
Athena で S3 バケット内のファイル名に含まれるタイムスタンプから同一日付の新しいレコードのみを抽出してみる

いわさです。
Athena で日次出力される CSV ファイルを参照しているケースで、ファイルに作成時点のタイムスタンプが含まれるために同一日付で CSV ファイルの再作成をするとバージョニングが効かないケースがありました。
次は適用に用意したサンプルなのですが、こんな感じでファイル末尾にタイムスタンプ情報が含まれています。
以下であれば、7月1日のファイルがひとつと、7月2日のファイルが0時のものと1時のものが存在しています。
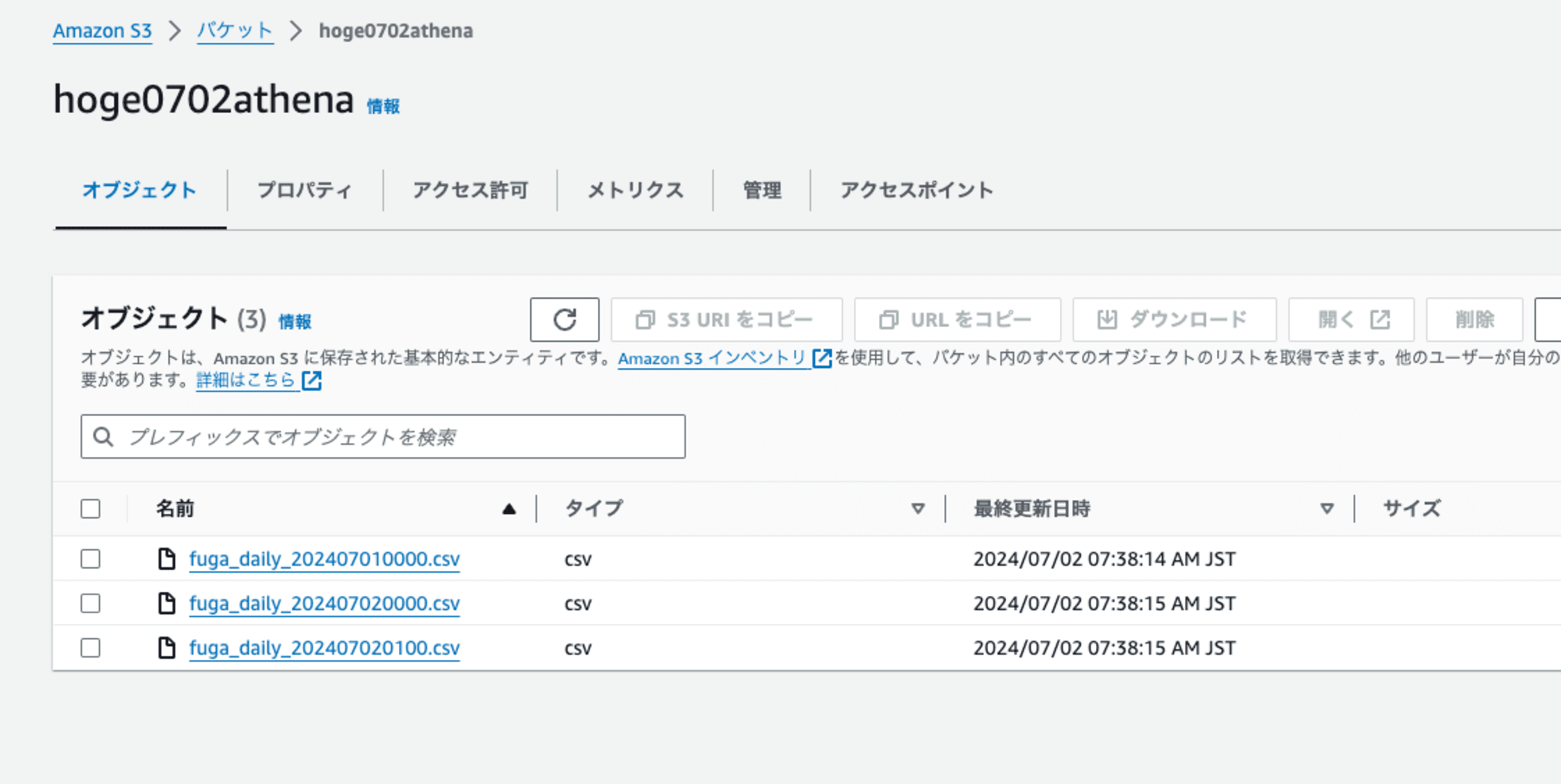
この時、7月2日0時のものは古いデータとして無視し、1時のデータだけ扱いたいというケースがありました。
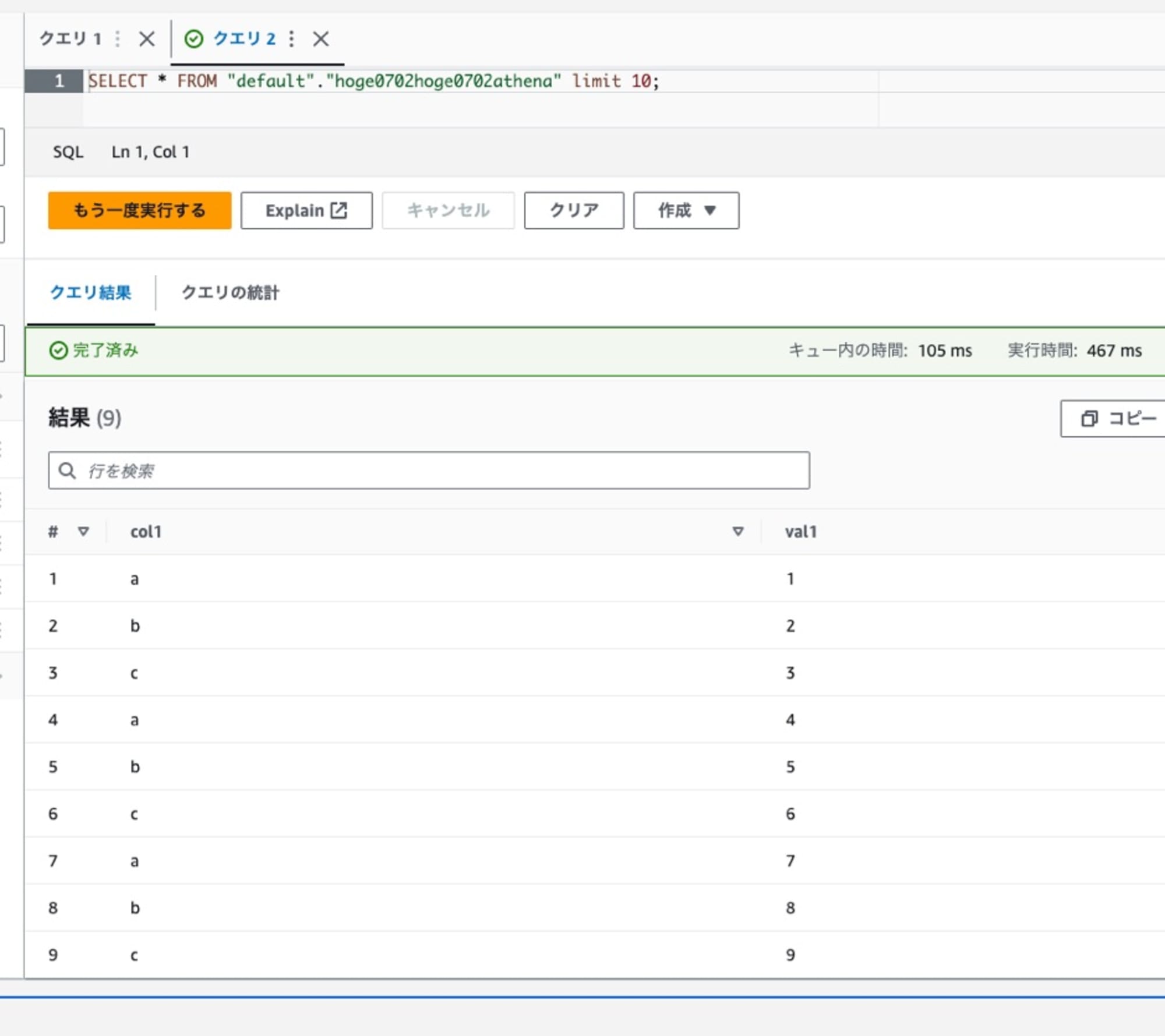
データ内容は構造は同じですが次のような感じになっています。

普通に取得すると重複したレコードも取得されるので、9件取得されます。
最新の CSV がアップロードされたタイミングで S3 トリガー Lambda などで同日日付の古いファイルを判定して削除する方法でも良いかなと思ったのですが、Lambda コードの実装が必要になるため、まずは Athena だけでどうにか出来ないかと試みることにしました。
パスを取得する
まず、データにタイムスタンプ情報が無かったり、日時パーティションの設定がなかったりする場合はファイル名からその情報を取得する必要があります。
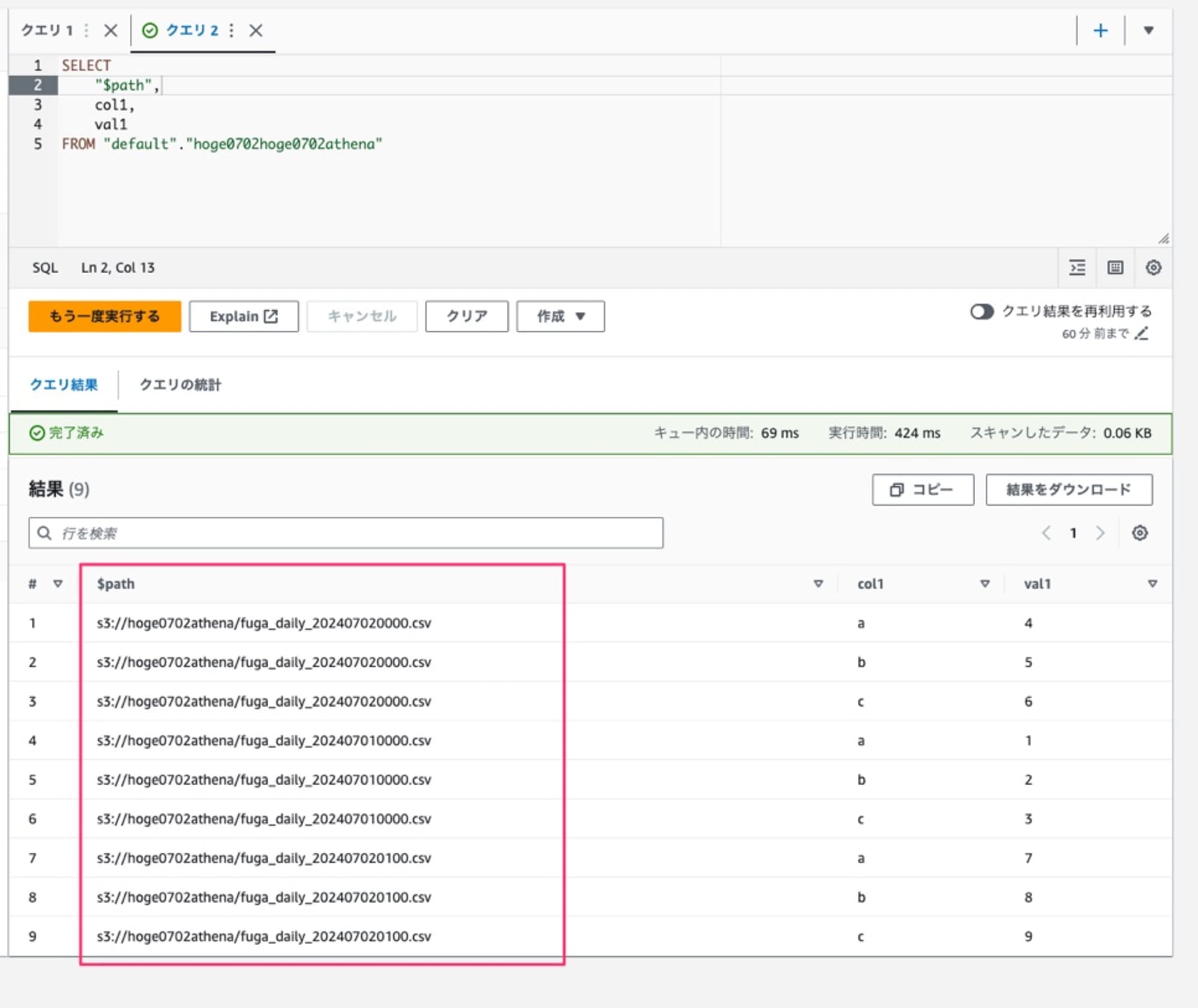
どうやら$pathを使うとファイルパスの取得が出来るのでこれを使ってみたいと思います。
ファイルパスをフィールドとして取得する様子。
同一日時の最新時間のレコードのみを抽出する
ここからはいくつか手法がありそうですが、今回は各日時の最新時間のキーを取得したものを内部結合することで古いレコードを除外するというのをやってみました。
今回は日付と時間のフィールドは固定で文字数で切り出したものをサブクエリで結合しているだけです。
DISTINCT も考えましたが、重複除外しつつ特定レコードの値を取得するのが難しそうだったのでこの方式にしました。
With
hoge AS (
SELECT
date_parse("$path", 's3://hoge0702athena/fuga_daily_%Y%m%d%H%i.csv') as hogetimestamp,
substring("$path", 32, 8) as hogedate,
substring("$path", 40, 4) as hogetime,
col1,
val1
FROM "default"."hoge0702hoge0702athena"
)
SELECT
hogetimestamp,
col1,
val1
FROM hoge INNER JOIN (
SELECT
hogedate,
MAX(hogetime) as hogetime
FROM hoge GROUP BY hogedate
) as hogemax
ON hoge.hogedate = hogemax.hogedate
AND hoge.hogetime = hogemax.hogetime
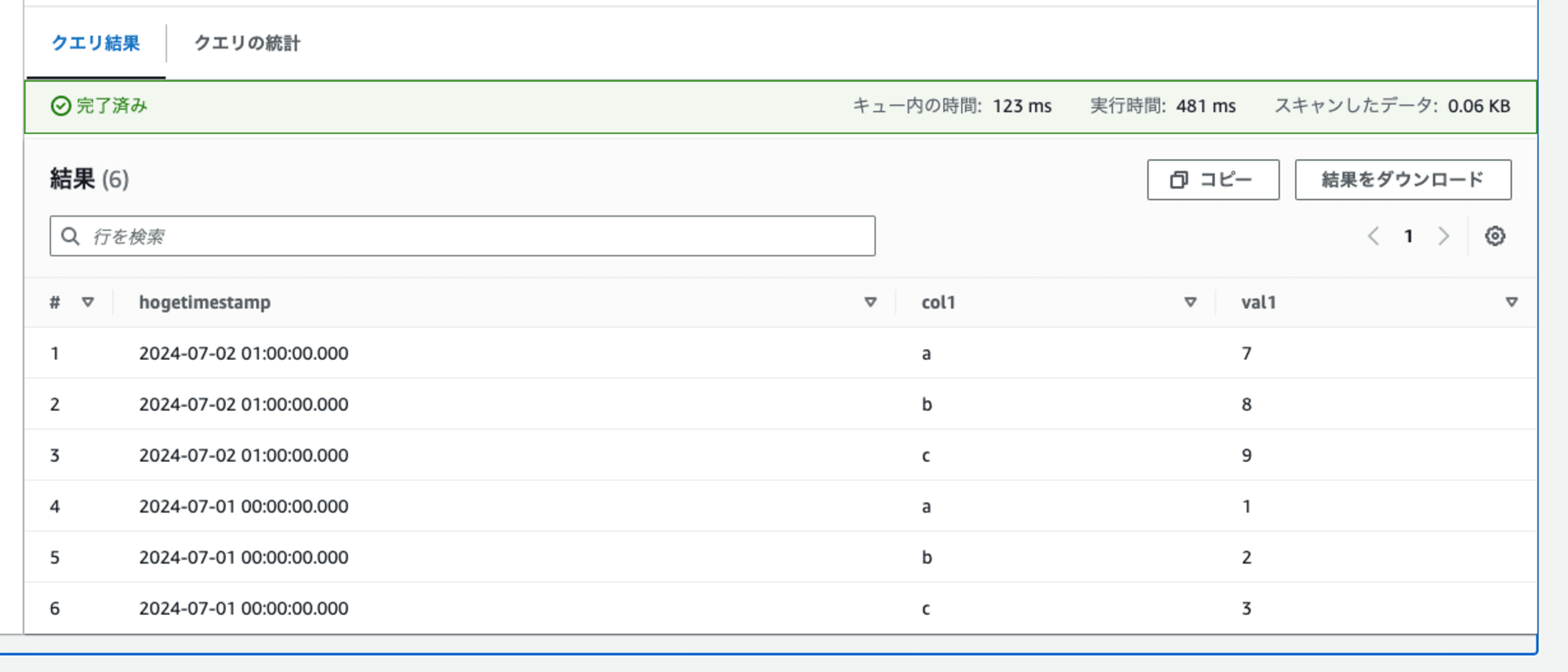
良いですね。
各日の最新時間の値が取得出来ています。
さいごに
本日は Athena で S3 バケット内のファイル名に含まれるタイムスタンプから同一日付の新しいレコードのみを抽出してみました。
力技感が少しありますが、Athena だけでやるとこんな感じではないでしょうか。
もうちょっと良い方法あるぜという方はぜひ SNS などで私までコメントをください。






