
Amazon DataZoneでデフォルトのデータレイクプロファイルで既存のS3 Bucketと連携しAthenaでクエリしてみた

はじめに
データ事業本部ビッグデータチームのkasamaです。Amazon DataZoneのデフォルトのデータレイクプロファイルでは、DataZoneで作成したリソースのみにアクセス範囲が制限されています。そのため、既存のS3 BucketはデフォルトデータレイクプロファイルではAthenaで参照できない課題がありました。
既存のS3 BucketをDataZoneと連携させ、Athenaで参照するには、カスタムブループリントを使用して環境を構築する方法と、デフォルトのデータレイクプロファイルで構築した環境のIAM Roleポリシーに権限を追加する方法があります。
比較的容易に設定できる後者の方を試したいと思います。ただIaCで管理したいとなるとカスタムブループリントの方が良いと思います。
事前準備
Admin IAM Role
以降の作業は全てAdministratorAccessポリシーを持つ、IAM Roleで作業します。
作成したIAM RoleでGlue Data CatalogをcreateできるようにAWS Lake FormationのAdministrative roles and tasksからPermissionをGrantします。同様にData lake administratorsで管理者として登録しておきます。
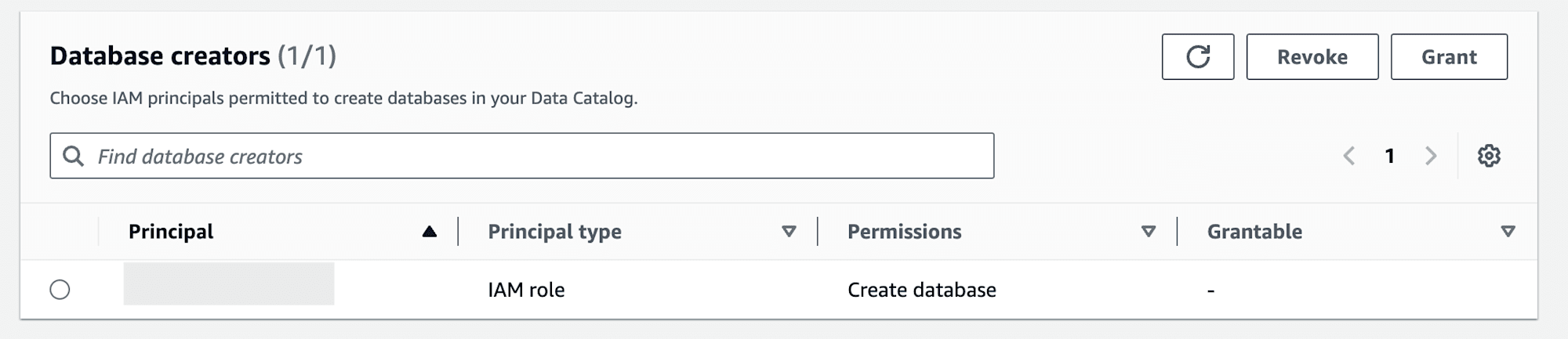
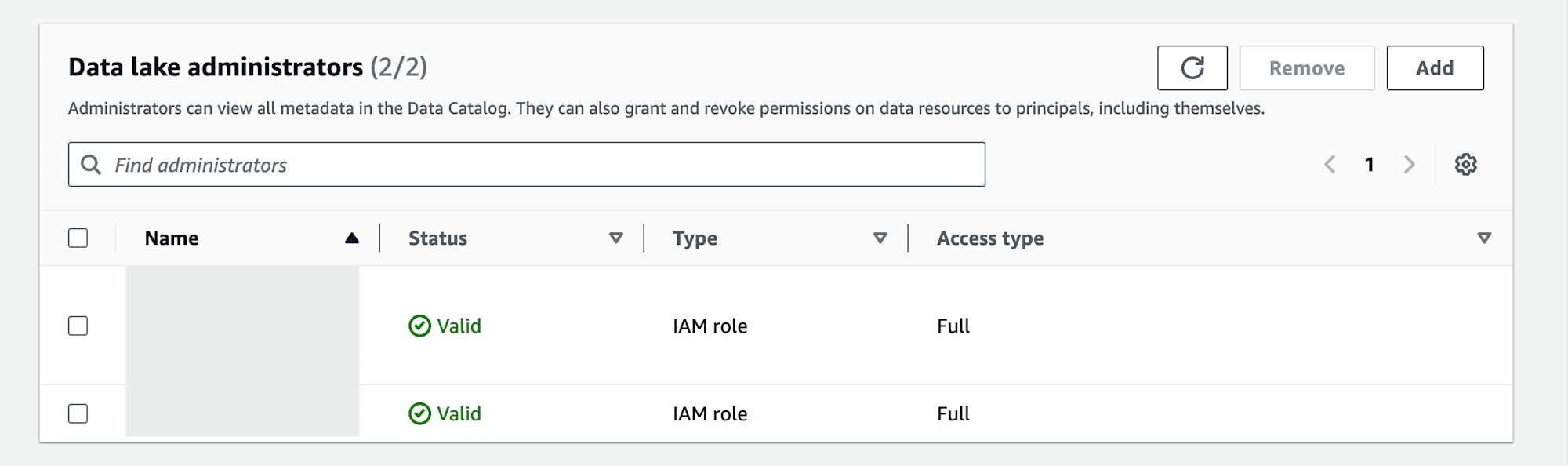
既存S3 Bucket、AWS Glue Data Catalog
手動で連携させるためのS3 Bucketを作成し、sampleデータを格納します。今回はAmazon DataZoneのworkshopで使用したorder.csvを使用します。
次に手動でGlue DBを作成し、先ほどのS3格納したcsvがあるS3 PathからTarget Glue DBとなるGlue Crawlerを作成します。この辺りの設定は、先ほどのワークショップの4.Amazon DataZone で公開するデータを作成する オプション:手作業でのデータカタログ作成通りにやっています。
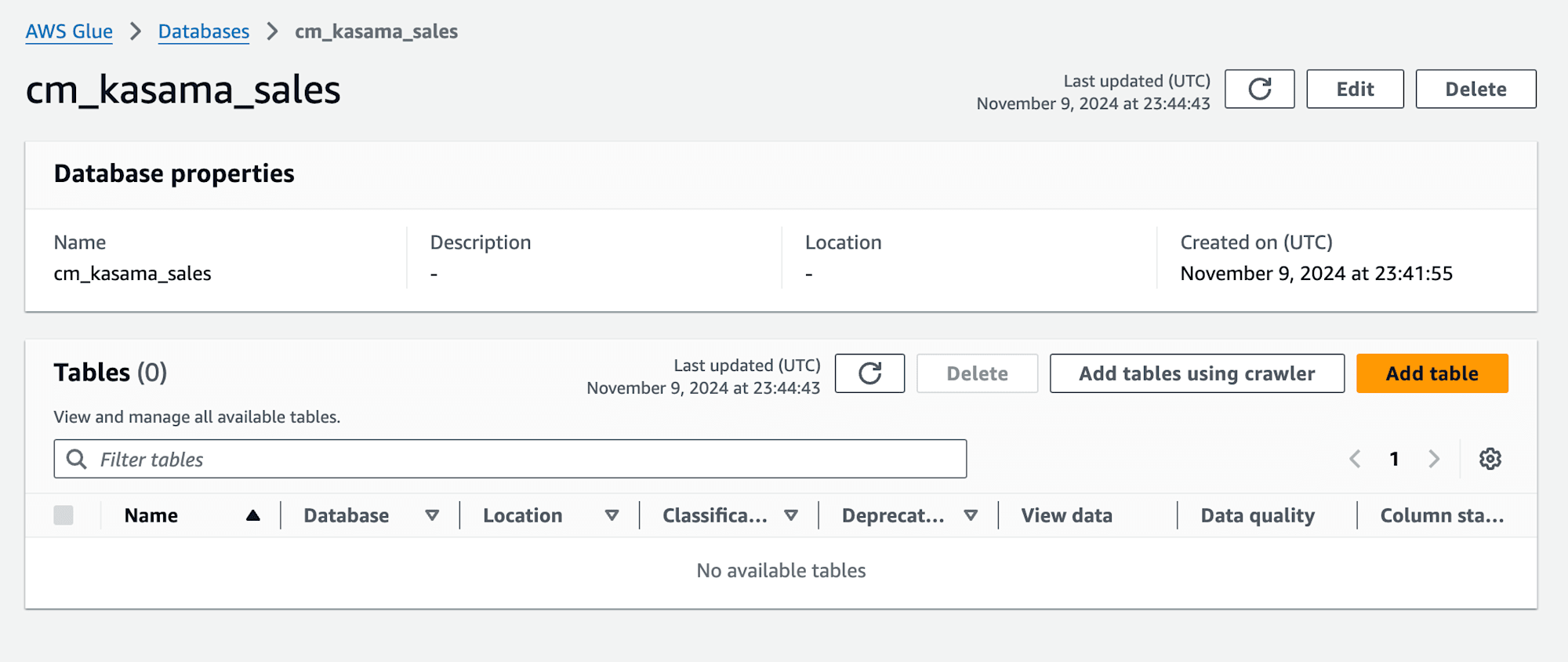
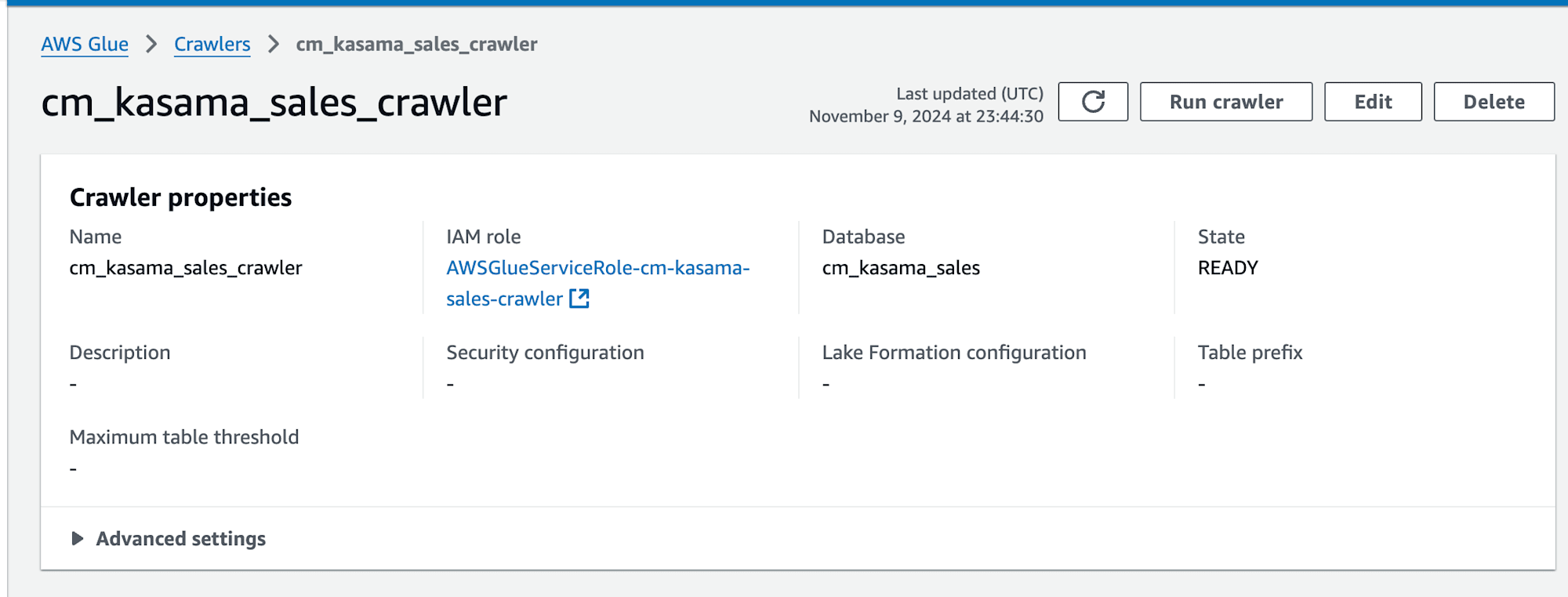
次にAWS Lake FormationのData lake permissionsでGlue CrawlerのIAM Roleに対して、作成したDBへのcreate table権限をGrantします。
Grant後はGlue Crawlerを実行し、tableが作成されることを確認します。
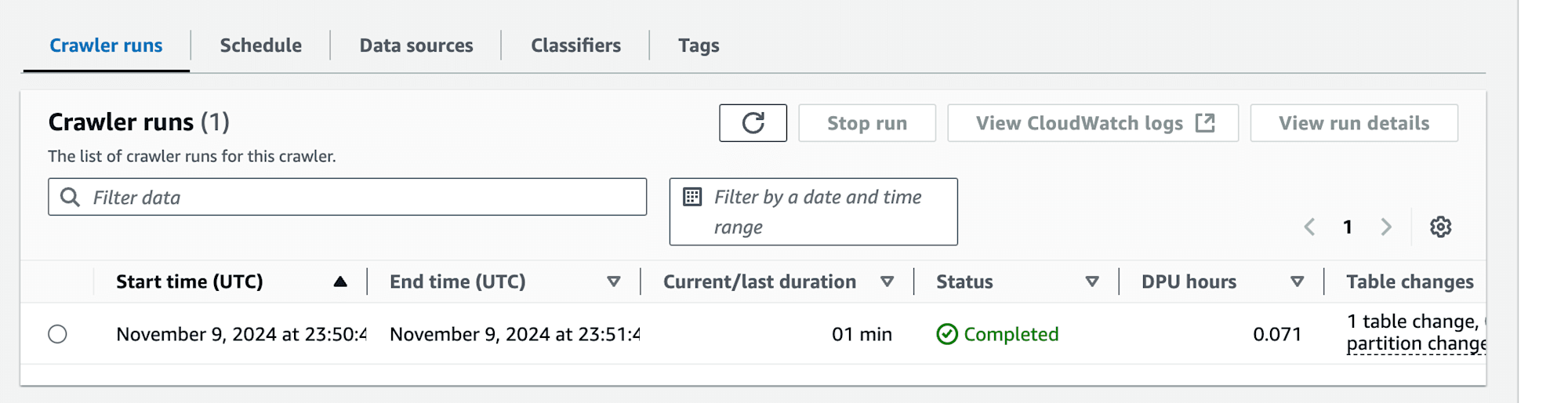
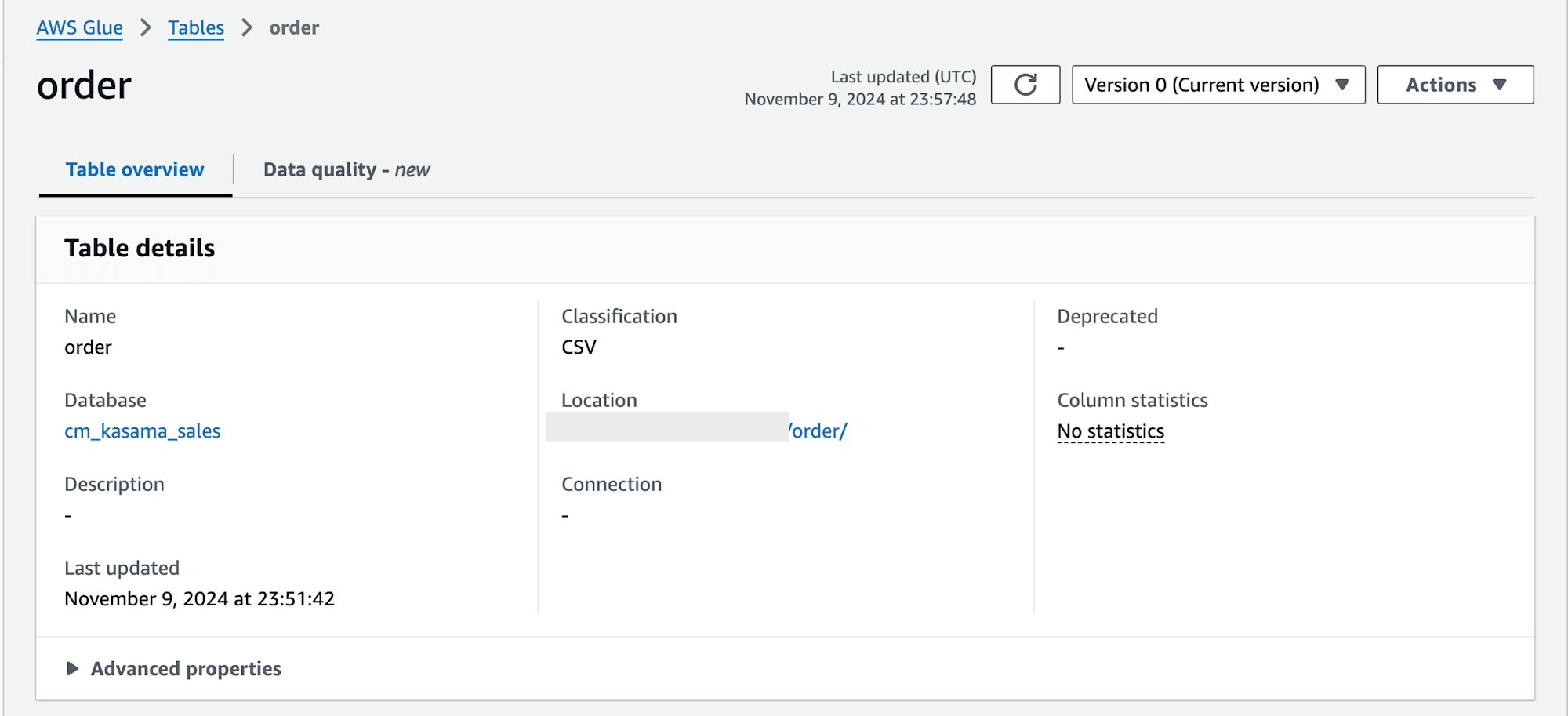
現状のAdmin権限で作成されたtableに対してAthenaで参照する場合は、AWS Lake FormationのData lake permissionsで該当tableへのselect権限が必要ですので注意してください。
Amazon DataZone デフォルトのデータレイクプロファイル
デフォルトのデータレイクプロファイルで、Sales(Producer側)プロジェクトとMarketing(Consumer側)プロジェクトを作成します。こちらについてもワークショップの以下の章を参考に作成しています。
ハンズオン(メイン) > 2.プロデューサー プロジェクトを作成するハンズオン(メイン) > 3.プロジェクト環境を作成するハンズオン(メイン) > 7.コンシューマー プロジェクトを作成する
Producer側設定
Glue DBをデータアセットに登録
まずは、ProducerとなるSales環境で先ほど作成したGlue DBをデータソースとして、データアセットを作成します。データソースが作成されたら実行ボタンを押すことで、メタデータが取り込まれデータアセットが作成されます。
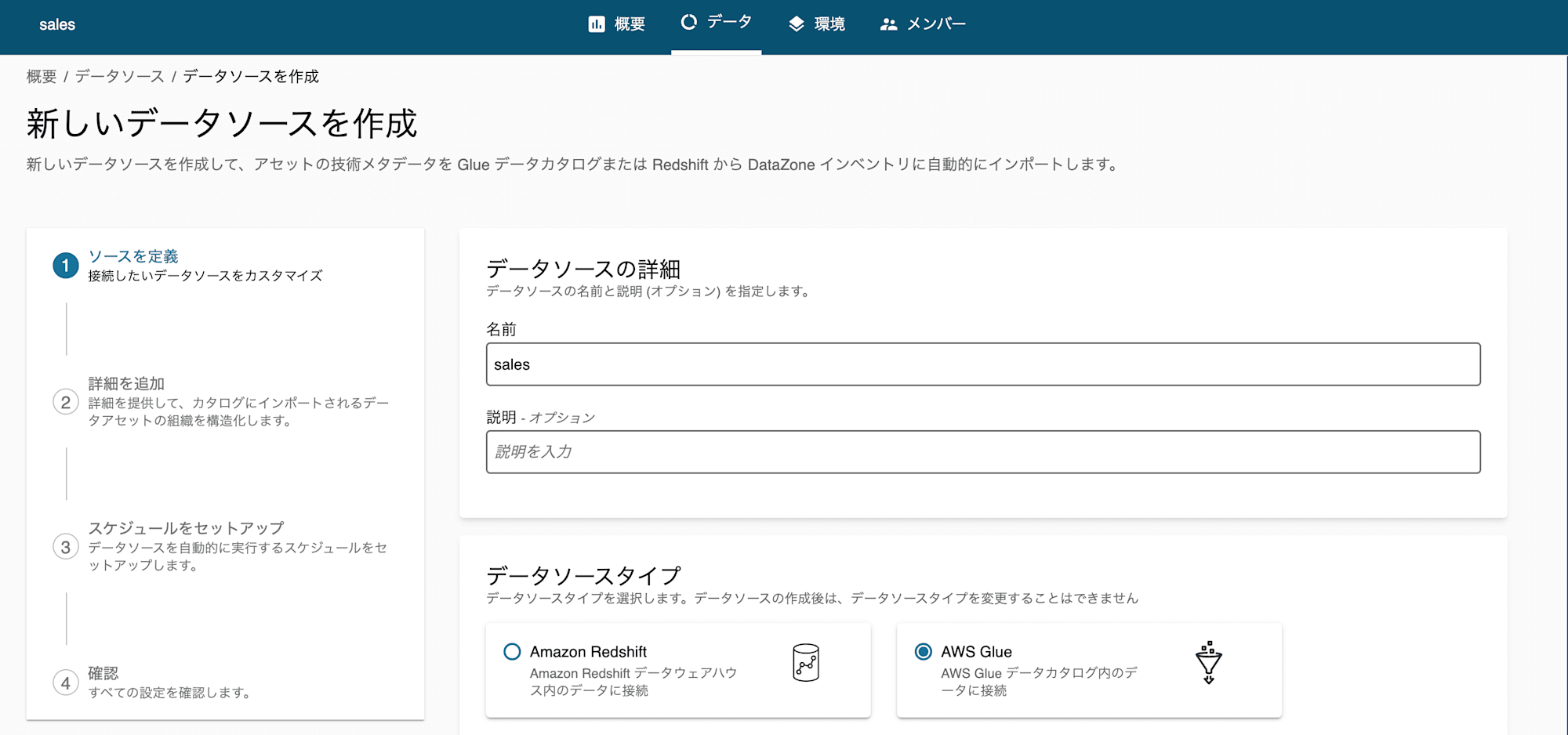
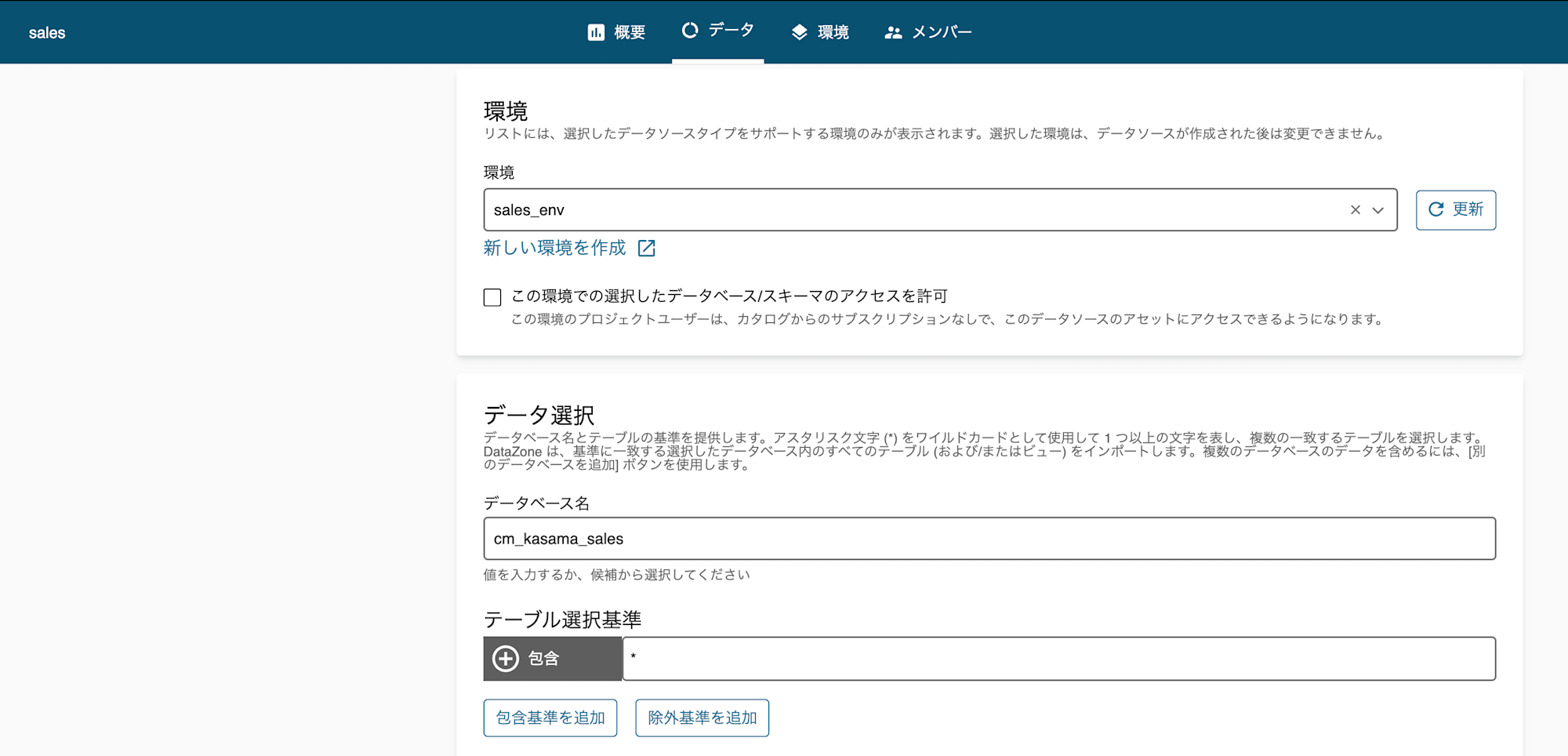
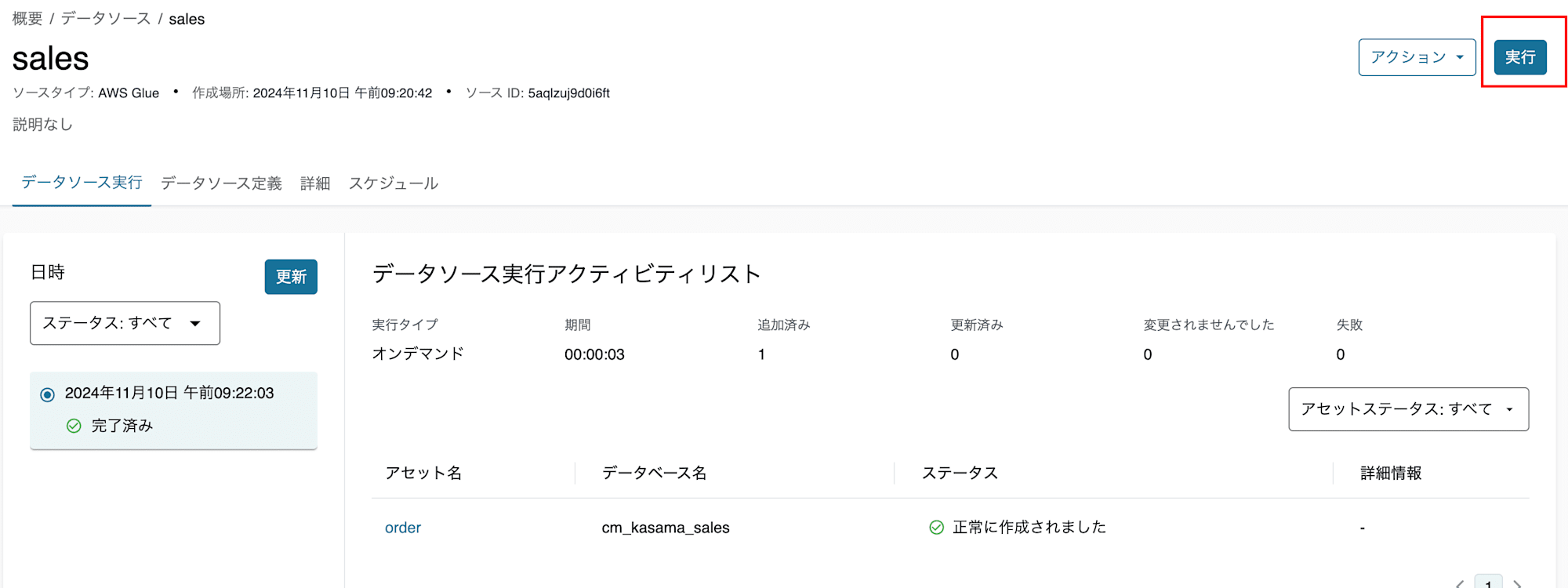
既存S3 BucketにAthenaで参照
Producer側の現状の設定でQuery dataからAthena画面へ遷移すると作成したcm_kasama_salesDBが参照できないことがわかります。これはAmazon DataZoneで作成されたIAM Roleで該当DBへAthena参照する権限とAWS Lake FormationのPermissionが不足しているためです。
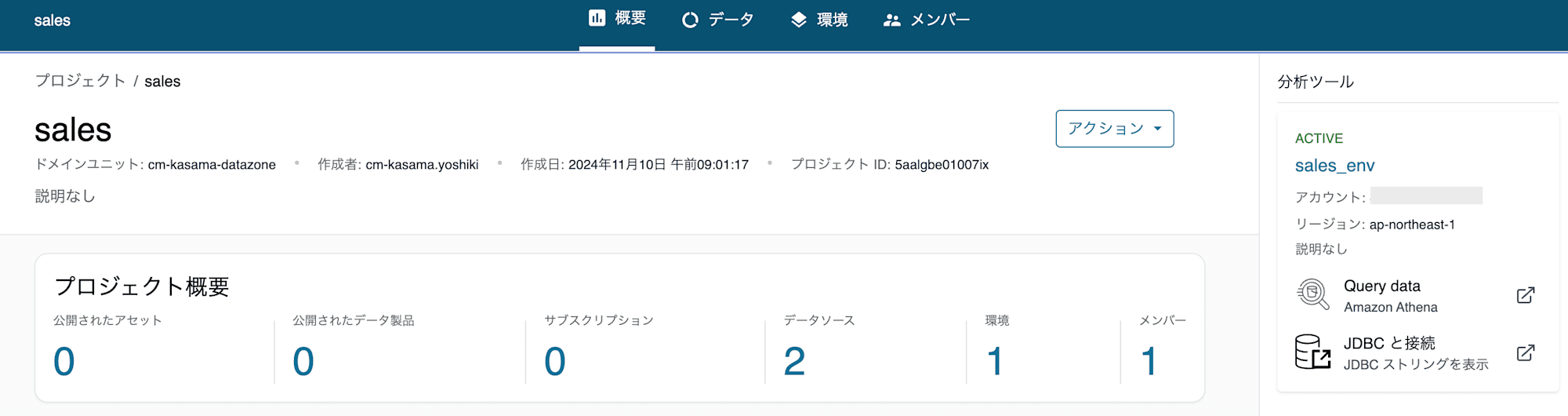
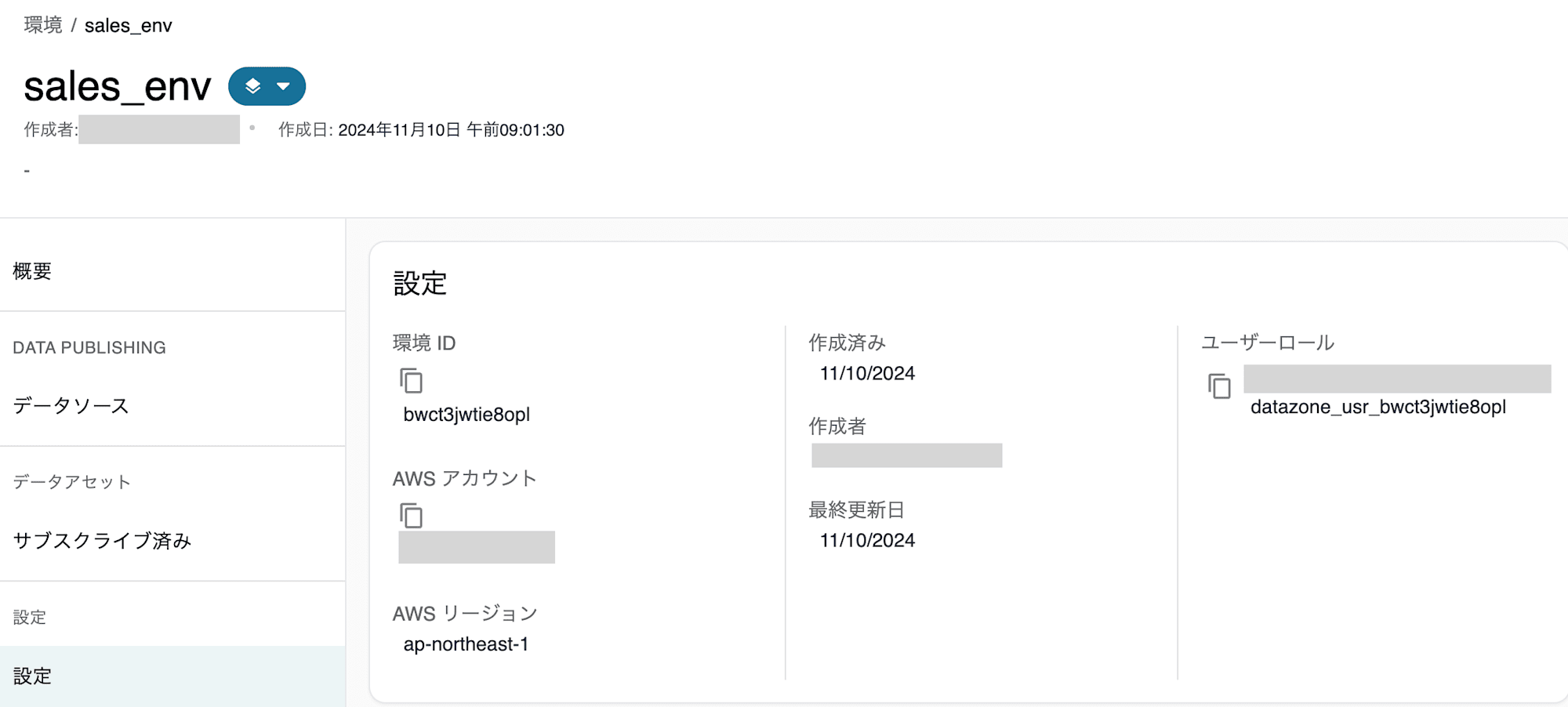
sales_env環境のユーザーロールは設定から確認できます。
今回はこのIAM Roleのポリシーを修正します。
該当のIAM Roleには3つのpolicyがありますが、1つ目と2つ目に既存のS3 BucketとGlueのARNを追記しています。
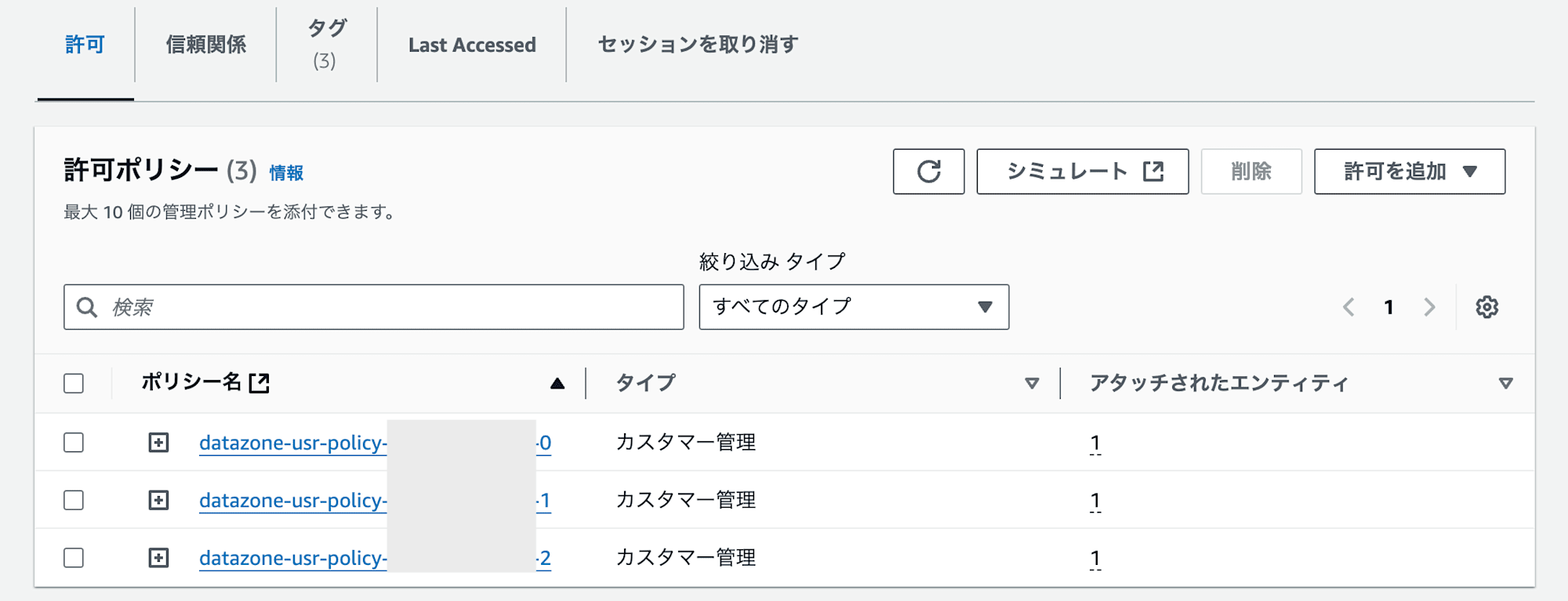
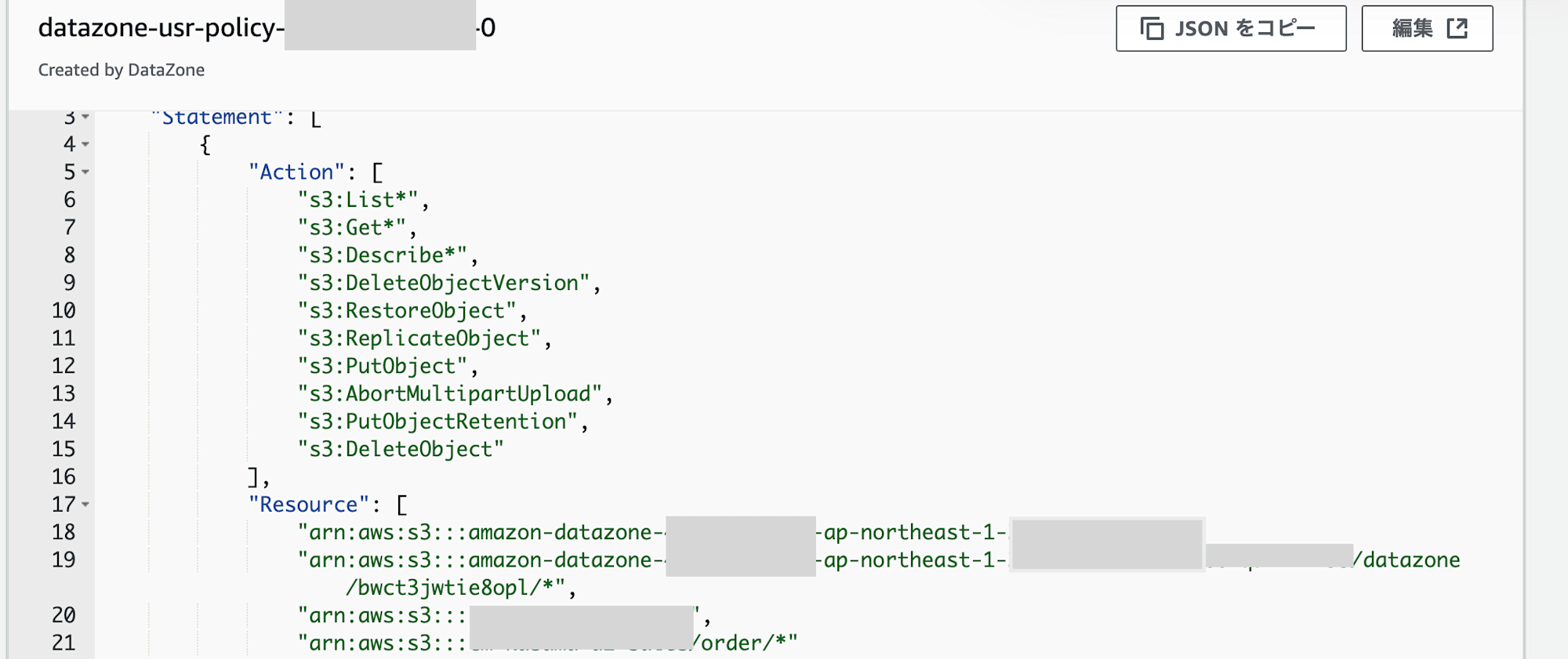
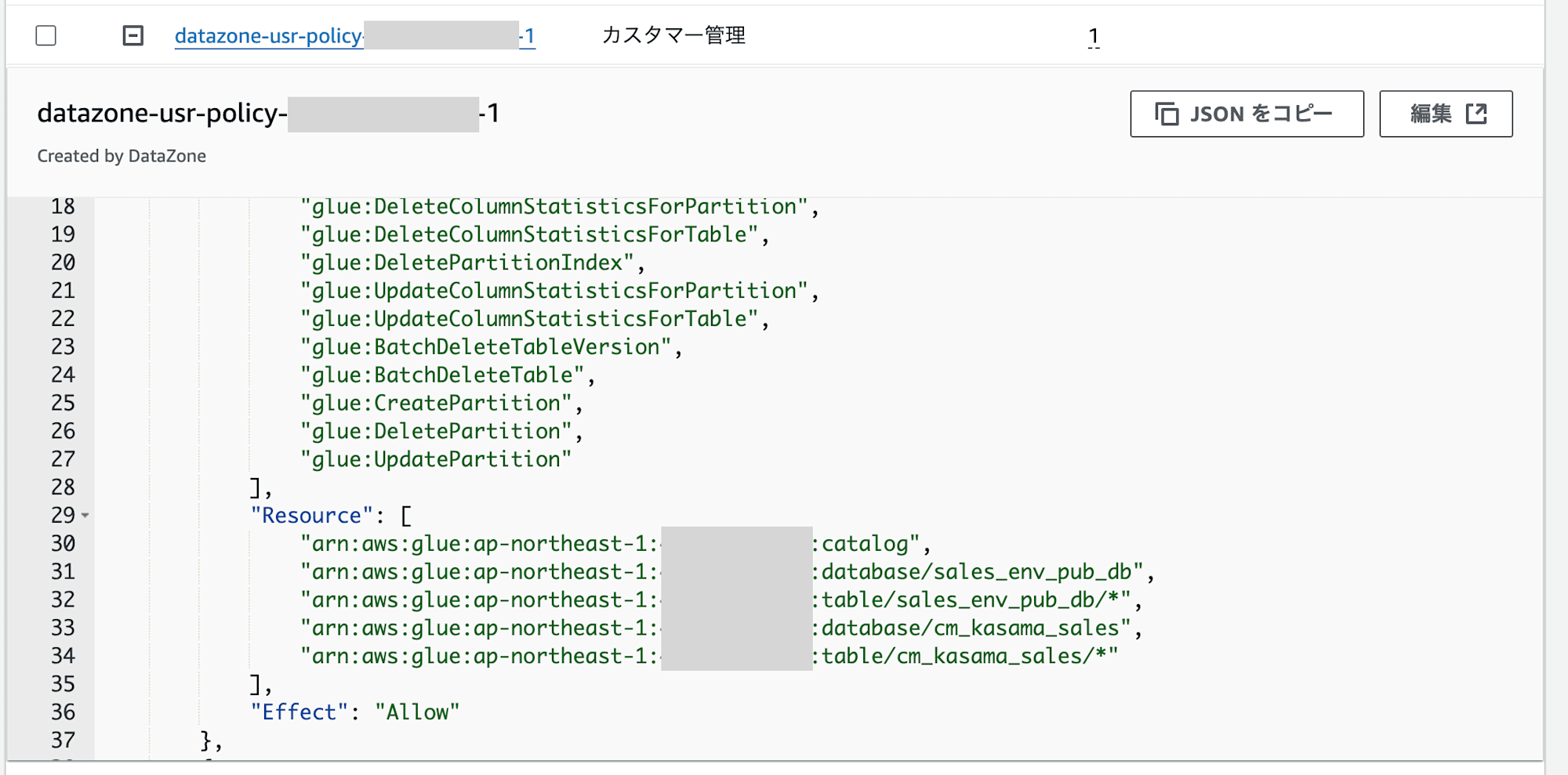
次にAWS Lake Formationを設定します。該当IAM RoleからAthenaで参照するには、以下の設定が必要です。
- データベースレベルの権限:
- DESCRIBE 権限: データベース内のテーブルリストを表示するために必要です。
- テーブルレベルの権限:
- DESCRIBE 権限: テーブルのメタデータを表示するために必要です。
- SELECT 権限: テーブルのデータを読み取るために必要です。
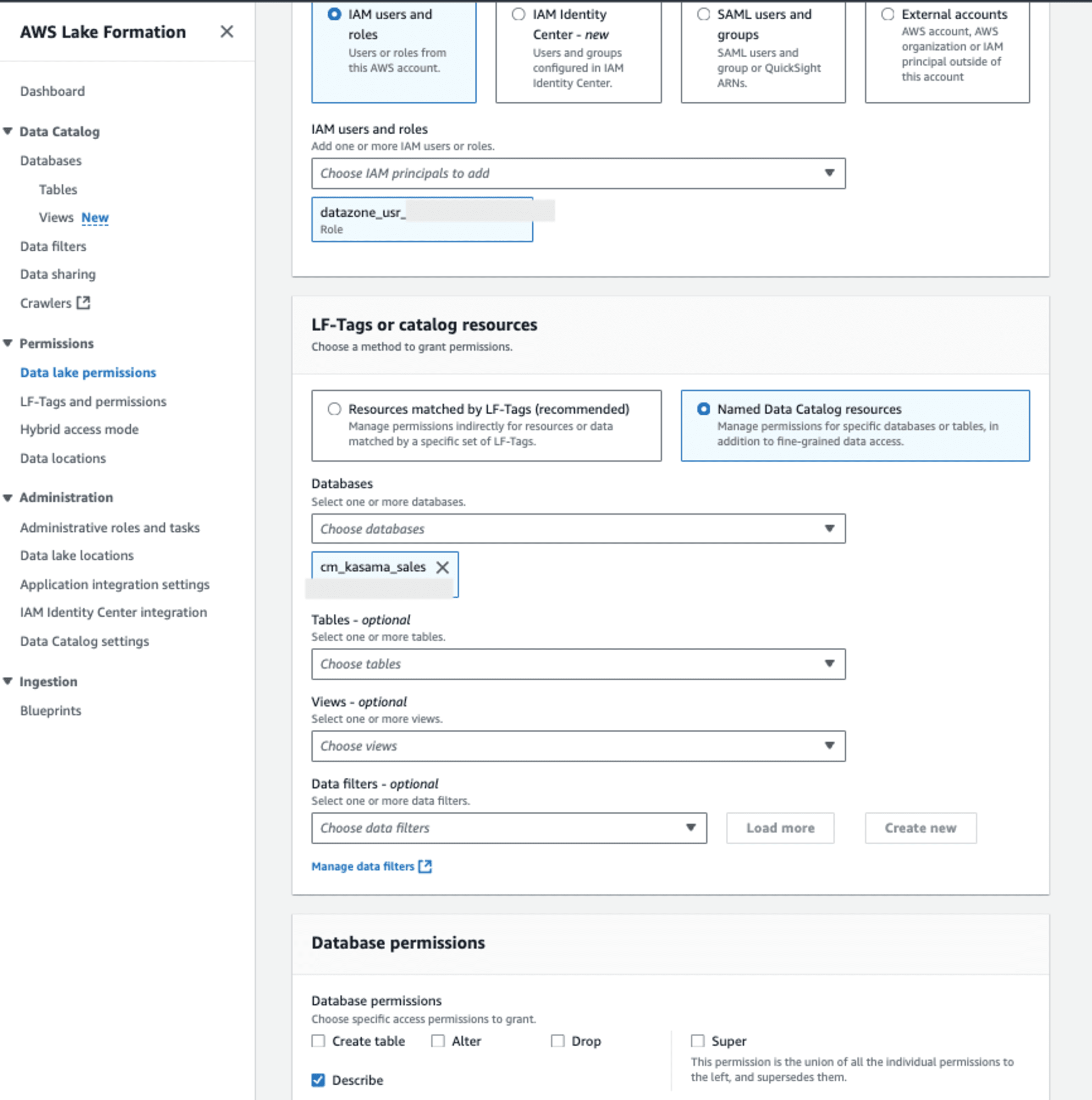
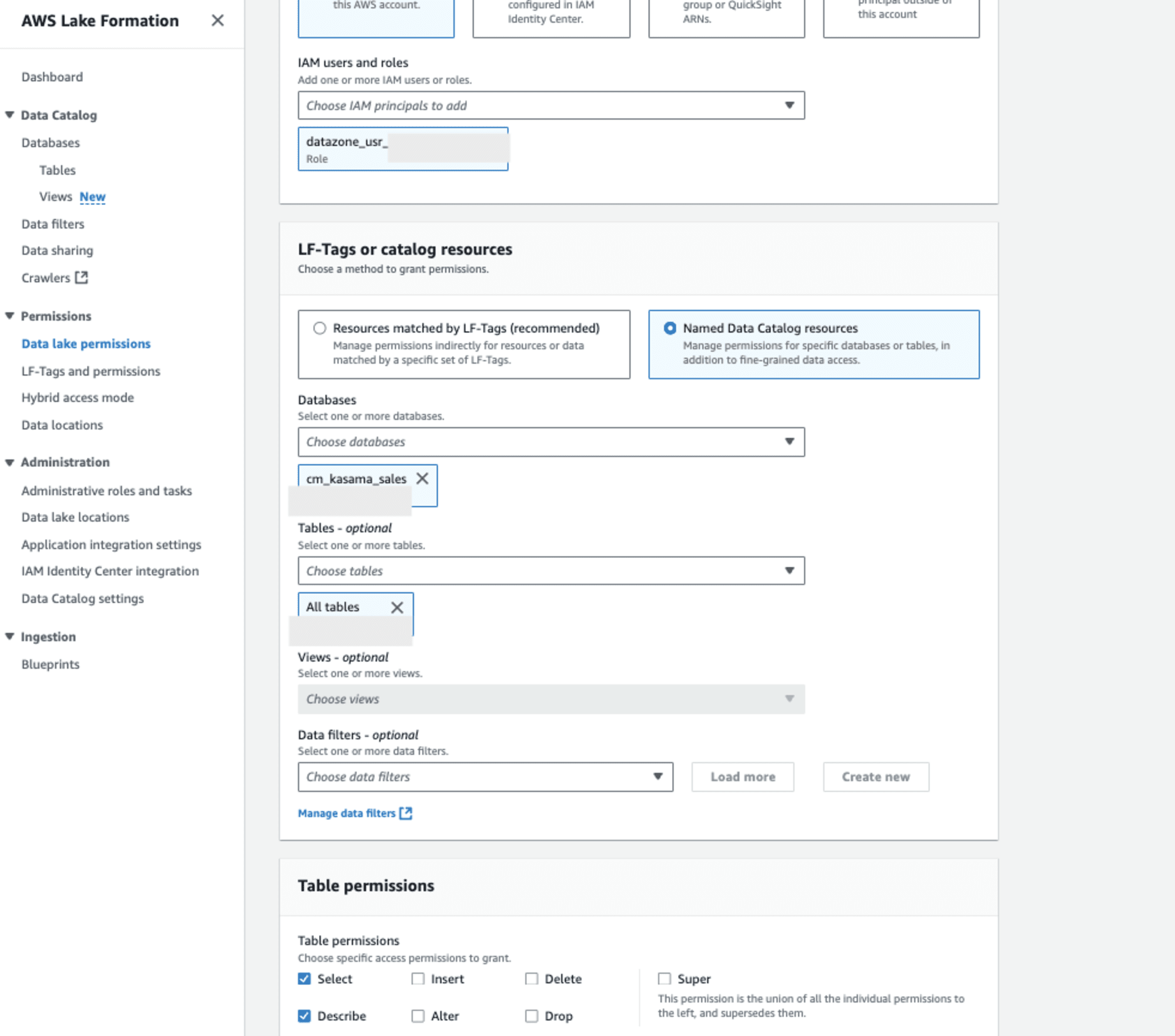
これでAthenaで参照できると思い、クエリをかけましたが、エラーとなりました。
com.amazonaws.services.s3.model.AmazonS3Exception: User: arn:aws:sts::<AWS_ACCOUNT_ID>:assumed-role/datazone_usr_<role>/ee8opl is not authorized to perform: s3:ListBucket on resource: "arn:aws:s3:::<BUCKET_NAME>"
because no permissions boundary allows the s3:ListBucket action (Service: Amazon S3;
Status Code: 403; Error Code: AccessDenied; Request ID: 20TQ52d2NJ; S3 Extended
Request ID: eEvaT0=; Proxy: null), S3 Extended Request ID: IofWyCT0= (Bucket: <BUCKET_NAME>, Key: order/)
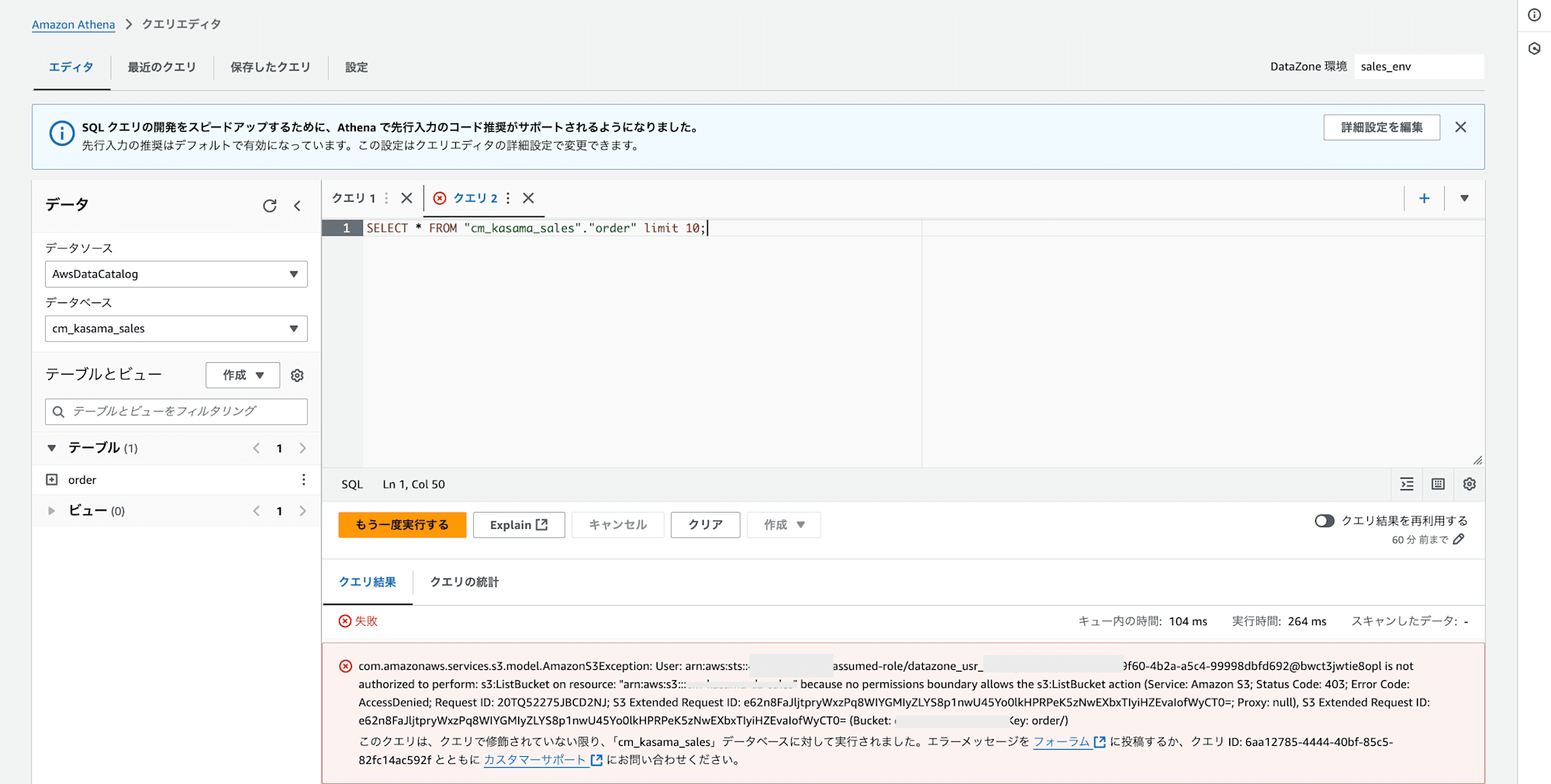
原因は、IAM Roleに付与されているAmazonDataZoneEnvironmentRolePermissionsBoundaryというPermissionsBoundaryにあります。ListBucketの権限が特定のprefixでないと許可されない設定となっています。

対応としては、AmazonDataZoneEnvironmentRolePermissionsBoundaryを外すか、AmazonDataZoneEnvironmentRolePermissionsBoundaryをCOPYして先ほどのConditionのみ修正したPermissionsBoundaryに置き換えるかになります。今回は簡易的な検証用途のため、外す対応としますが、プロジェクトで使用する場合は置き換えることを推奨します。
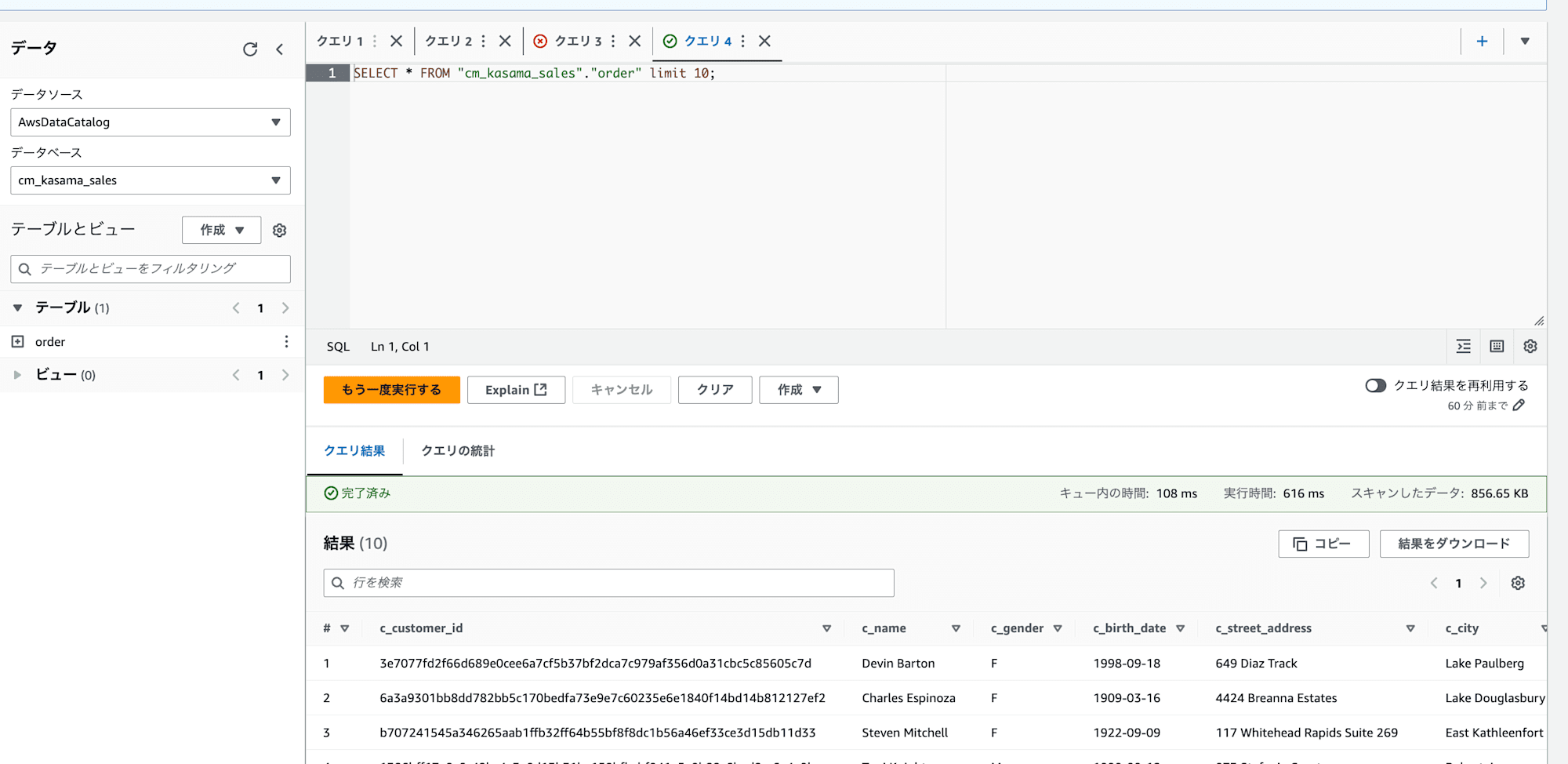
改めてAthenaでクエリしたところ成功しました。
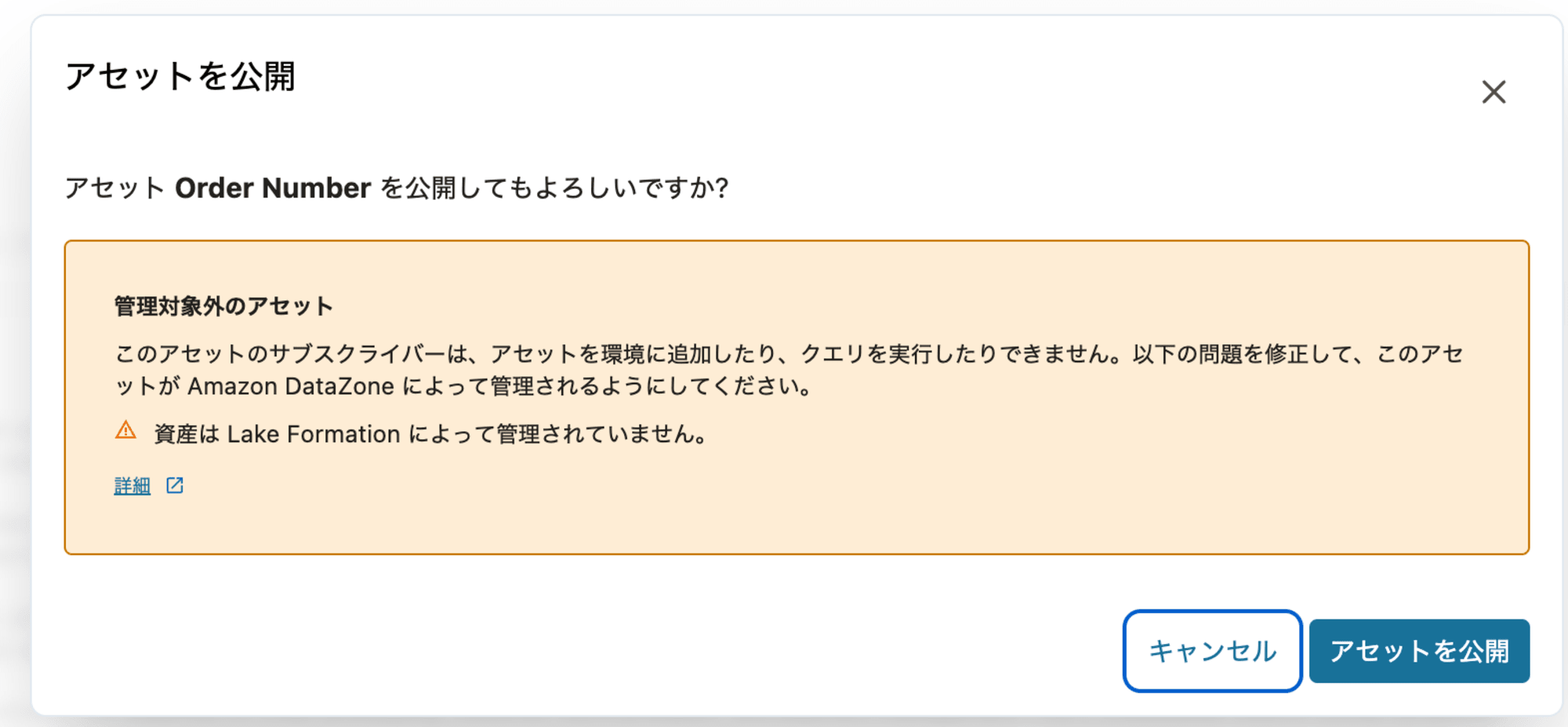
データアセットを公開
データアセットを公開しようとすると、管理対象外の警告が出ます。これは、公開するアセットに AWS Lake Formation のアクセス許可が適用されていないことを示します。アセットの Amazon S3 の場所をAWS Lake Formation に登録する必要があります。
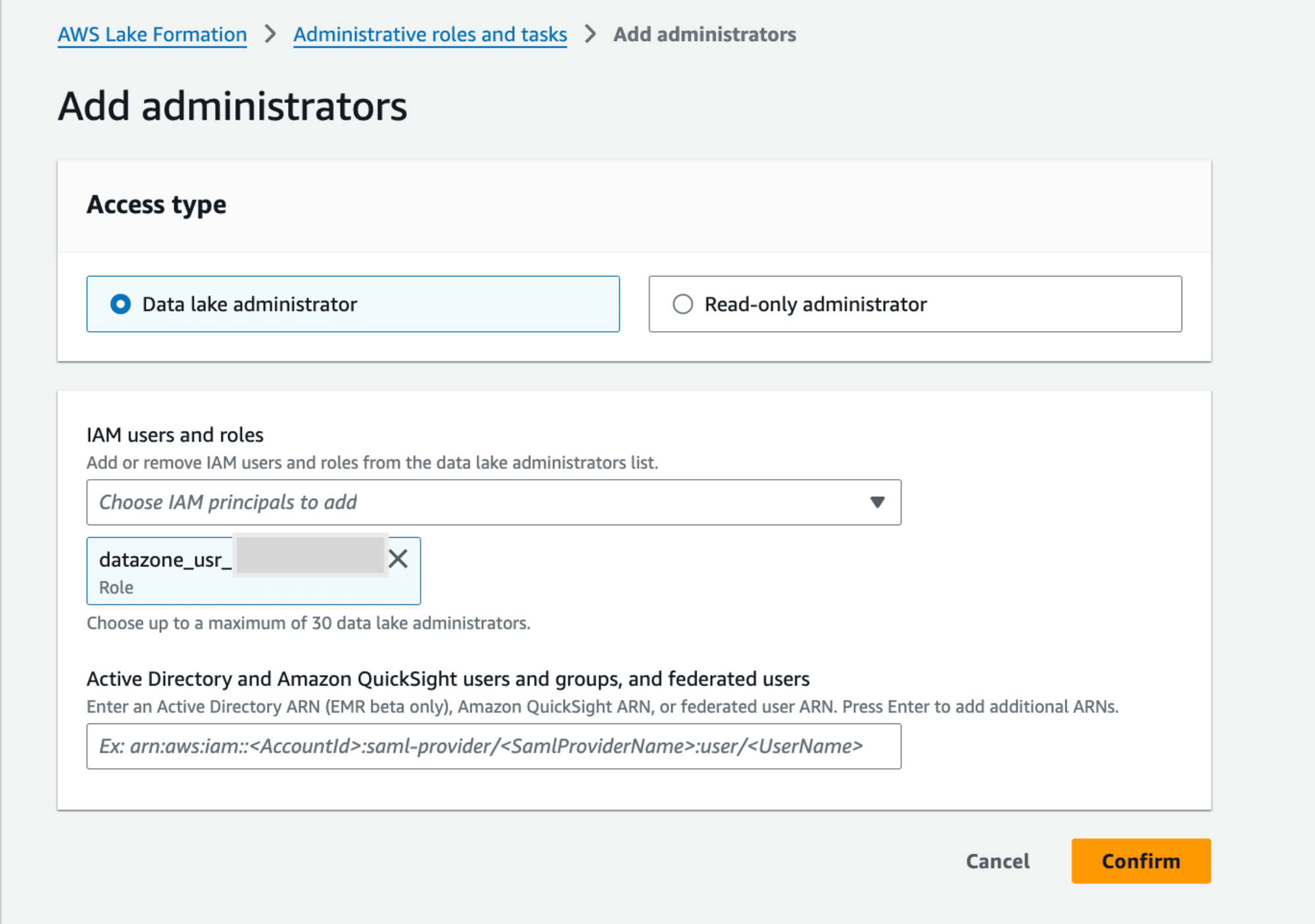
AWS Lake FormationのData lake administratorsでIAM RoleをData lake administratorに設定します。
AWS Lake FormationのData lake locationsでIAM Roleに、該当S3 pathのpermissionをLake Formationで設定します。
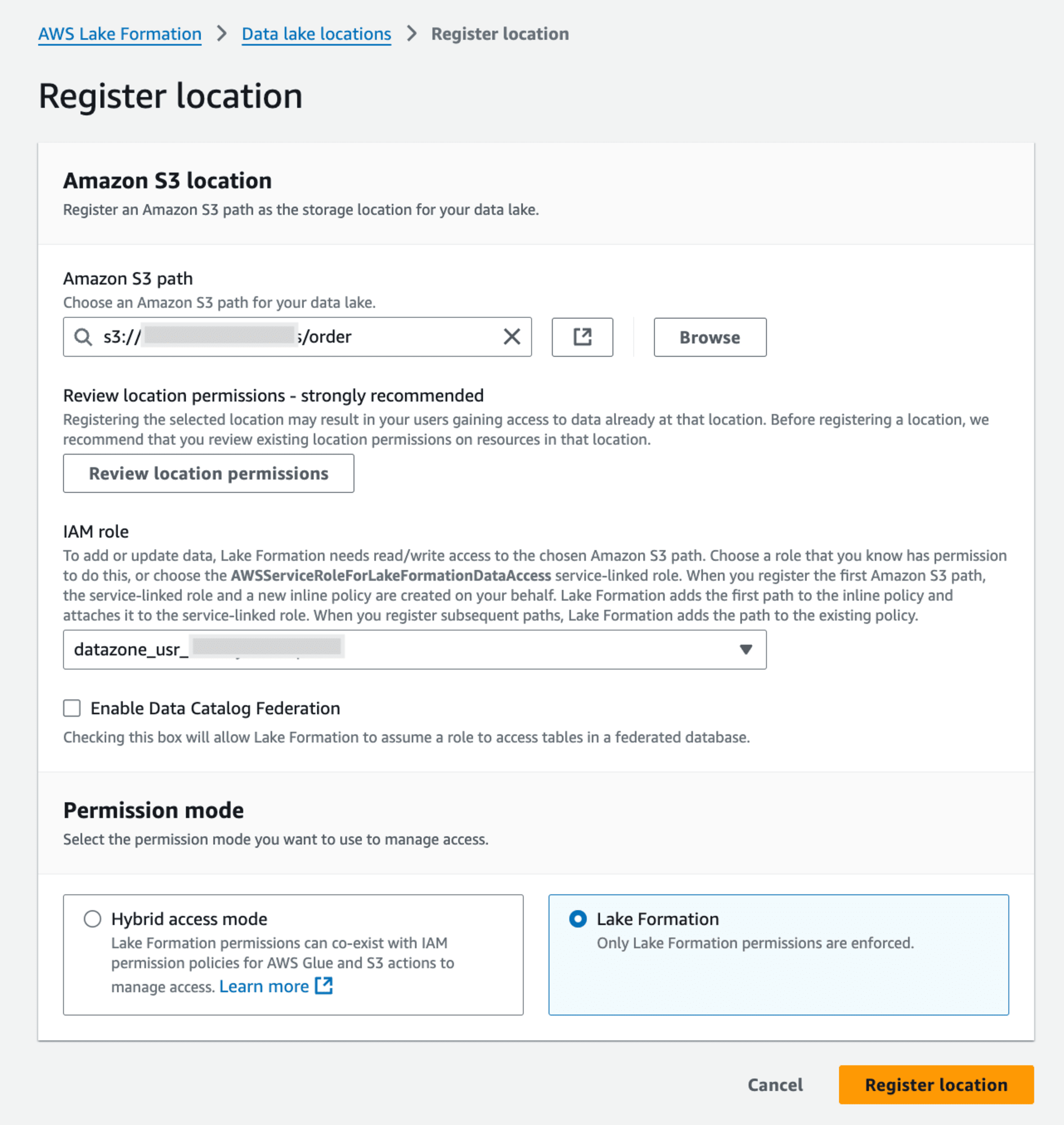
AWS Lake FormationのData locationsでIAM Roleに、該当S3 pathへのpermissionをGrantします。
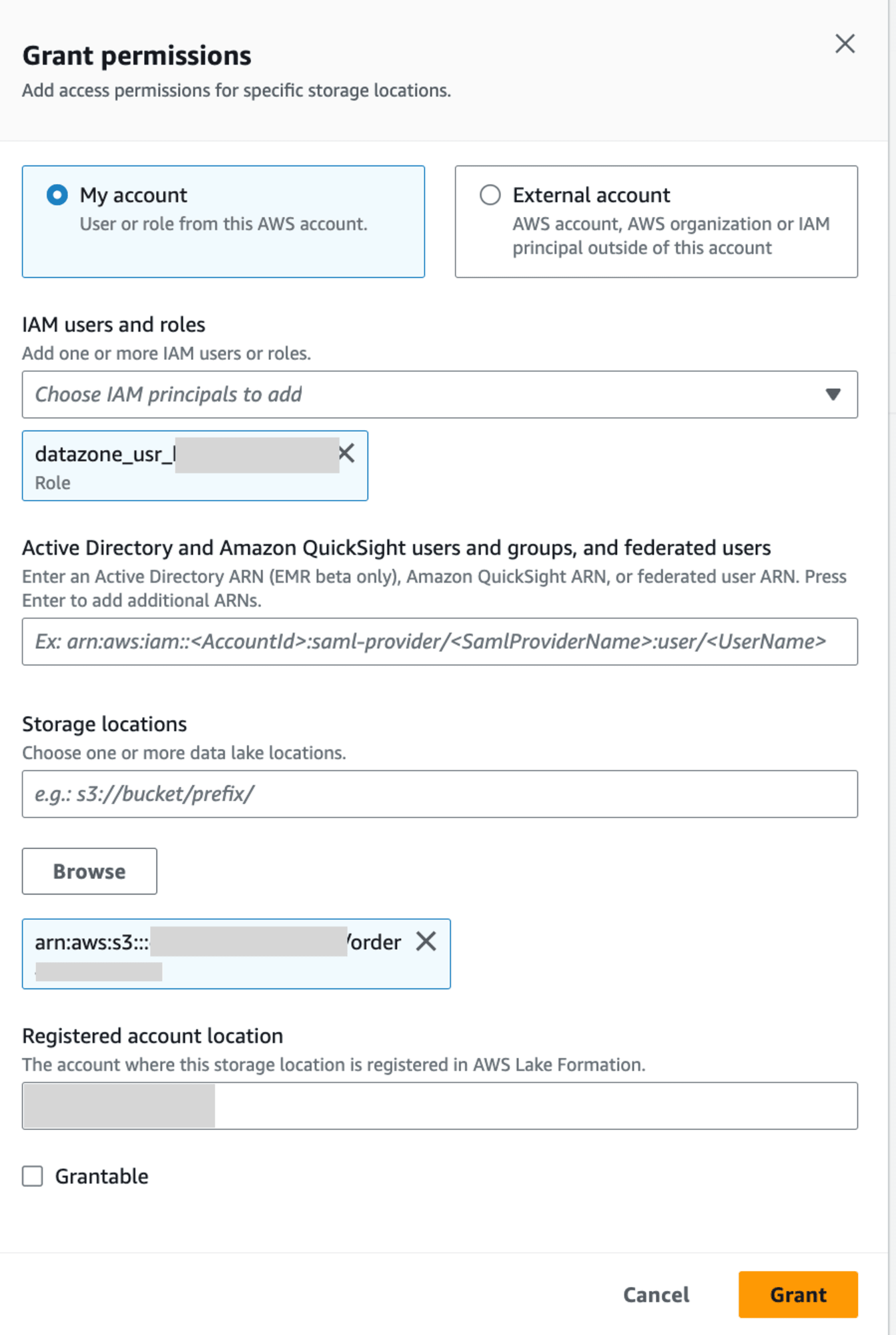
設定した後に公開ボタンを押すと先ほどのアラートは消えているので、この状態で公開します。
Consumer側設定
データアセットのサブスクライブ
次にConsumer側のMarketingプロジェクトで、検索ボックスからデータアセットを検索し、サブスクリプションリクエストを出します。
Producer側のSalesプロジェクトで受信リクエストからリクエストを表示し、サブスクリプションを承認します。
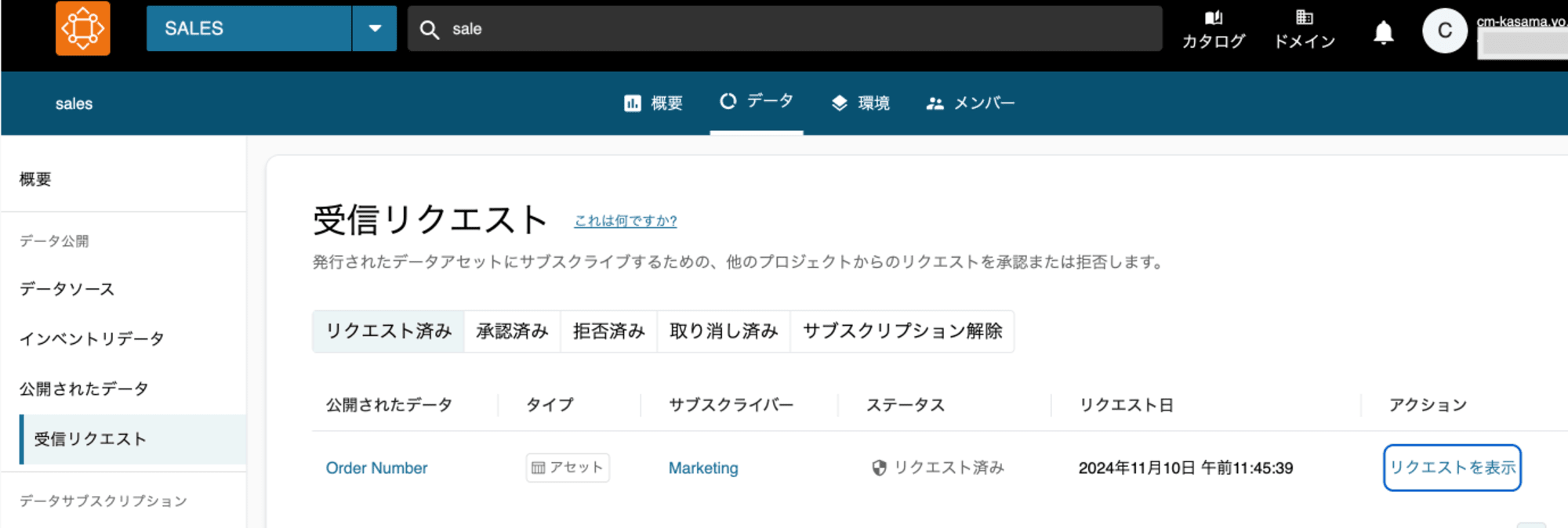
再度Consumer側に戻ると閲覧できていることがわかります。
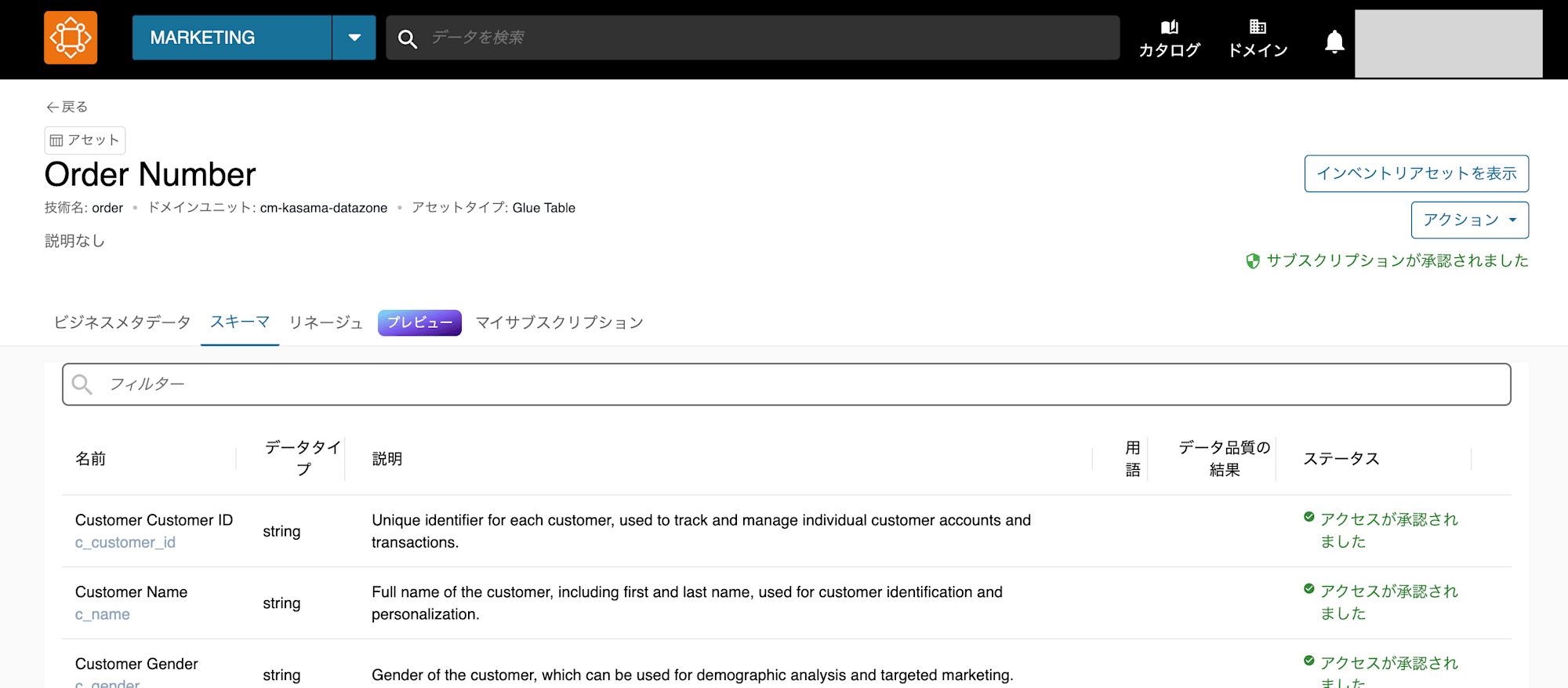
既存S3 BucketにAthenaで参照
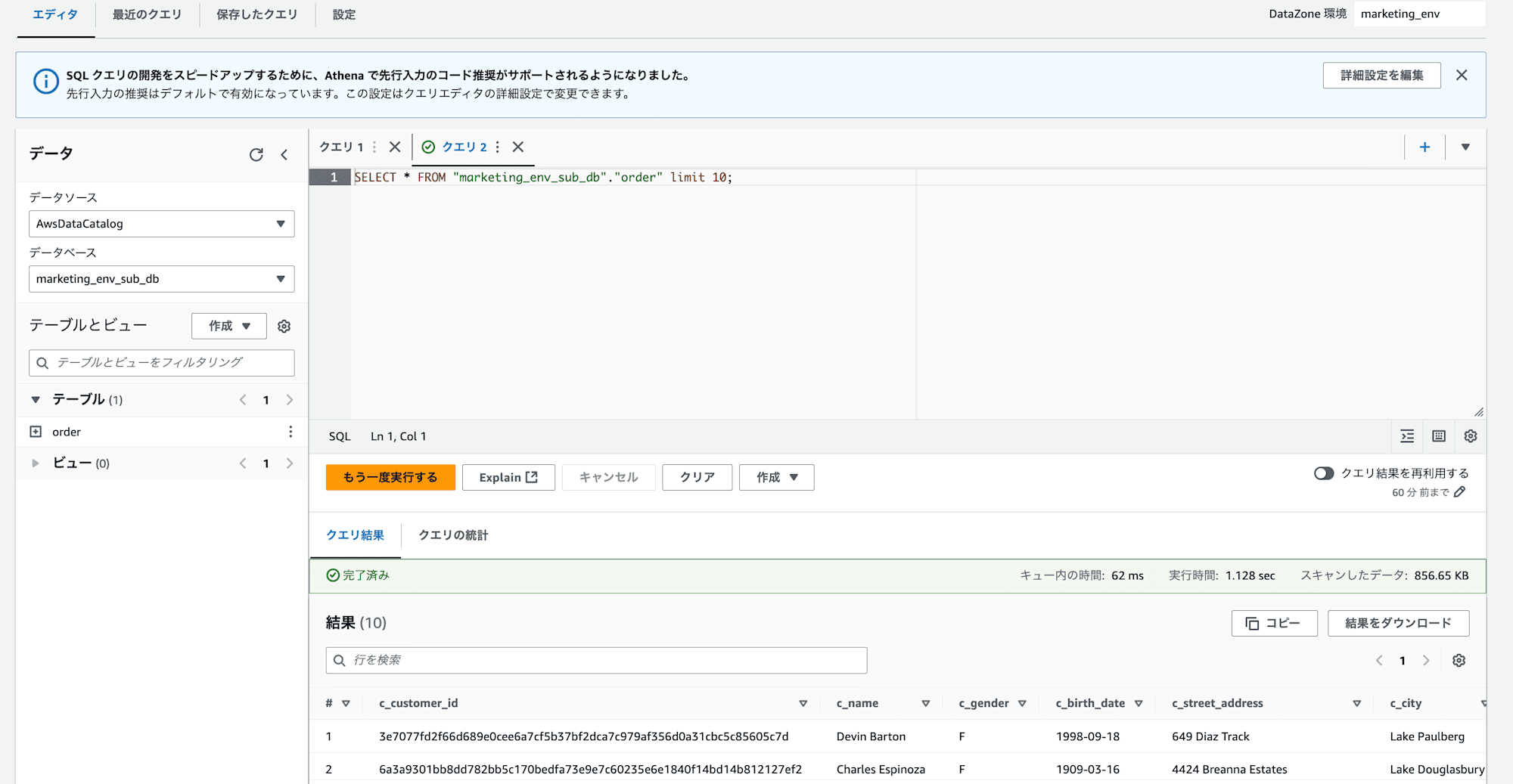
MarketingプロジェクトのQuery dataからAthena参照は問題なく成功しました。サブスクリプションするとAmazon DataZone管理のGlue DBにtableが作成され、権限も付与されるため、設定変更は不要です。
(試しにProducer側のS3アクセス権限を削除したところ、Marketing側のAthenaクエリで失敗しました。Assumeしている動きに見えましたがCloudTrailからそのようなイベントは確認できなかったため、あくまで推測です。)
最後に
手動で修正することがなかなか手間なのでIaCで管理したいところです。。
EventBridgeでDataZoneのEventは検知できます。イベントトリガーでLambdaをキックさせて権限を変更するみたいなことはやろうと思えばできますが、なかなかの手間だと思います。
カスタムプロファイルで構築する方法については引き続き検証したいと思います。
2024/11/25 追記
改めて公式のワークショップを確認したところ、4.Amazon DataZone で公開するデータを作成する オプション:手作業でのデータカタログ作成に4. Lake Formationにデータレイク登録という項目が追記されていました。内容は、データソースのあるS3 PathをAWS Lake FormationのData lake locationsで登録するというものです。IAM Role AWSServiceRoleForLakeFormationDataAccessに対して、該当S3 PathにPermission mode Lake Formationで登録します。
試しに手動で作成した、S3 Bucketの該当Pathに対して、AWSServiceRoleForLakeFormationDataAccessのPermissionを設定しました。
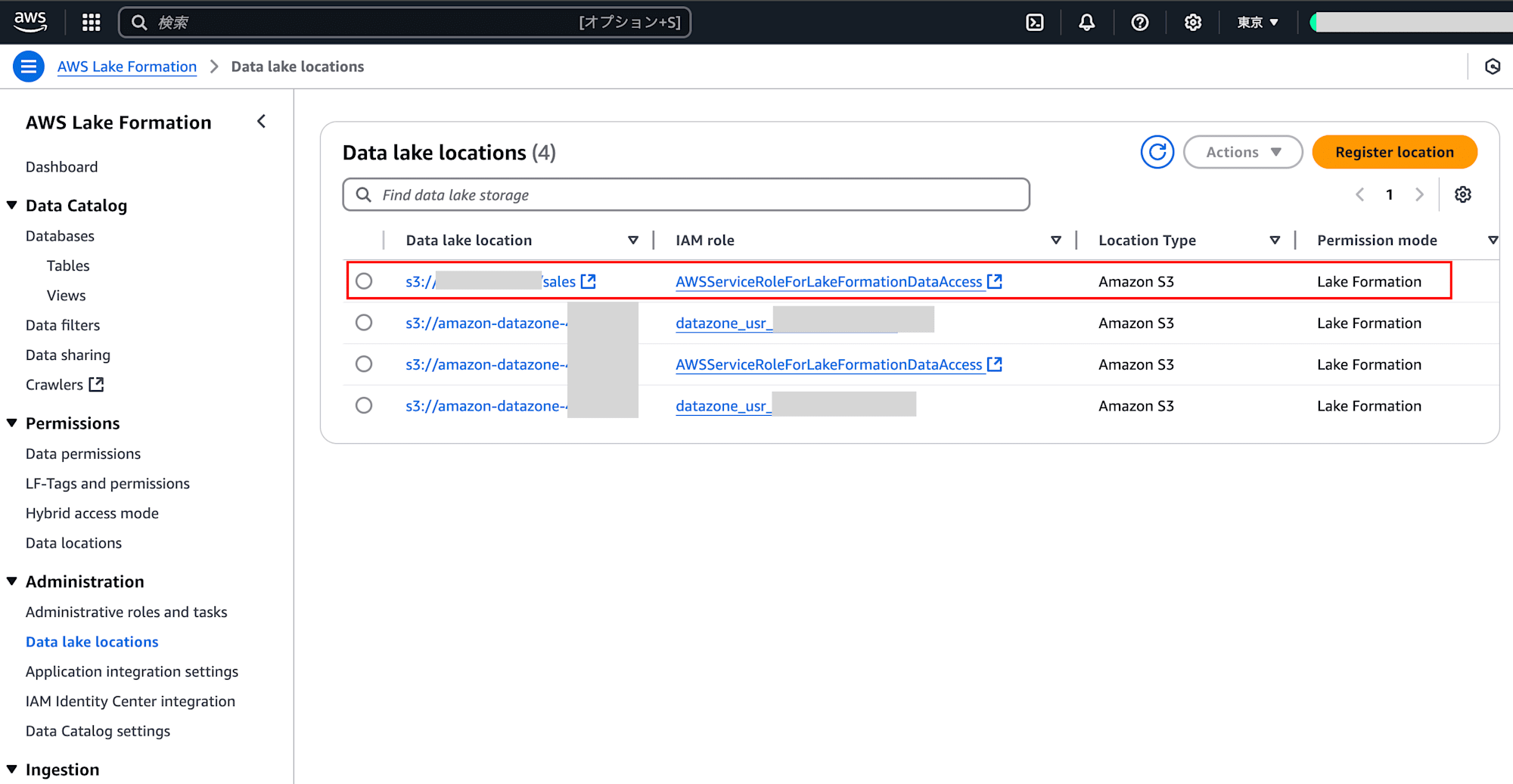
そのあとは、Producer側で、データソースの作成、データアセット作成、データの公開を行い、Consumer側で、サブスクリプション依頼、Producerで承認をしたのちに、Consumer側でQuery dataからAthena画面へ遷移しました。
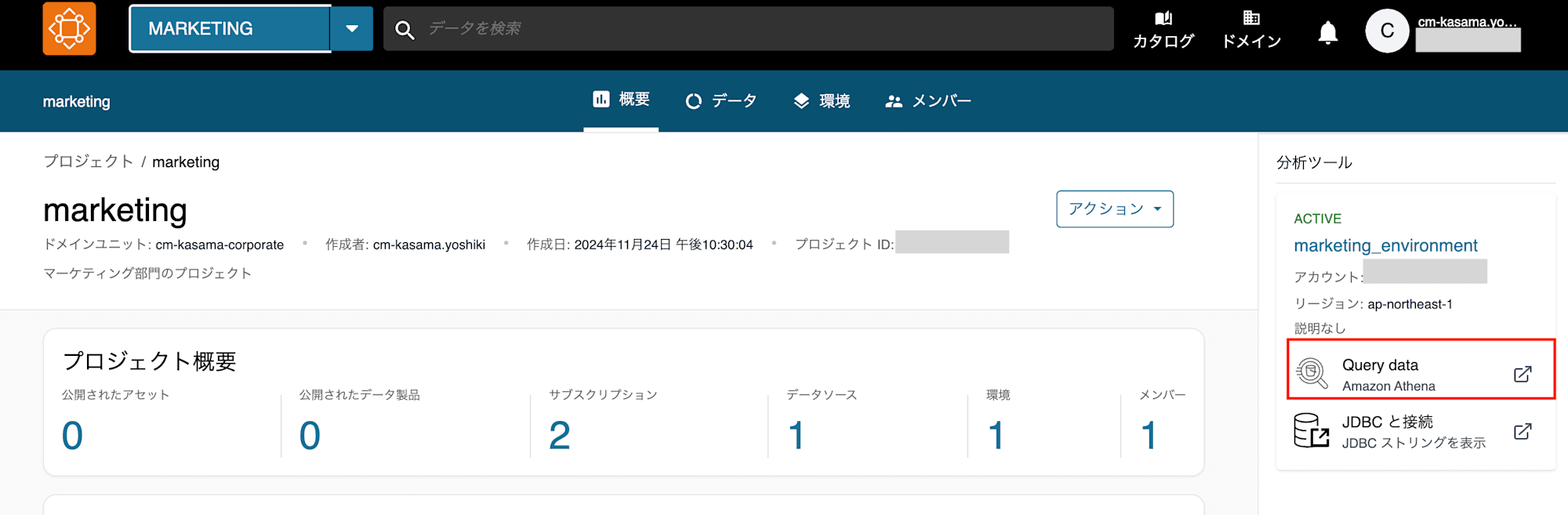
クエリを実行したところ、S3ファイルの内容が参照できていることが確認できました。
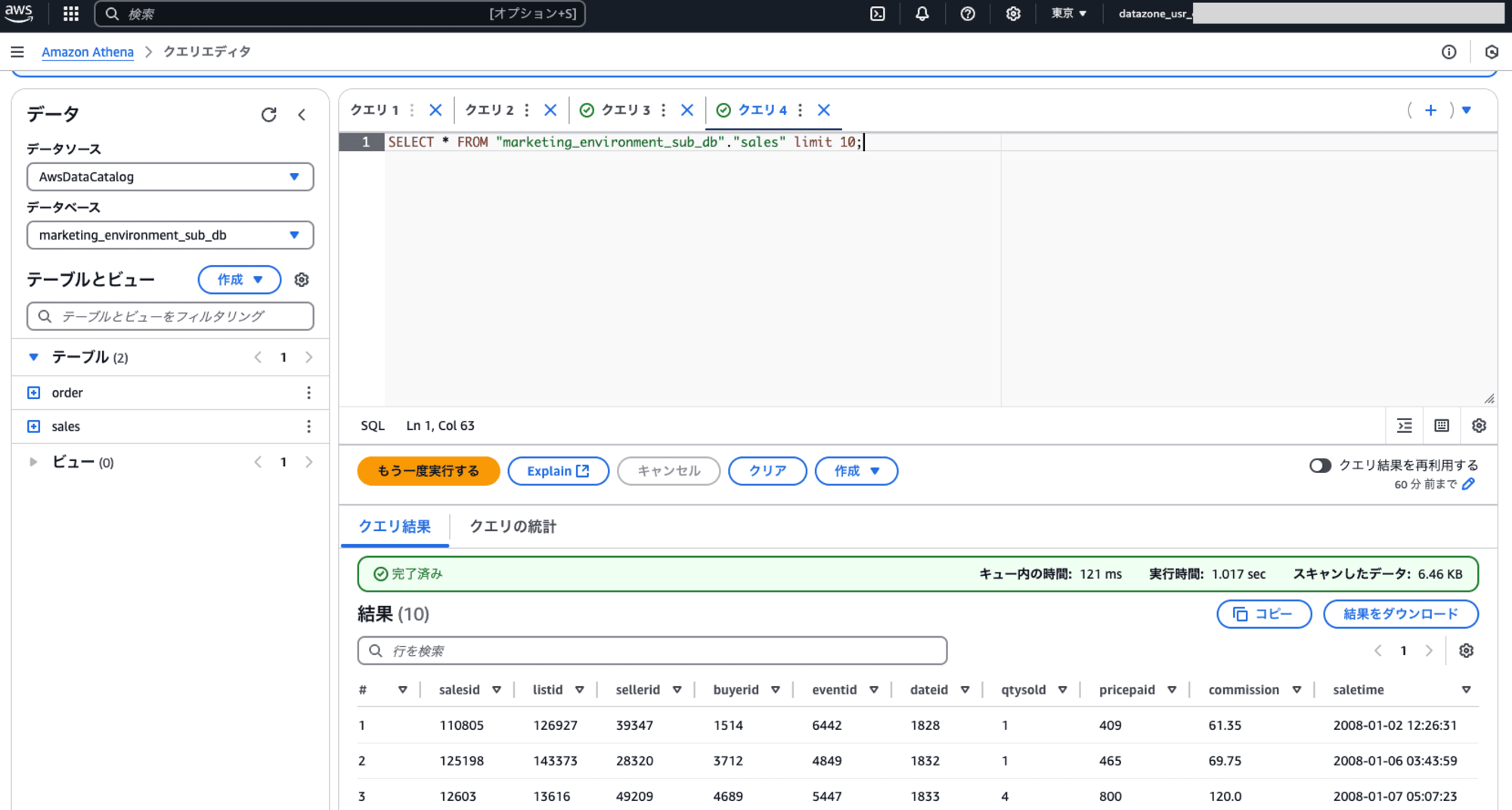
Data lake locationsにAWSServiceRoleForLakeFormationDataAccessを登録する前後で、変化を確認したところ、登録後に許可ポリシーに対象パスへの操作権限が追加されていました。
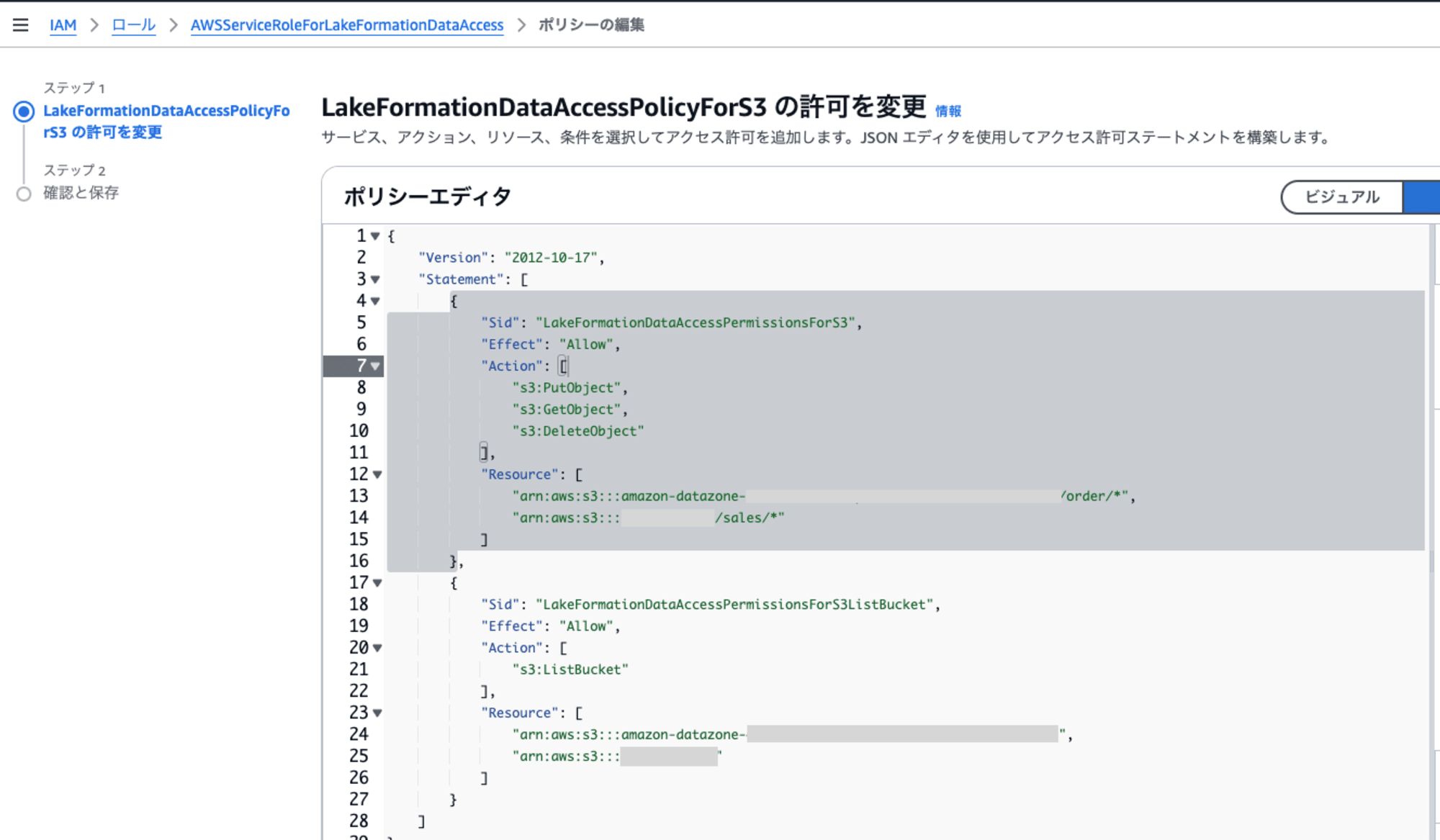
Amazon S3 ロケーションを登録すると、Lake Formation はAWSServiceRoleForLakeFormationDataAccessロールを引き継ぎます。これにより、その場所のデータにアクセスするAWS サービスに一時的な認証情報が付与され、datazone_prefixで始めるIAM RoleからS3へAthenaでクエリすることが成功するのです。
以下P17参照
Producer側でもAthenaでクエリしたい場合は、sales_environment_sub_dbに登録されていないと参照できないため、自身のデータに対してサブスクリプションの依頼と承認を行い、sales_environment_sub_dbと紐づけることで参照するのが簡単な方法です。
![[レポート] Amazon DataZoneのデータリネージでデータの探索をより強力に #AWSreInvent #ANT207-NEW](https://images.ctfassets.net/ct0aopd36mqt/3IQLlbdUkRvu7Q2LupRW2o/edff8982184ea7cc2d5efa2ddd2915f5/reinvent-2024-sessionreport-jp.jpg)



