OneDrive コネクタでデータファイルを Snowflake に同期してみた #Fivetran

はじめに
Fivetran では、ファイル転送用のコネクタとして OneDrive コネクタを提供しています。OneDrive コネクタでデータファイルを Destination(Snowflake)に同期してみましたので、その際の手順を記事としました。
OneDrive コネクタ
OneDrive コネクタについては、以下に記載があります。
コネクタの特徴
下図は公式ドキュメントからの引用ですが、削除のキャプチャや履歴モード、カラムのハッシュ化など一部対応していない項目もあるためご注意ください。
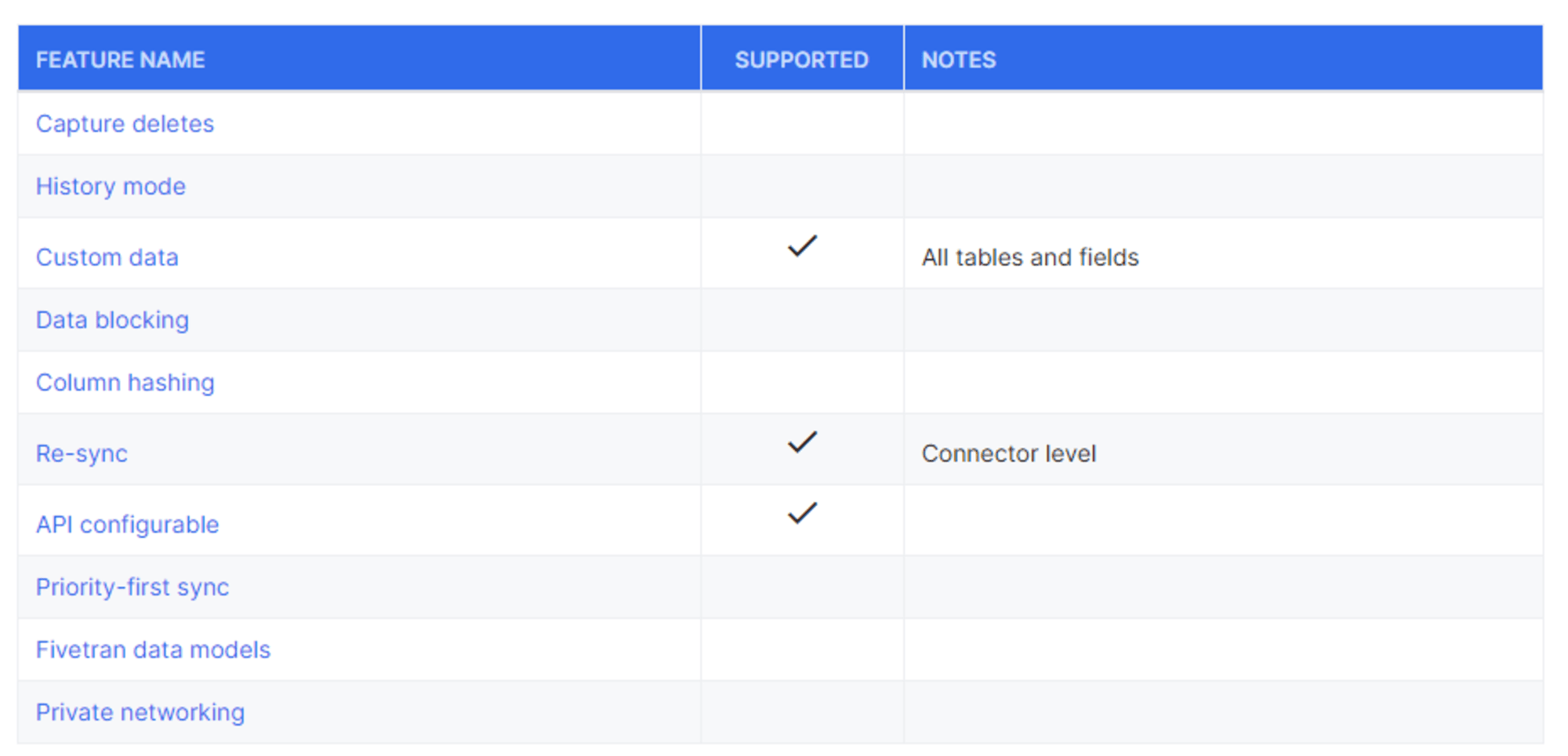
同期の概要
OneDrive コネクタでは、コネクタ作成時に指定したフォルダ内のデータファイルを同期します。この際の主な特徴は以下です。
- 同期はマジック フォルダー モードで行われます
- このモードでは、各データファイルが宛先に一意のテーブルとして同期されます
- 同じ列構成のデータであっても、ファイルが異なる場合は別のテーブルとして作成されます
- このモードでは、各データファイルが宛先に一意のテーブルとして同期されます
- Excel の場合は、各シートで異なるテーブルとして同期されます
- ただし、以下の場合は同期されません
- 空のワークシート
- ワークシートの最初の行全体が空、最初の行が空のカラム
- ただし、以下の場合は同期されません
- 指定のフォルダ内にネストされたフォルダがある場合は無視されます
- この場合は別にコネクタを作成する必要があります
- OneDrive コネクタでは増分同期がサポートされていません
- 前回の同期から変更があった(更新日時に変更があった)ファイルが次回の同期対象となります
- 同期毎に変更があったファイルのみを再インポートされます
- サポートされるファイルフォーマットとエンコーディング
宛先テーブル名
- 拡張子を除くファイル名で、コネクタ作成時に指定のスキーマにテーブルが作成されます
- 例:
sample.csvの場合SAMPLEの名称でテーブルが作成される
- 例:
- Excel の場合、ファイル名とシート名の組み合わせが宛先テーブル名として使用されます
- 例:
My Workings.xlsx内にSheet1とSheet2がある場合、以下のテーブルが作成されますMY_WORKINGS_SHEET_1MY_WORKINGS_SHEET_2
- 命名規則の詳細はこちらをご参照ください
- 例:
制約
- データファイルが Excel の場合、以下の拡張子がサポートされています
.xls,.xlsx,.xlsm
- ワークシートのハイパーリンク値は同期されません
- ワークシート上のピボットテーブルは同期されません
検証条件
ここでは以下の環境を使用しました。
- Microsoft 365(個人の無料プラン)
- Destination
- Snowflake
事前準備
Onedrive 側
Fivetran で同期対象となるデータファイルを格納するためのフォルダを作成しておきます。
Destinaiton
データの連携先には Snowflake を使用しました。Snowflake を Destination に設定する方法は、以下の記事をご参照ください。
Fivetran の設定
データファイルの用意
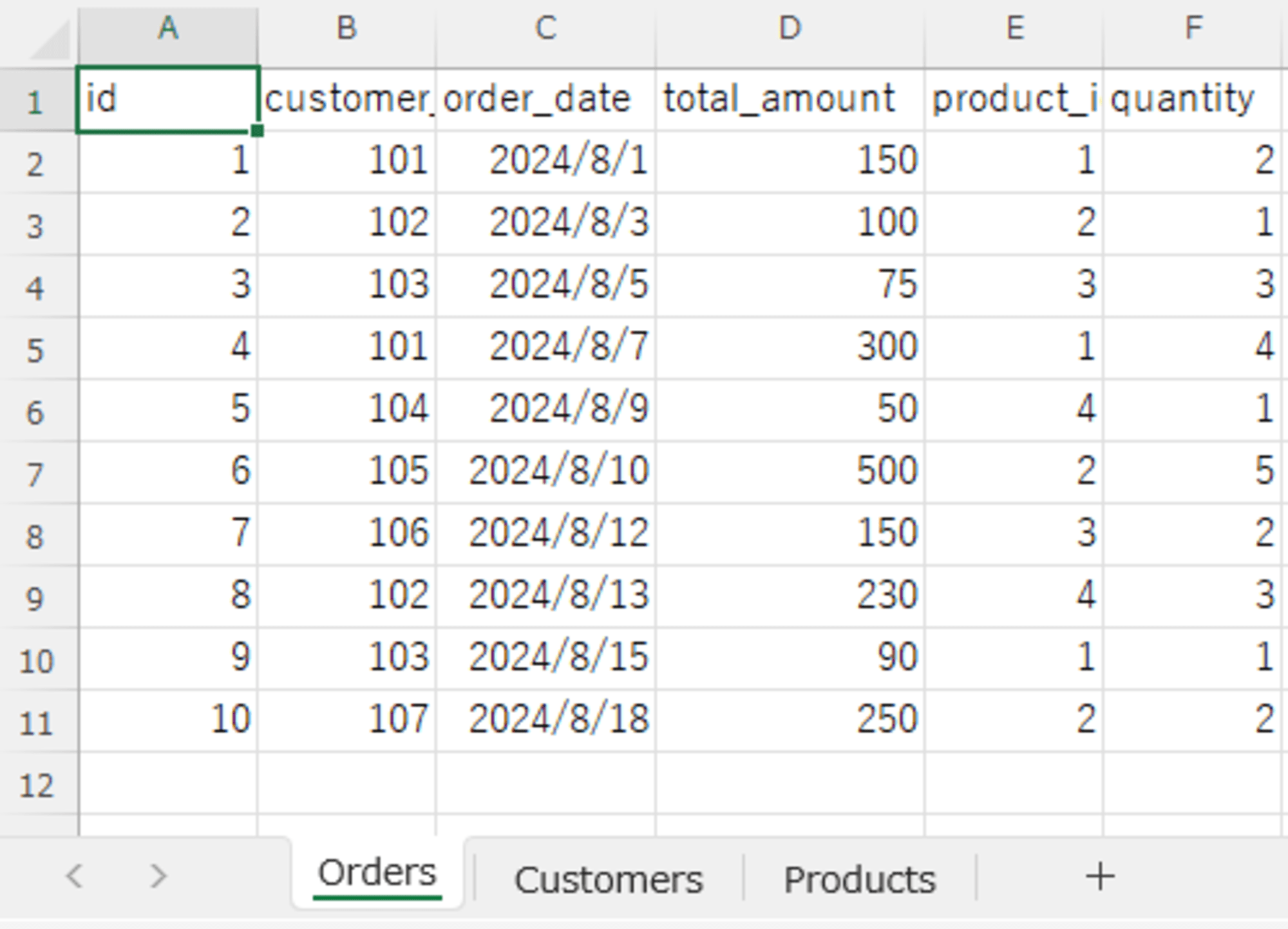
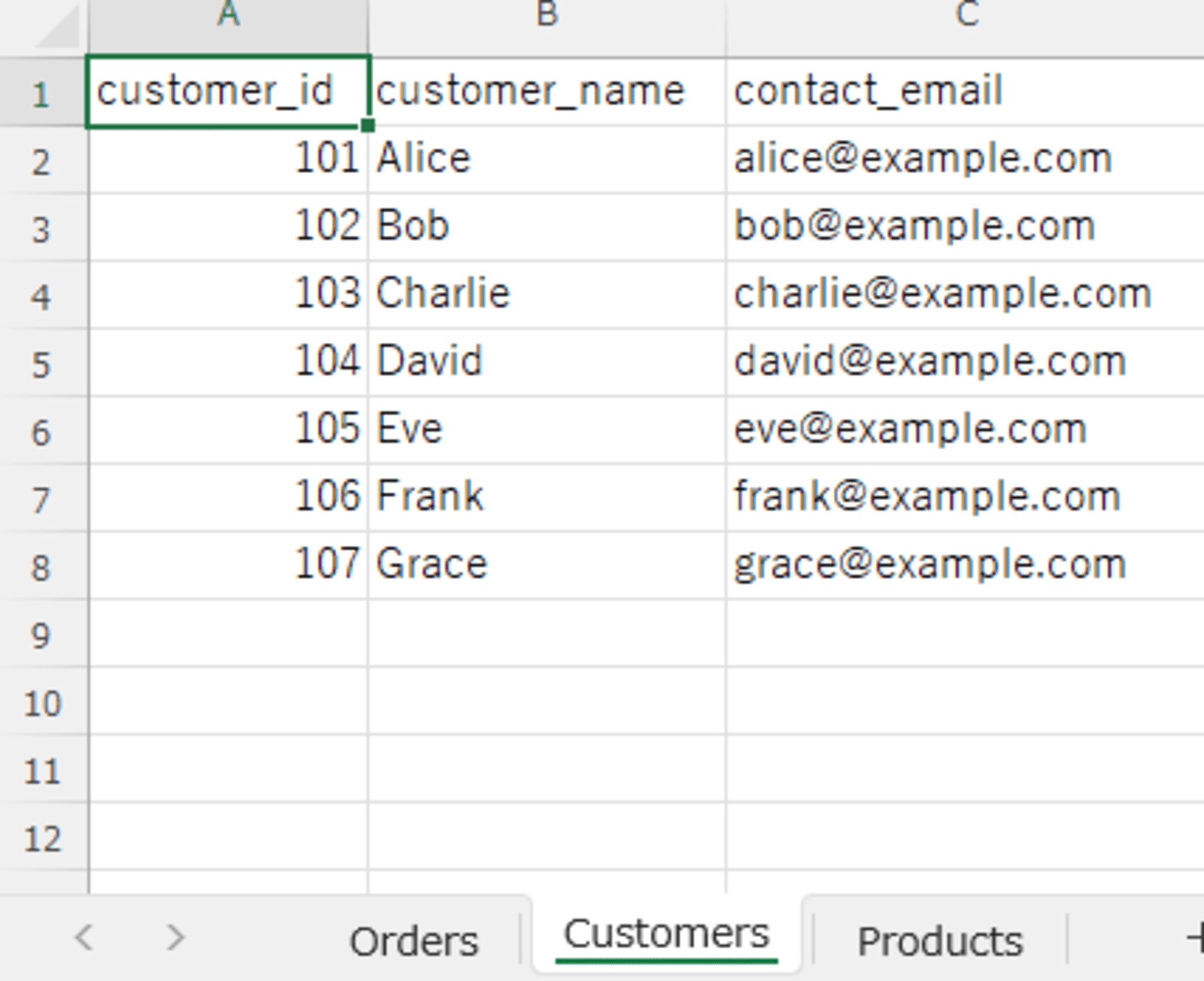
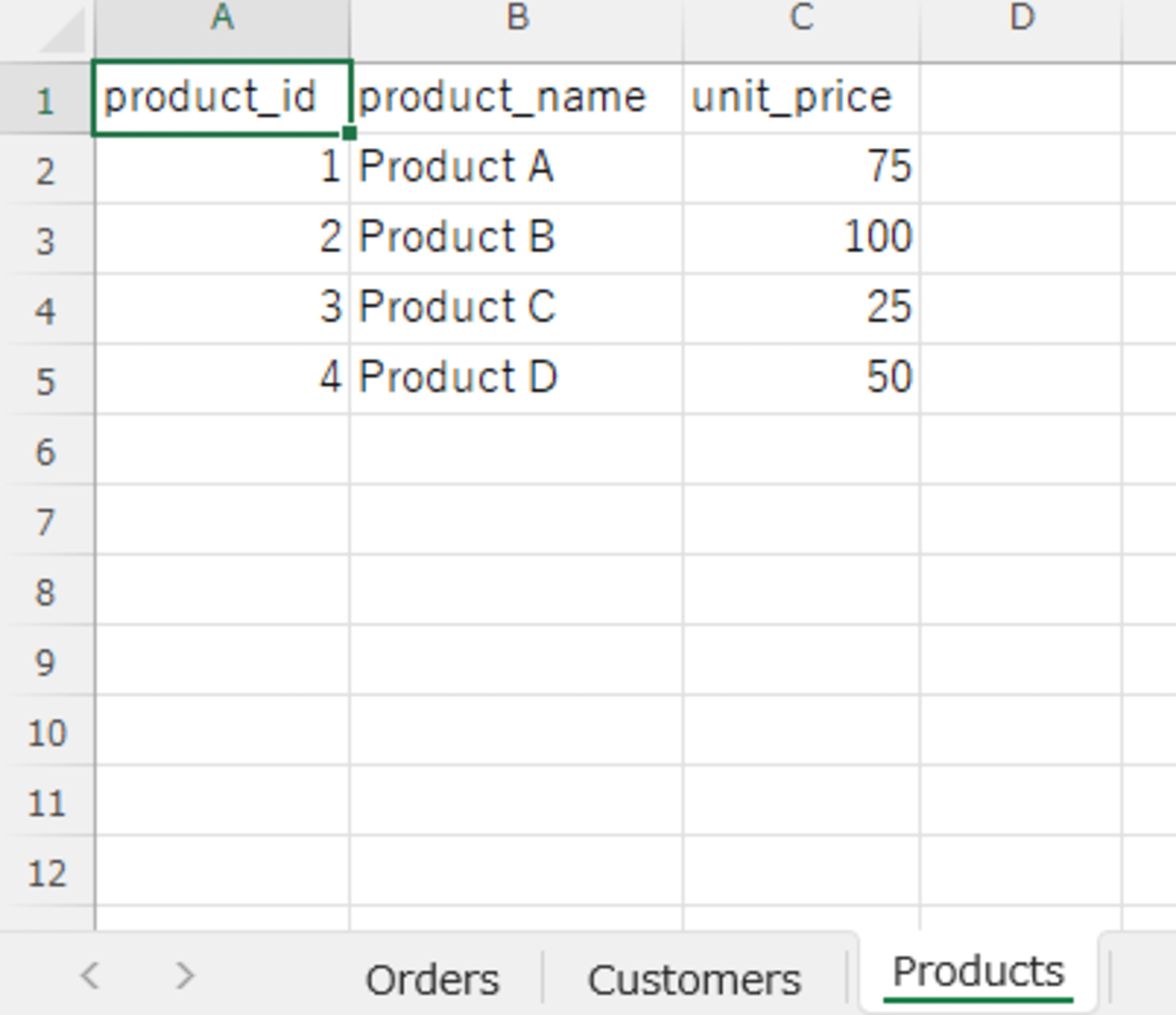
Snowflake に同期するサンプルのデータファイルとして3つのシートにデータのある Excel ファイル(SampleECData.xlsx)を用意しました。
- Orders シート
- Customers シート
- Products シート
このファイルを事前準備で作成した OneDrive 上のフォルダに追加しておきます。

コネクタの作成
Fivetran ダッシュボードから OneDrive コネクタを選択し Destination を指定します。
設定画面は下図のようになっています。
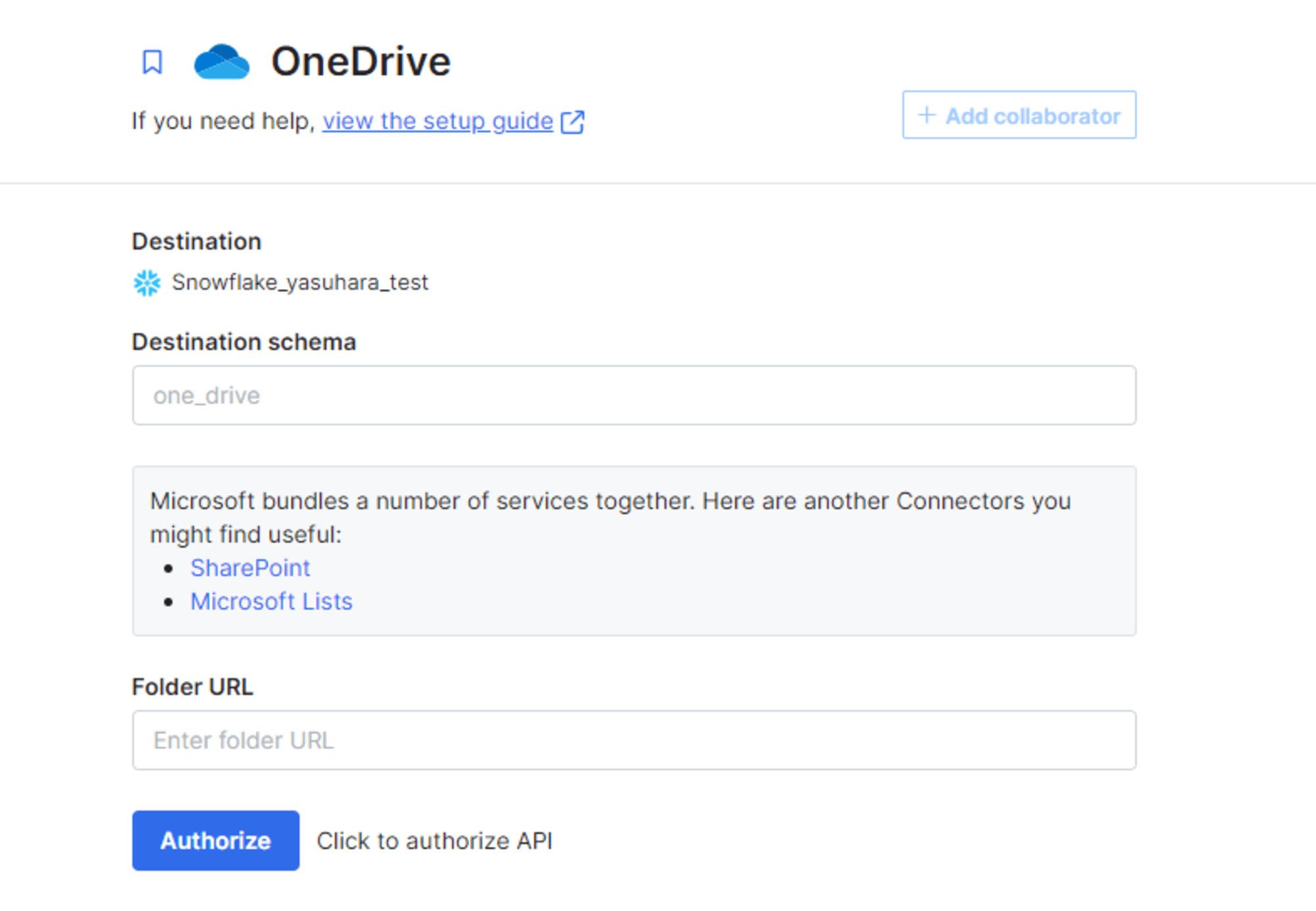
設定項目は以下です。
- Destination schema
- テーブルの作成先となるスキーマ名
- Folder URL
- OneDrive 側でデータファイルの保存先となるフォルダをブラウザで開いた際に表示されるURL
項目を入力後 [Authorize] をクリックします。必要に応じて対象の Microsoft アカウントにサインインし、アクセスを許可します。問題なければ下図の表示となるので、設定を保存し接続テストを行います。
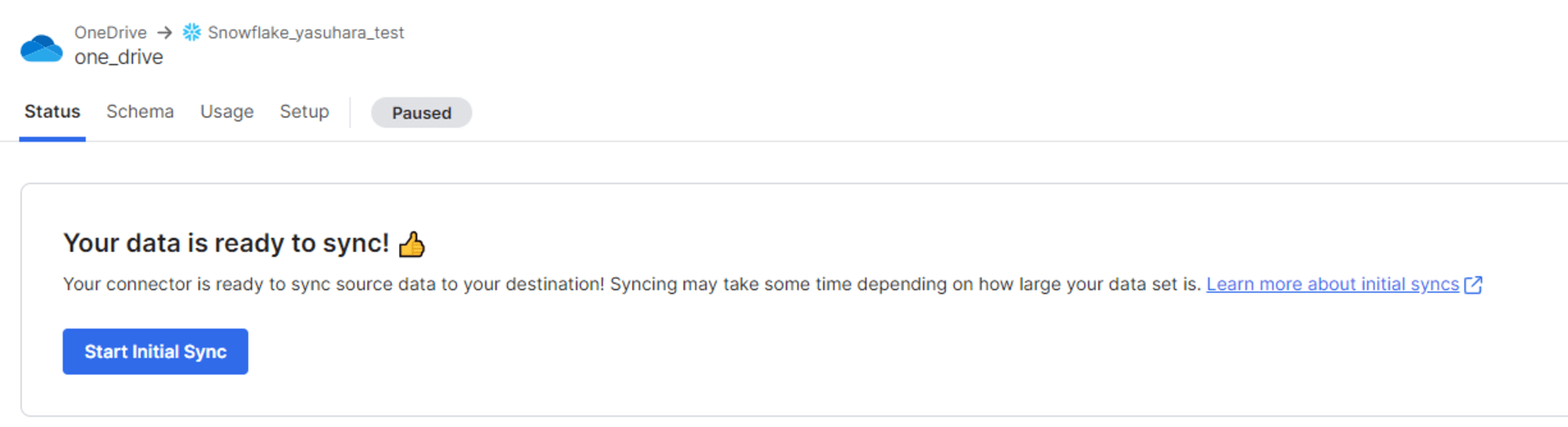
テストが完了すると初期同期を開始できるので、[Start Initial Sync] をクリックします。
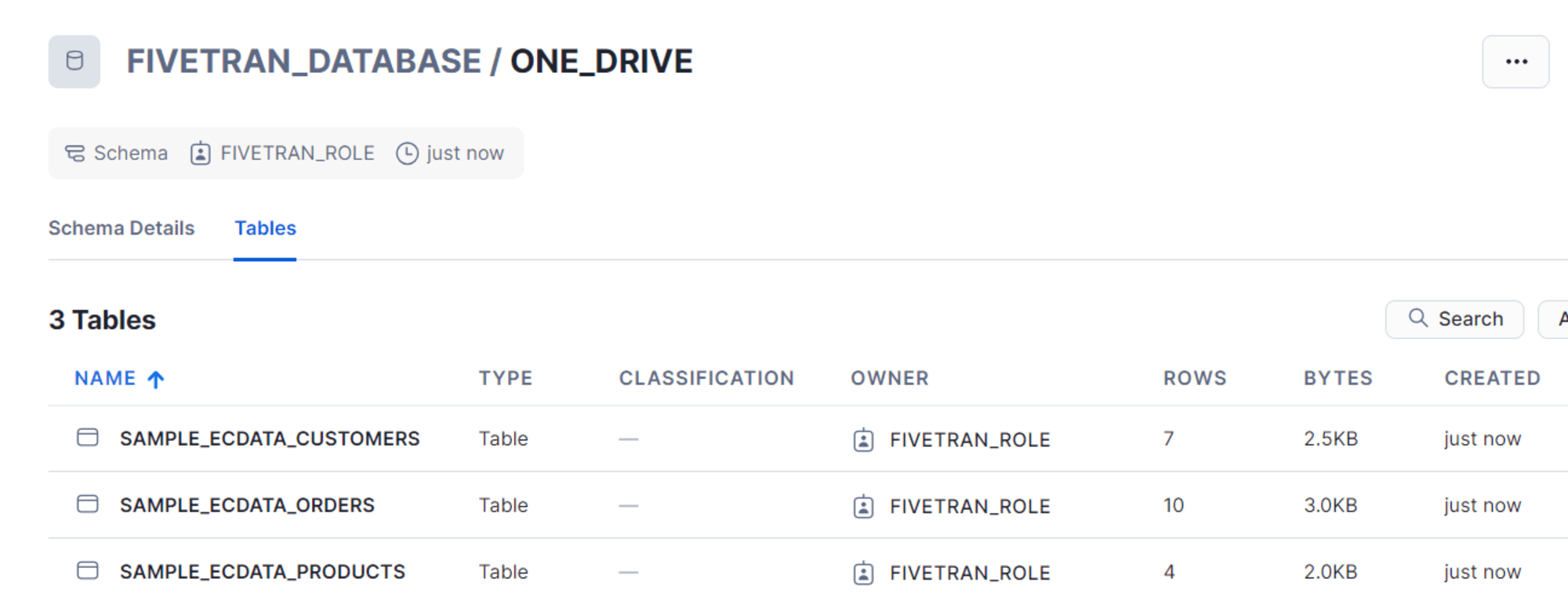
同期後、Snowflake 側を確認すると指定のスキーマ配下に命名規則に基づいてテーブルが作成されます。Excel ファイルでシートごとにデータがある場合は、シートごとにテーブルが作成されます。
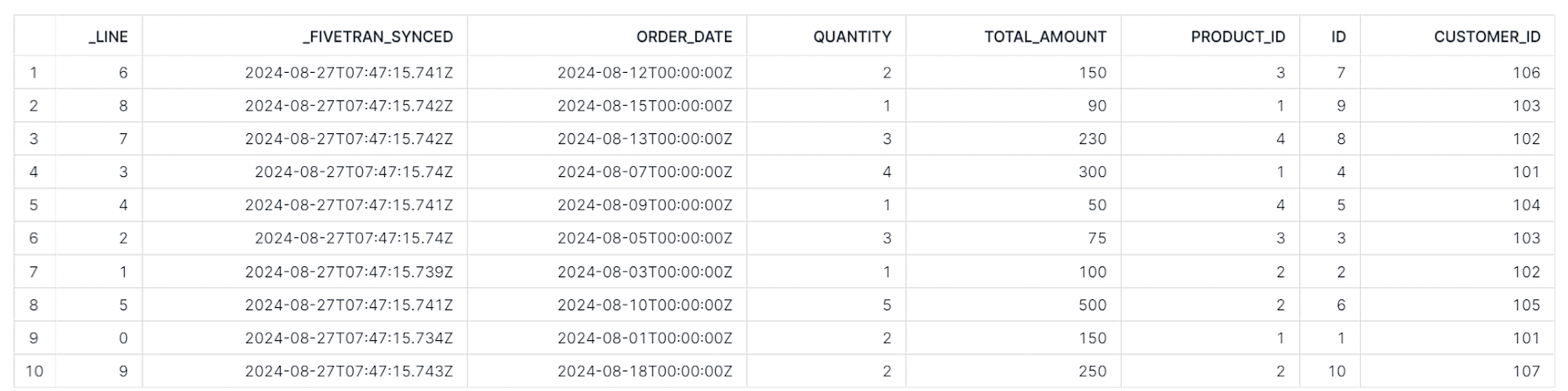
データを確認すると Fivetran 側でキー列を識別する_LINEと_FIVETRAN_SYNCEDのシステム列が追加される形で同期されていました。
データファイルの変更
既存ファイルの変更
変更対応として、既存のデータファイルの中身を更新し再度同期してみます。ここでは以下の変更を行います。
- Customers シート
- [contact_email] カラムを削除
- レコードを2件追加
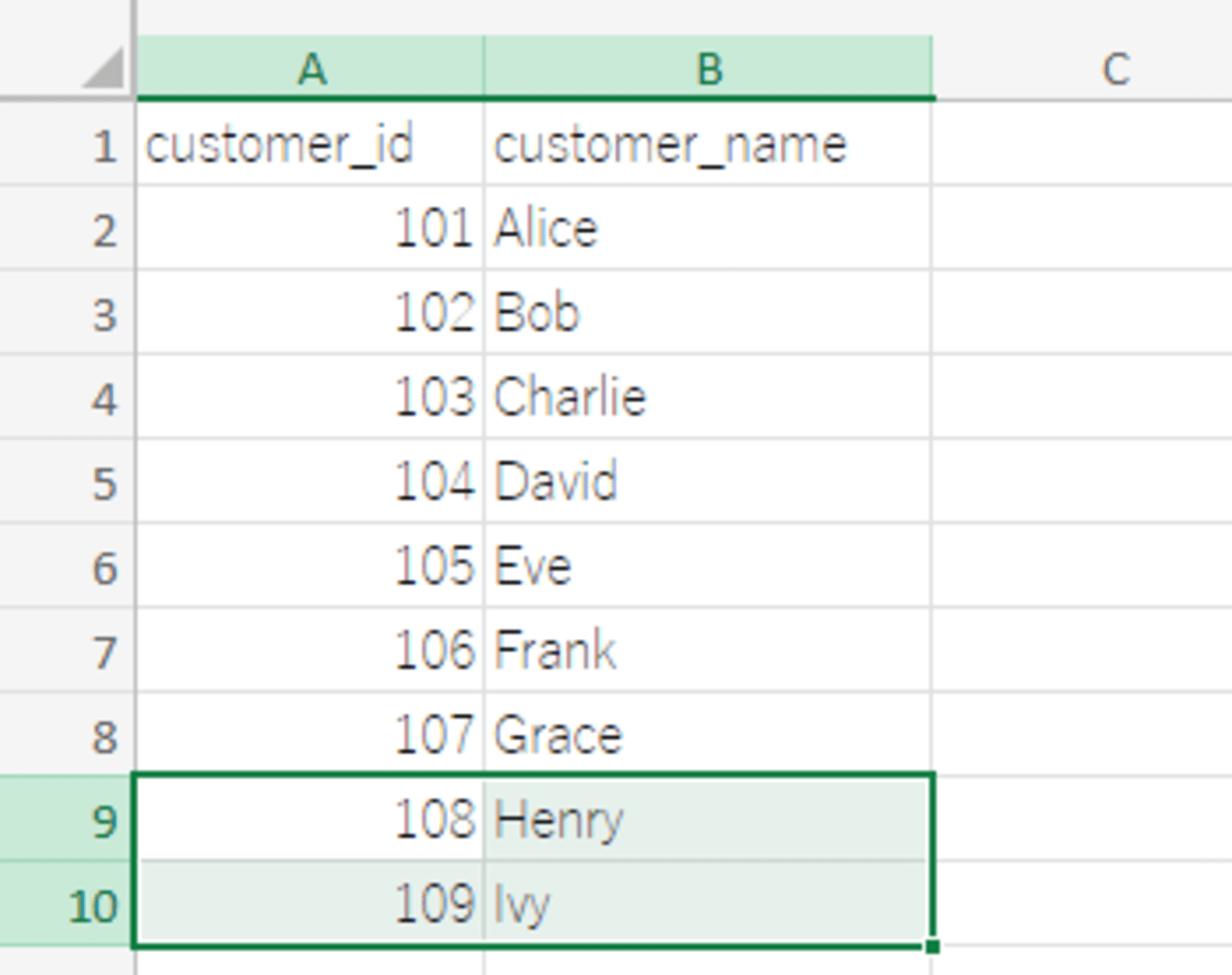
- Orders シート
- [new_column] カラムを追加
- [id]=10 の [quantity] カラムの値を更新
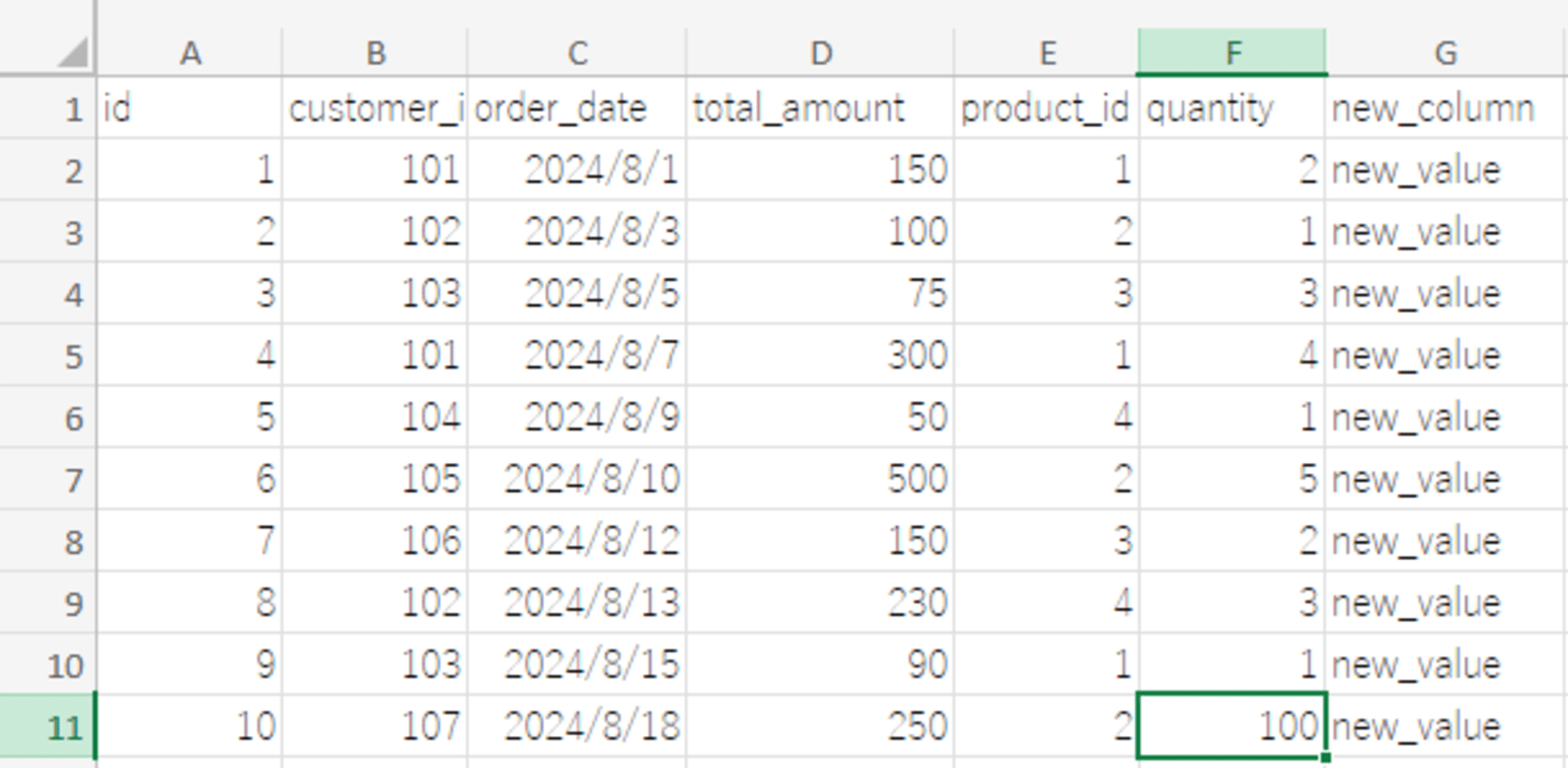
変更後ファイルを上書き保存し、再度同期を実行し Snowflake 側で確認します。
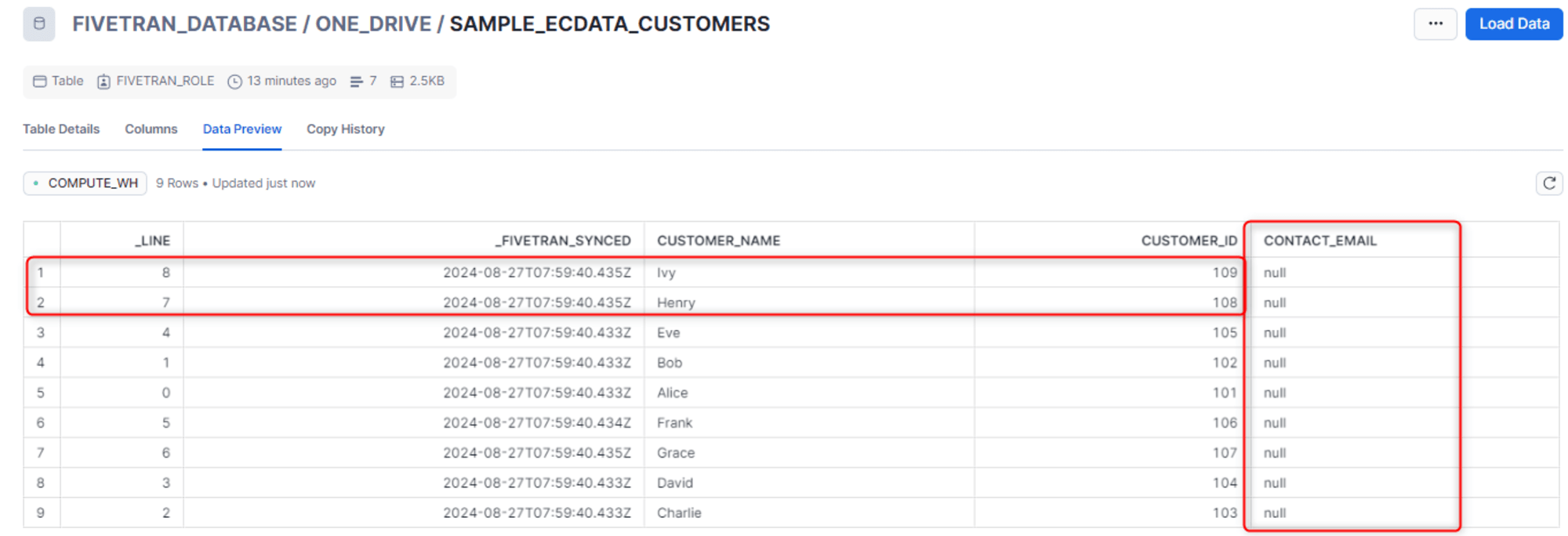
- CUSTOMERS テーブル
- Excel 側で削除したカラムの値に NULL が入る形で更新されます
- 新規レコードの追加も確認できます
- ORDERS テーブル
- 値の更新と新しいカラムの追加も確認できます
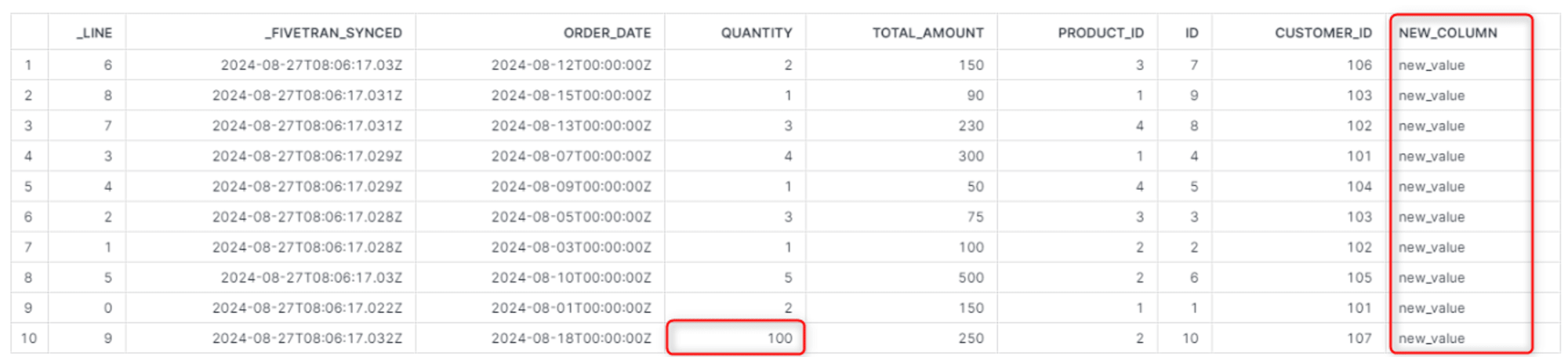
また、ここでは記載していませんが、ソース側でレコードを削除した場合、再インポートのため論理削除ではなくレコード削除後のテーブルとして生成されます。_LINEカラムも新たにレコード順にふり直されます。
再インポートの確認
上記までの状態から、さらに Orders シートにレコードを追加し同期を行います。
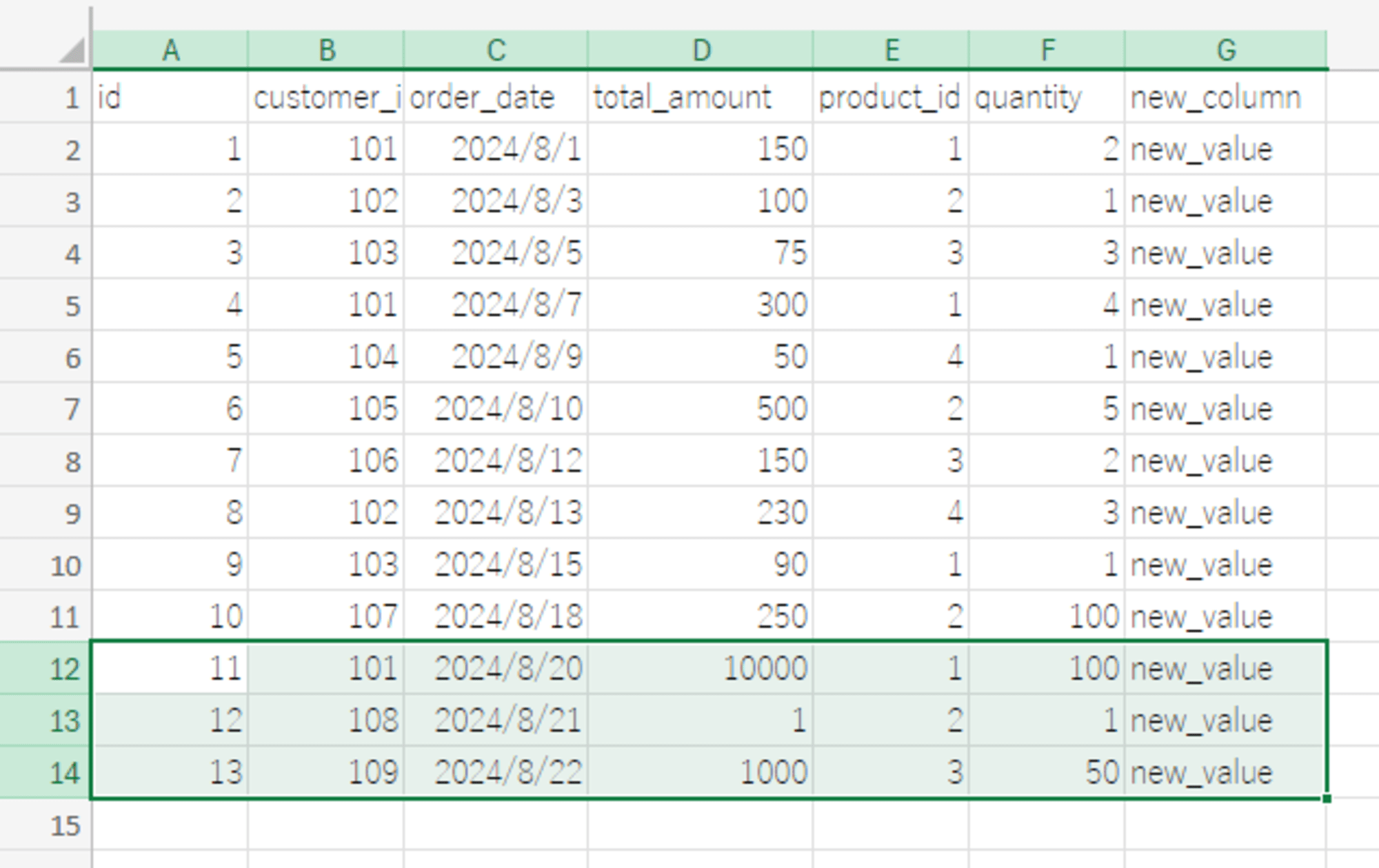
同期完了後、Snowflake 側でレコードの追加を確認できます。
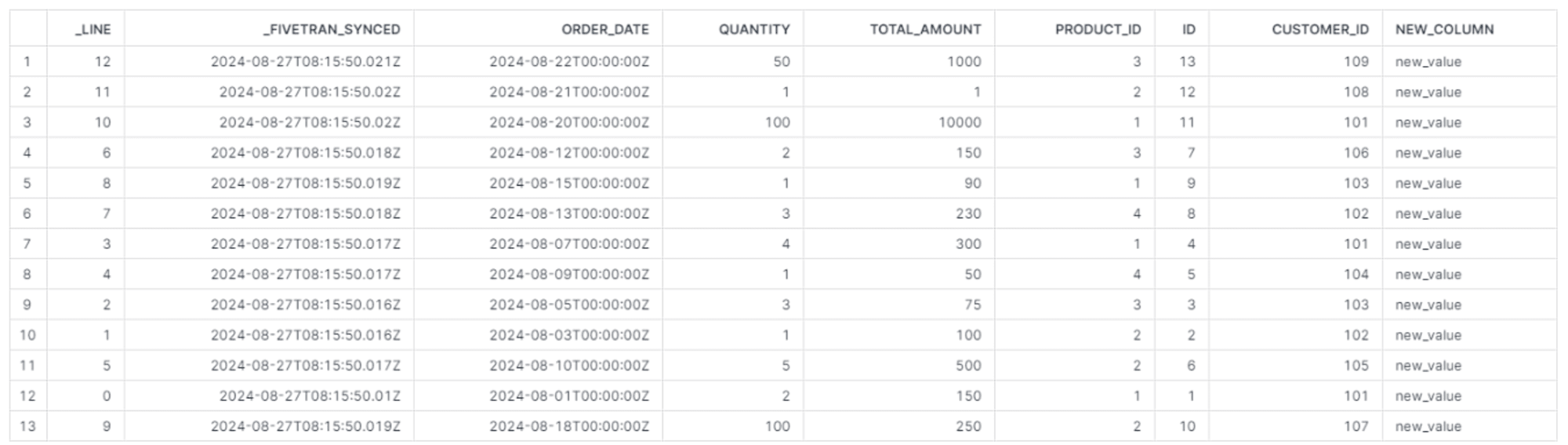
ここで_FIVETRAN_SYNCED カラムを見ると変更のない既存レコードもこの値が更新されていることが確認できます。他にも、変更を加えていない PRODUCTS テーブルについてもほぼ同時刻に更新されたことが確認できます。
同期の概要でも記載している通り、OneDrive コネクタは増分同期をサポートしておらず、変更があったファイルレベルで再度インポートを行います。そのため、変更があったシート内の変更がなかったレコードや、そもそも変更がなかったシートであっても各レコードの更新日時が最新化されています。
再インポートによる更新の場合、増分更新よりも多くの MAR が発生するためご注意ください。
ファイルの追加
既存ファイルとは別の以下のファイルをそれぞれ追加して同期を行ってみます。
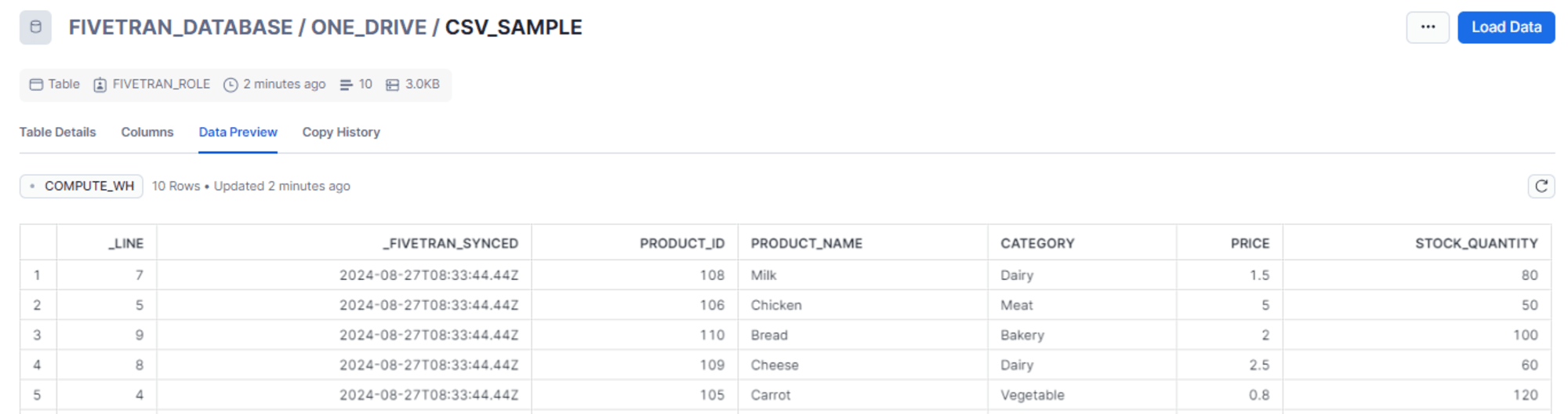
ProductID,ProductName,Category,Price,StockQuantity
101,Apple,Fruit,0.50,150
102,Banana,Fruit,0.30,200
103,Orange,Fruit,0.60,180
104,Broccoli,Vegetable,1.20,100
105,Carrot,Vegetable,0.80,120
106,Chicken,Meat,5.00,50
107,Beef,Meat,8.50,40
108,Milk,Dairy,1.50,80
109,Cheese,Dairy,2.50,60
110,Bread,Bakery,2.00,100
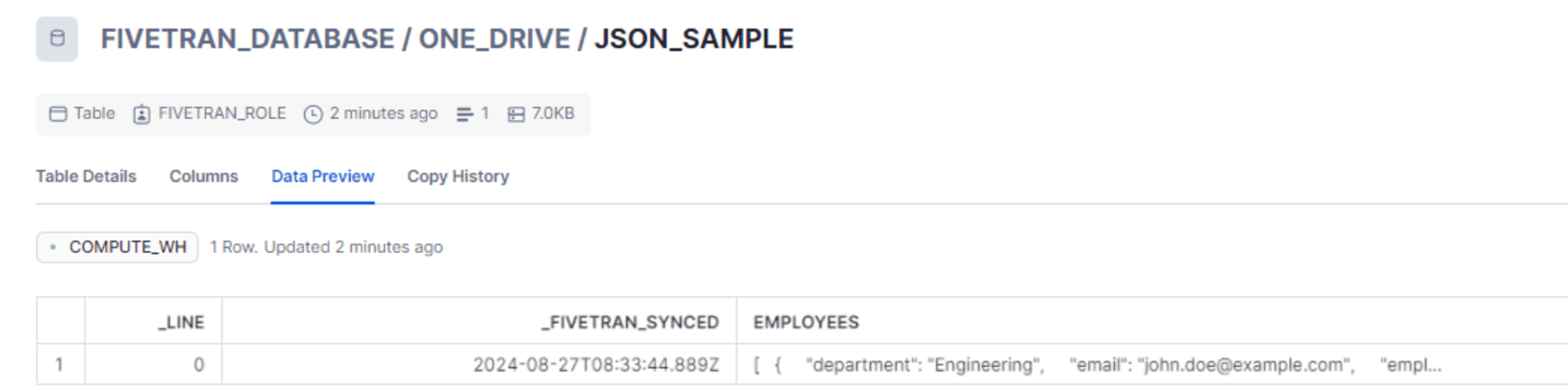
{
"employees": [
{
"employee_id": 1,
"first_name": "John",
"last_name": "Doe",
"department": "Engineering",
"email": "[email protected]",
"salary": 75000,
"is_full_time": true
},
{
"employee_id": 2,
"first_name": "Jane",
"last_name": "Smith",
"department": "Marketing",
"email": "[email protected]",
"salary": 68000,
"is_full_time": true
},
{
"employee_id": 3,
"first_name": "Emily",
"last_name": "Johnson",
"department": "Sales",
"email": "[email protected]",
"salary": 62000,
"is_full_time": false
}
]
}
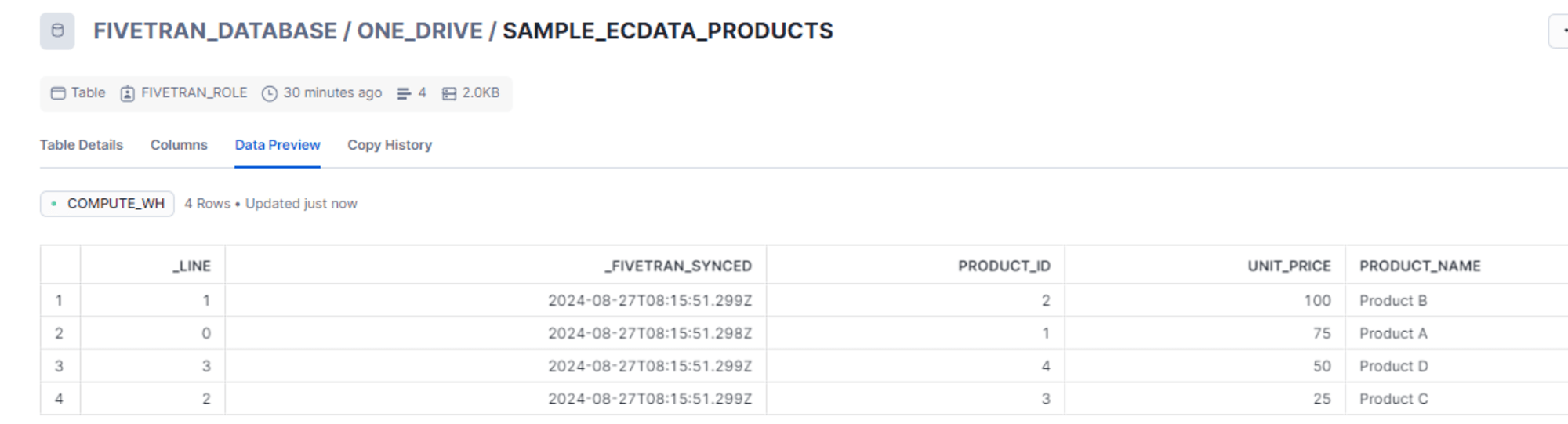
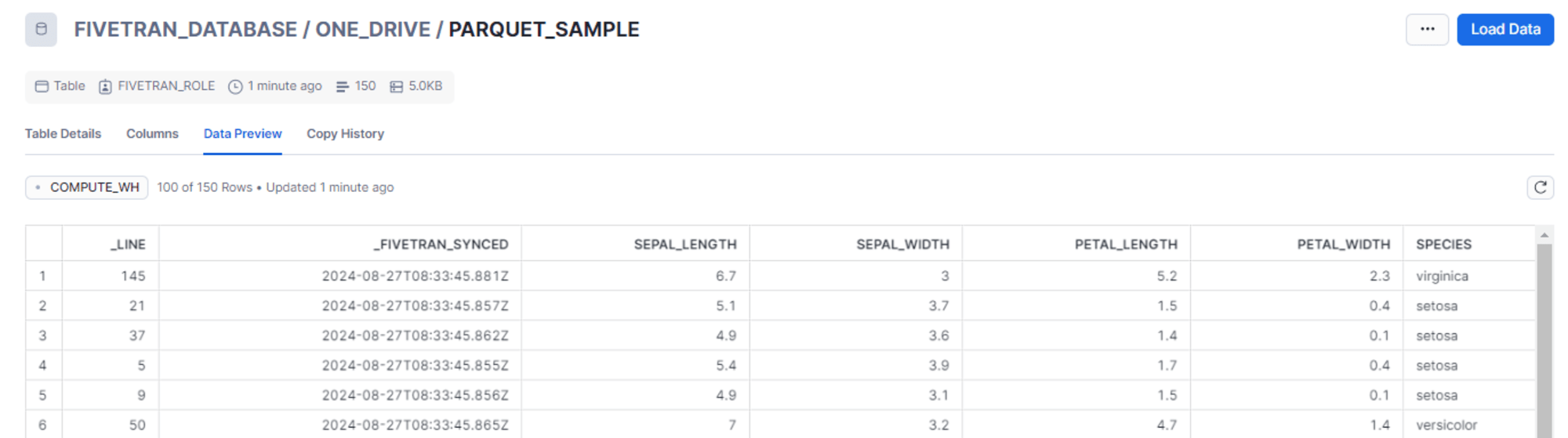
- parquet_sample.parquet
- iris データセットのカラム名のドットをアンダースコアとし parquet 形式に変換したもの
同期後、Snowflake で確認します。
- csv_sample.csv
- json_sample.json
- parquet_sample.parquet
日本語のファイル名やカラム名を含む場合の注意点
以下のような日本語のカラム名からなる顧客リスト.csv というデータファイルを同期するとします。
顧客ID,名前,メールアドレス,電話番号,住所,購入回数
1,佐藤太郎,[email protected],080-1234-5678,東京都新宿区1-1-1,5
2,鈴木花子,[email protected],080-2345-6789,大阪府大阪市2-2-2,3
3,高橋一郎,[email protected],080-3456-7890,愛知県名古屋市3-3-3,8
4,田中美咲,[email protected],080-4567-8901,福岡県福岡市4-4-4,2
5,伊藤健一,[email protected],080-5678-9012,北海道札幌市5-5-5,6
同期後、Snowflake で確認すると下図のようになります。テーブル名とカラム名が一部意図するものとはなっていません。

これはこのコネクタに限らず、以下に記載がある Fivetran 側の仕様によるもので、非 ASCII 文字は音訳に置き換えられためです。この際、特に漢字を含む場合は日本語として意図する形で変換されないため、予め英語形式のカラム名を用意しておくか、DWH 内での整形が必要です。
さいごに
Fivetran の OneDrive コネクタでデータファイルを Snowflake に同期してみました。再インポートによる注意点はありますが、Excel などのデータファイルも手軽に連携できる点は強みだと思います。こちらの内容が何かの参考になれば幸いです。


