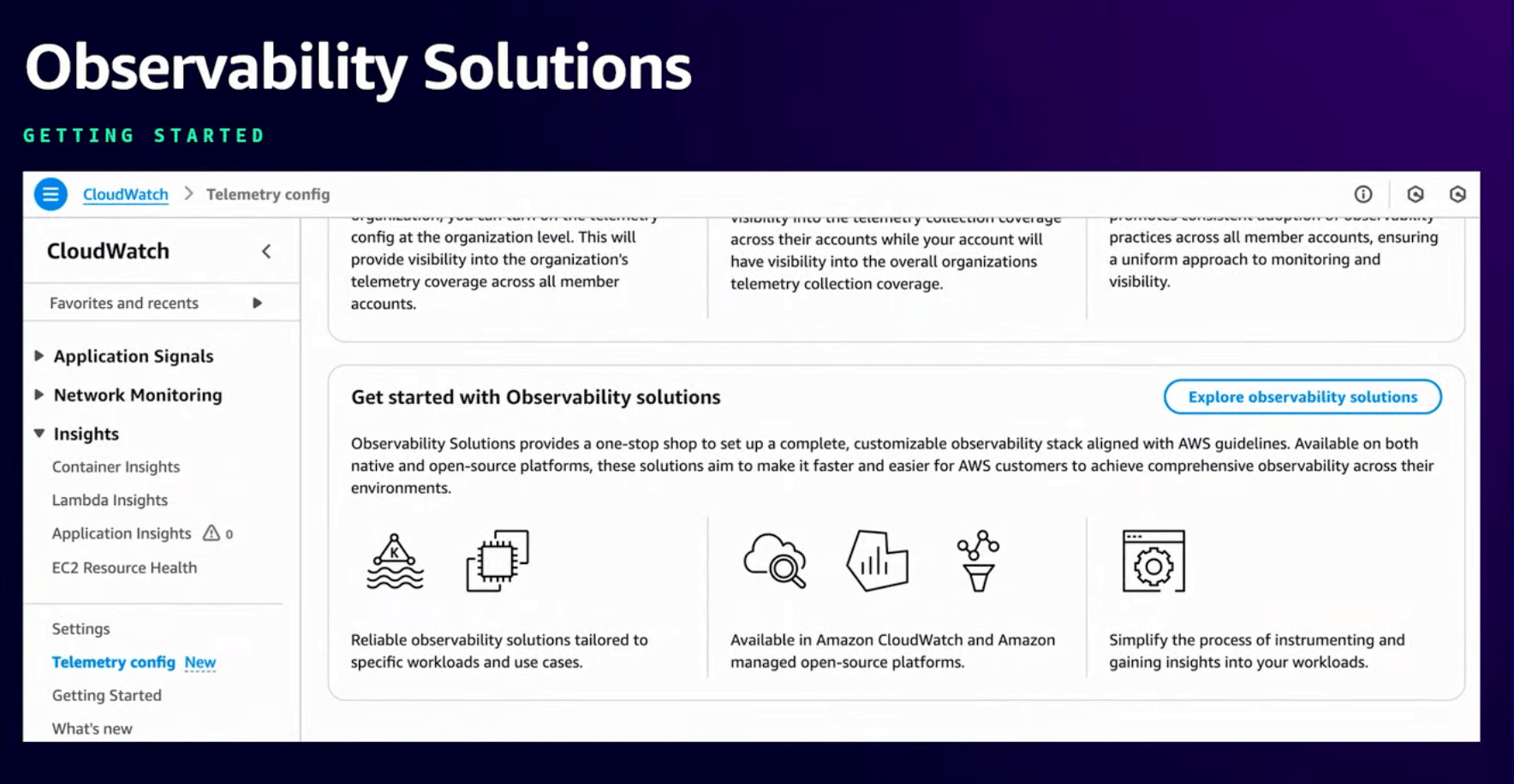
この課題を解決するために、オブザーバビリティソリューションを発表しました。
こちらのカタログを見るには CloudWatch > テレメトリ設定
EKSを選択すると、Managed Grafanaと統合する場合のドキュメントが表示されるので、一番下のDeploy Solution IaCを選択
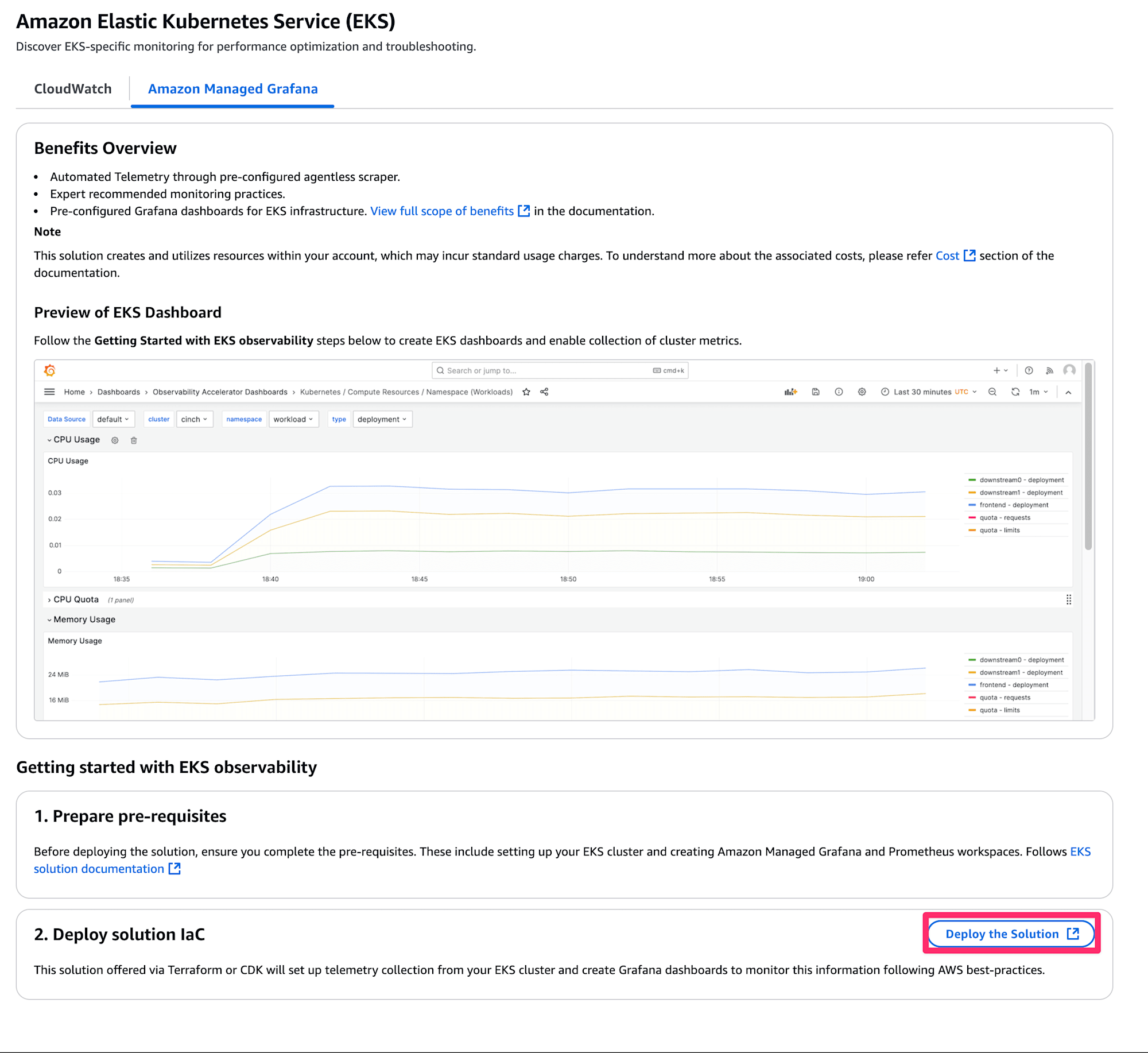
するとCDKまたはTerraformでインフラストラクチャを構築する手順が表示されます。

実際のモニタリング画面は以下のようになるようです。
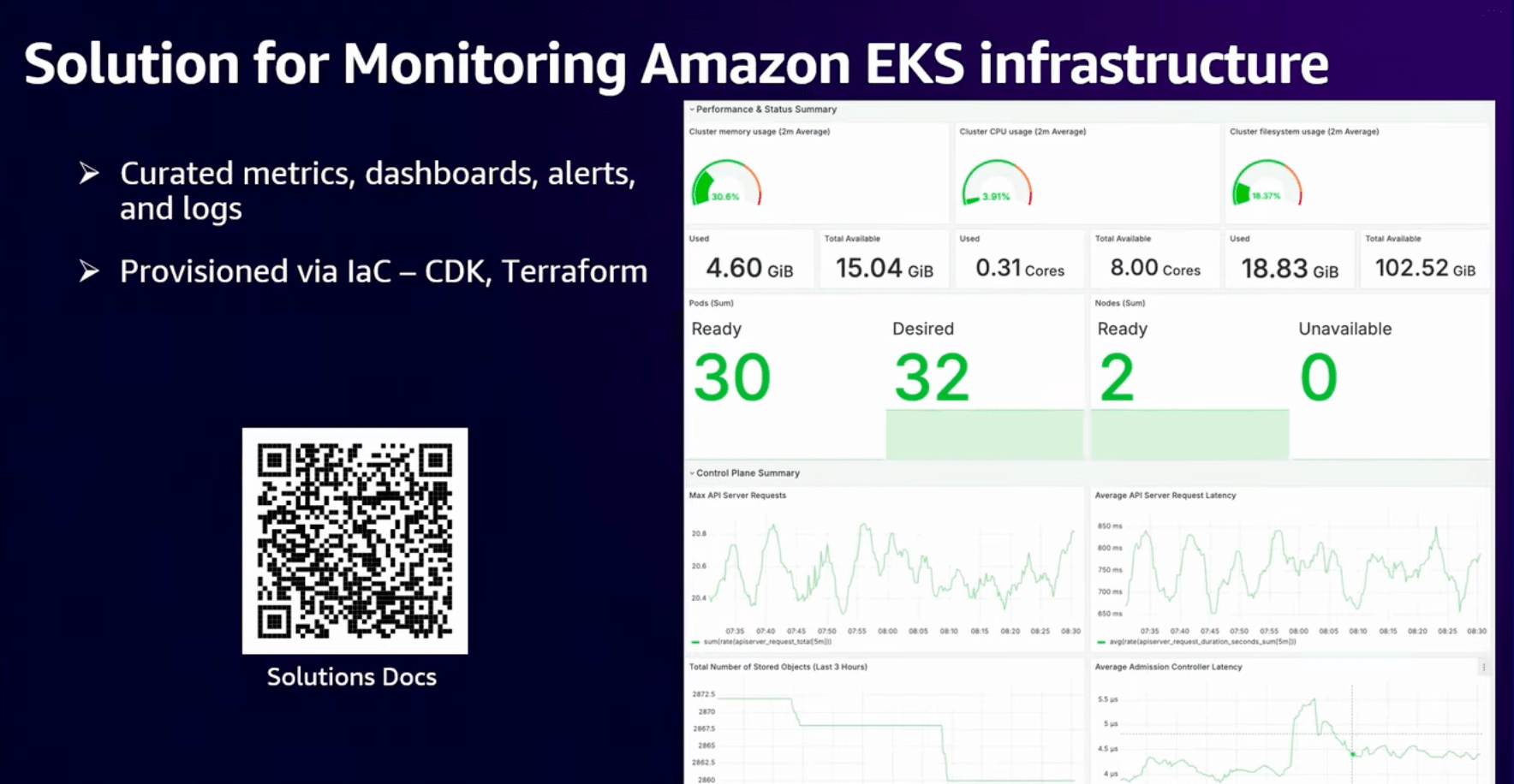
このダッシュボードには11個ほどの異なるダッシュボード、パフォーマンス、ヘルスチェック、EKSクラスター内のログが含まれているようでうす。
これにより、1からOSSを学ぶのではなく、開発者が必要としている部分に時間を割きつつ、監視の環境を整えることができそうですね。
AI
AIに関連する機能についても新機能があるようです。
OpenSearch Serviceでも既存の異常検知機能を持っていますが、新たに自然言語を持ちいたAIアシスタントのサポートと、自然言語クエリをサポートしたようです。
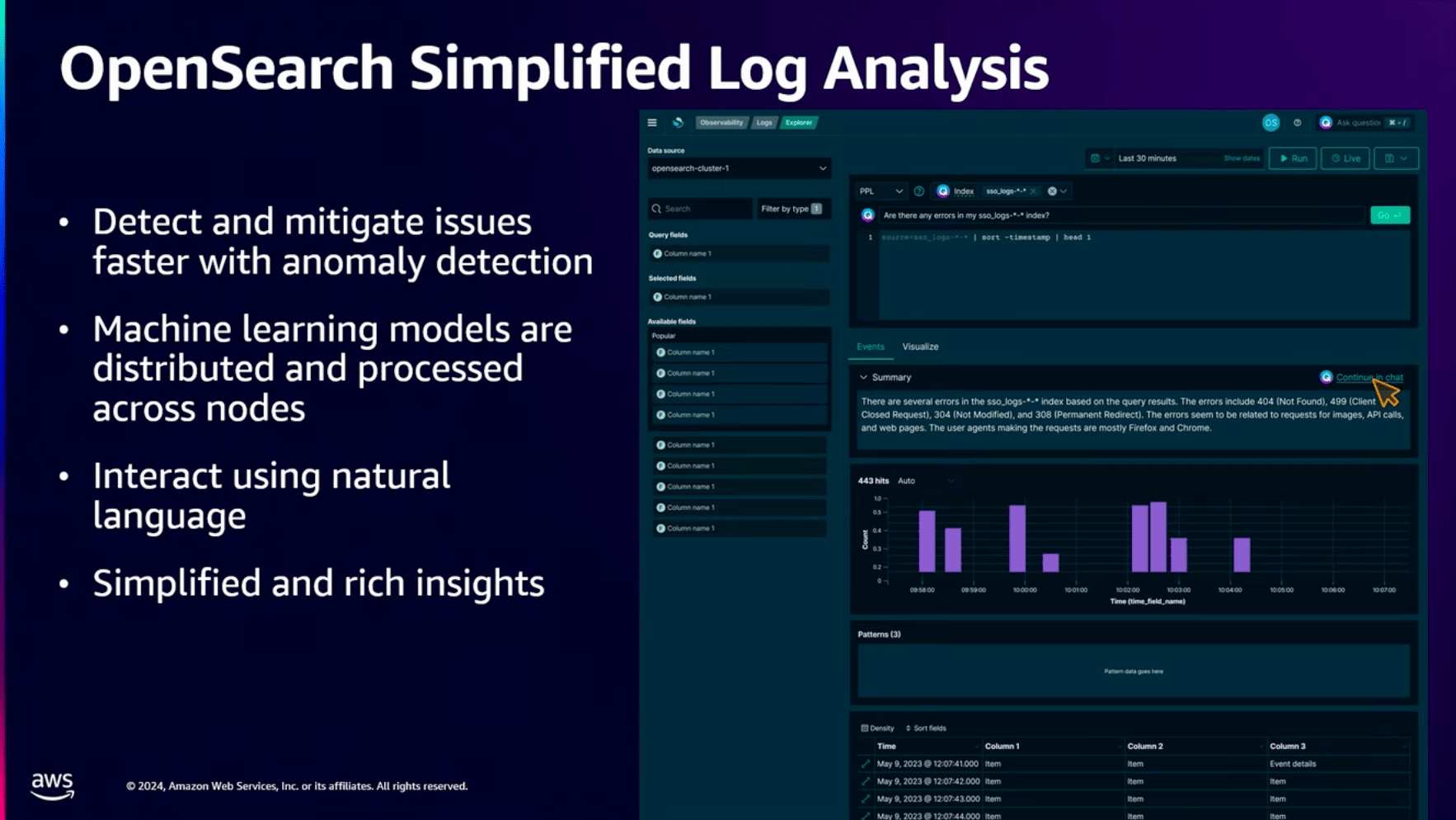
これはイメージしやすいですね。
例えば「最も多く見られるエラーはなんですか?」と自然言語で質問することで、自動でクエリを生成してデータを探してくれる機能です。
オープンソースコミュニティへの貢献
最後に、オープンソースコミュニティへの貢献についても語られていました。
2021年にAWSとオープンソースコミュニティによりOpenSearchが作られ拡大し続けています。
オープンソースコミュニティへの貢献を通じて世の中への貢献や自分たちの学びに繋がるようです。

まとめ
このセッションでは
- Amazon Managed Service for Prometheus
- Amazon Managed Grafana
- Amazon OpenSearch Service
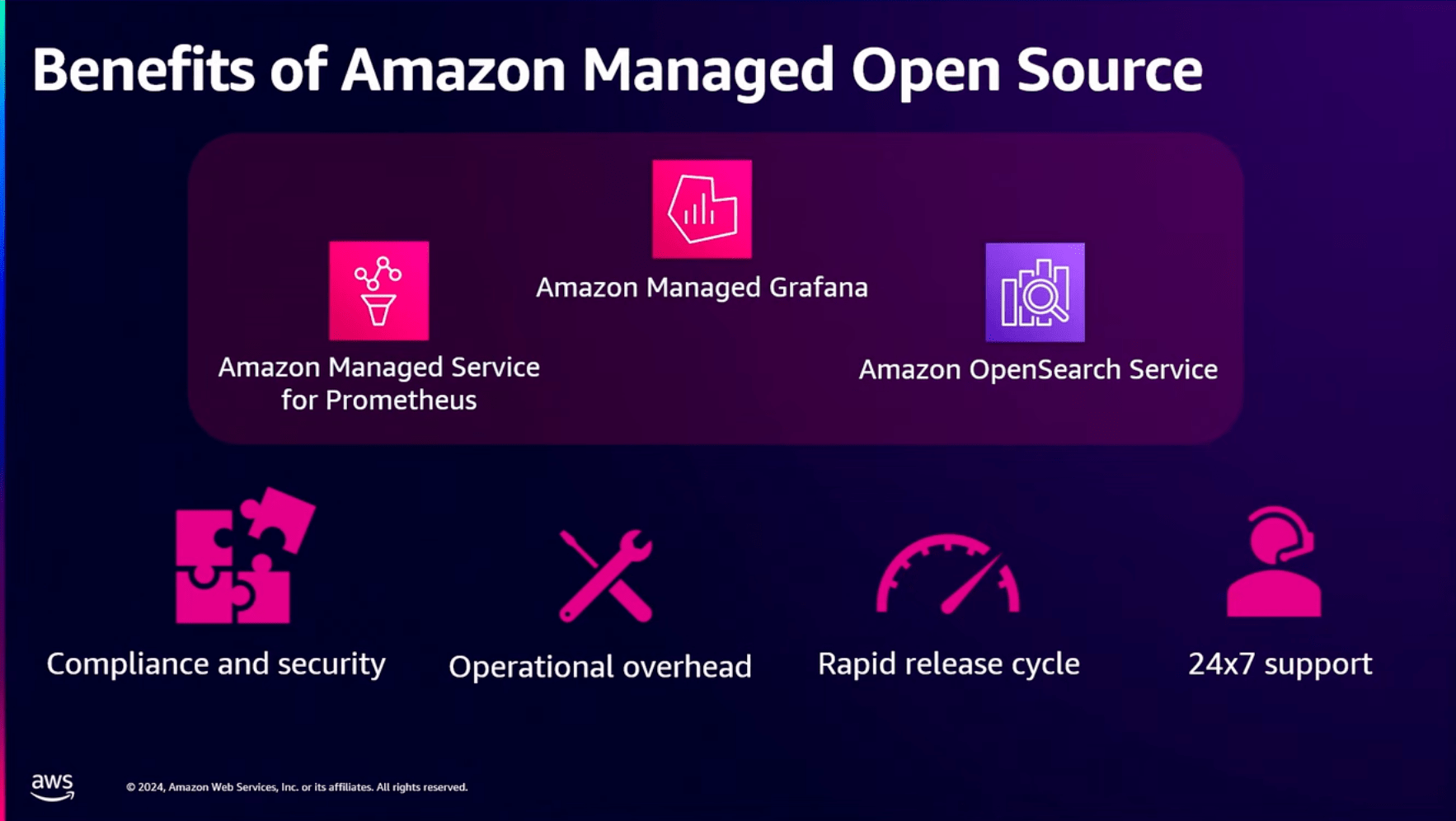
について語られました。
これらのマネージドサービスを利用することで、利用者は
コンプライアンス、セキュリティ、運用のオーバーヘッド、迅速なリリース、サポート
など様々な課題をAWSのマネージドサービスを使って解決する方法が理解できました。
おわりに
少し長くなてしまいましたが、OSSに代わるAWSのマネージドサービスを使ったオブザーバビリティの一例を知ることができました。
今回紹介したサービス以外にも「オブザーバビリティ」という単語からはいくつかのAWSサービスが思い浮かびます。
現在OSSを使っている or 使う予定で、インフラの管理の複雑さや、各ソフトへの学習コストなどに頭を悩ませている方には参考になるセッションだと思いました。





