
俺の大胸筋が THE BigQuery

概要
前半はBigQueryの機能紹介、後半がなぜ俺の大胸筋がBigQueryなのかを根拠を交えて解説します。
そもそも私が元々トレーナー(筋トレ)をしていて、現在エンジニアをしています。
どちらも経験した身として、フィットネスとITの親和性について気づき、今回の記事のように自身の経験から来る情報を発信しています。
考え方次第で、両極端にあるような物事の共通性について発見することができます。
※ アイキャッチ画像はDALL-E3モデルの生成AIで作成しており、ブログでの利用は問題ございません。
BigQueryとは
Google BigQuery(BigQuery)は、データの管理と分析を支援するフルマネージドのデータウェアハウスです。
BigQuery のサーバーレスアーキテクチャにより、インフラストラクチャ管理なしで、SQLクエリを使用した高度な分析が可能です。
BigQuery は、数テラバイト規模のデータに対して数秒で、ペタバイト規模のデータに対して数分でクエリを実行できる、スケーラブルで分散型の分析エンジンです。
また、外部ソースからデータを読み取りながら、ストリーミングでデータの継続的な更新をサポートする連携クエリも使用できます。
BigQueryにより、ビジネスの俊敏性を高め、分析情報をいち早く取得することができ、様々な課題解決を行うことができるデータ駆動型の意思決定を加速させることにつながります。
つまり、超有能なデータ分析界の重鎮ということです。
BigQueryの特徴
まずは、BigQueryのメリット/特徴を挙げていきます。
その後、なぜ俺の大胸筋がBigQueryなのかという根拠をお伝えしていきます。
-
概要
- フルマネージドのエンタープライズデータウェアハウス
- 機械学習、地理空間分析、BIなどの組み込み機能を提供
- サーバーレスアーキテクチャによるインフラ管理不要
-
パフォーマンス
- テラバイト規模のデータに対して数秒でクエリ実行
- ペタバイト規模のデータに対して数分でクエリ実行
- スケーラブルで分散型の分析エンジン
-
データ処理
- 外部ソースからのデータ読み取りとストリーミング更新をサポート
- カラム型ストレージ形式による最適化
- ACID準拠のトランザクションサポート
-
可用性と拡張性
- 複数ロケーションへの自動データ複製
- ストレージとコンピューティングの独立したスケーリング
- リソース競合のない設計
-
開発者フレンドリーな設計
- 多様なプログラミング言語とAPIのサポート
- ODBCとJDBCドライバによるサードパーティツールとの連携
-
主な利用者
- データアナリスト、データエンジニア、データウェアハウス管理者、データサイエンティスト
このように、データ分析のパフォーマンスと拡張性のメリットが詰まったサービスがGoogle BigQueryなのです。
なぜ俺の大胸筋がBigQueryなのか
名前がフィットしすぎている
まず、1つ目に言えることはBigQueryという名前の響きと筋肉の相性が良すぎるという点です。
これは、他のサービスで言い換えるとBigQueryが1番フィットしているとわかります。(以下候補だったアイデア)
- 俺の大胸筋がCloud Run
- 俺の大胸筋がGlobal Lord Balancer
- 俺の大胸筋がDataprep
- 俺の大胸筋が共有VPC
どうでしょう。
やはり他のサービスよりも俺の大胸筋がBigQueryが1番しっくり来ることがわかります。
インフラ管理なしの自動スケールが可能
論理的な理由の1つとして、100%サーバレスな実行環境が大胸筋との共通点として挙げられます。
まず大胸筋とはどのような筋肉か考えてみましょう。
細かく細分化すると、大胸筋は3つの部位に分けることができます。 それは上部・中部・下部といった筋繊維です。
上部・中部・下部に分かれているように、BigQueryもストレージ、クエリ処理、結果出力といった複数の機能が連携して働いています。
それぞれが調和して動作することで、強力なパフォーマンスを発揮するのです。
そして主に上半身の運動で、前に押す動作、さらには腕を挙上する動作で、大胸筋は主に使われます。
ではこれはインフラ管理なしの自動スケールと何が関連してくるでしょうか?
大胸筋は、重いものを持ち上げようとするとき自動的に必要な力を調整します。
軽いペットボトルを持ち上げるときは最小限の力で、重いバーベルを持ち上げるときは最大限の力を発揮します。

そして、BigQueryは、小さなデータセットに対しては最小限のリソースを使用し、ペタバイト級のデータに対しては膨大なリソースを自動的に割り当てます。
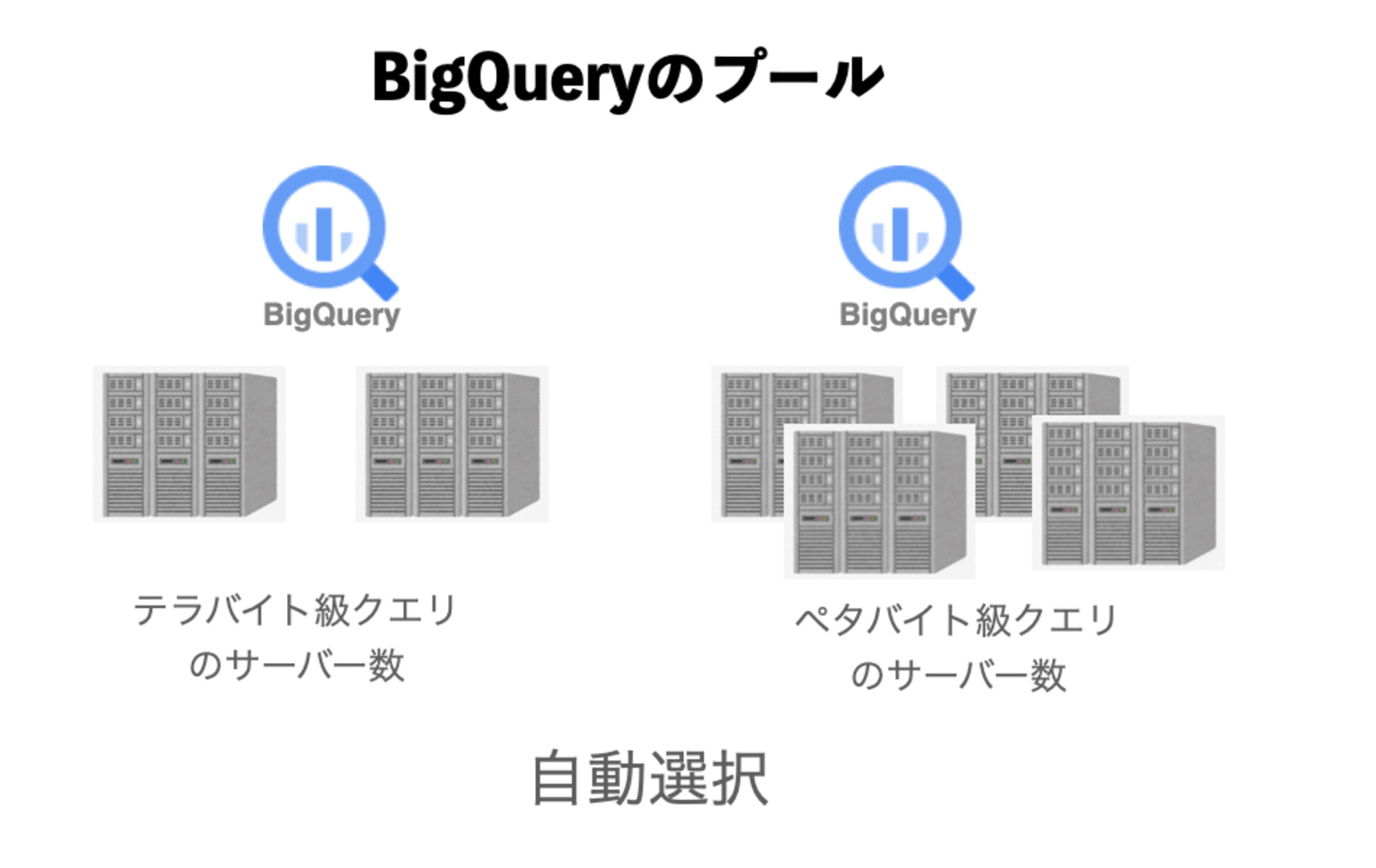
つまり、どちらも自動スケーリングという意識をしない効率化されたインフラ/筋繊維の活動と言っていいでしょう。
さらに、ベンチプレス(大胸筋を鍛える種目)は、BigQueryのクエリ最適化のような仕組みを実現させます。
適切なフォーム(ブリッジや挙上位置など)でベンチプレスを行うことで、大胸筋を効率的に鍛えられるように、BigQueryも最適化されたクエリで、データを効率的に持ち上げる(抽出する)ことができるのです。
よって、BigQueryを使いこなすことは、データ分析の世界で大胸筋を鍛えるようなものだと言えると感じざるおえません。
データという重みを軽々と持ち上げ、ビジネスの筋肉を鍛え上げていくのです。
高速クエリ処理能力と大胸筋の爆発的パワー
BigQueryがテラバイトやペタバイト規模のデータを数秒から数分で処理できる能力は先程お伝えした通りです。
巨大なプールで行う並列処理や列指向ストレージなどの機能から来るメリットだとも言えます。
そして、大胸筋は身体の中でもトップ5に入る大きい筋肉です。
筋肉の力/パワーは横断面積に比例するため、大胸筋は瞬間的に大きな力を発揮できる能力もあるのです。
筋線維にもタイプがあり、速筋と遅筋という大きく2つの種類に分かれます。

爆発的パワーが必要であれば速筋繊維を鍛え、持久力的能力が欲しければ遅筋を鍛えます。
BigQueryのクエリ処理速度は爆発的であると言え、速筋繊維に近いです。
そして、大胸筋の速筋/遅筋の筋比率は、調べたところ若干速筋繊維の方が多い模様です。
ただし、人によって筋比率は大きく異なるので、あくまでも今回の内容にこじつけるための情報として咀嚼してください。(エビデンスはありません)
1つ言えることは、両者とも短時間で大きな仕事をこなす能力があるという点に共通性が存在します。
なぜなら、上半身(大胸筋)を効率よく短時間で鍛えるならベンチプレスが採用され、高速なSQLクエリと言ったらすぐにBigQueryが思い出されるからです。(エビデンスは私室井)
まとめ
今回の記事の題名にある俺のBigQueryの俺とはあなたです。
1人称はあなたです。 日々の鍛錬によりBigQueryのような大胸筋、そしてBigQueryのような健康、そしてBigQueryのような脳を手に入れましょう



