
Amazon Athenaのパーティション射影でNOWを使用したyear/month/day パーティショニングの実装方法

はじめに
データ事業本部ビッグデータチームのkasamaです。
Athenaのパーティション射影(Partition Projection)では、日時パーティションを効率的に管理できます。今回はyear/month/dayで個別にパーティショニングする方法とNOWの使用方法について記載します。
前提
パーティション射影は、Athenaがパーティションを自動的に推測する機能です。これにより、パーティションを持つテーブルのクエリパフォーマンスが向上します。
事前準備
パーティション射影検証用に年が異なるcsvファイルをそれぞれ準備します。
2023_data.csv
"id","name"
"001","John Smith"
2024_data.csv
"id","name"
"002","Jane Doe"
2025_data.csv
"id","name"
"003","Mike Johnson"
今回はparquetファイルで検証するため、csvファイルをparquetファイルに変換し、S3に格納します。
convert_to_parquet.py
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import glob
import os
# 出力ディレクトリを作成
output_dir = "parquet"
os.makedirs(output_dir, exist_ok=True)
# 入力ディレクトリの全CSVファイルを処理
for csv_file in glob.glob("csv/*.csv"):
# すべてのカラムを文字列型として読み込む
df = pd.read_csv(csv_file, dtype=str)
table = pa.Table.from_pandas(df)
# 出力ファイル名を生成
output_file = os.path.join(
output_dir, os.path.basename(csv_file).replace(".csv", ".parquet")
)
pq.write_table(table, output_file)
print(f"Converted {csv_file} to {output_file}")
S3
3.12.1) @ 45_athea_partition % aws s3 ls s3://<your-s3-bucket>/test_table/ --recursive --profile <your-role>
2024-12-27 16:46:21 0 test_table/
2024-12-27 16:46:36 0 test_table/2023/
2024-12-27 16:46:53 0 test_table/2023/01/
2024-12-27 16:47:00 0 test_table/2023/01/01/
2024-12-27 17:13:43 1984 test_table/2023/01/01/2023_data.parquet
2024-12-27 16:46:43 0 test_table/2024/
2024-12-27 16:47:07 0 test_table/2024/01/
2024-12-27 16:47:11 0 test_table/2024/01/01/
2024-12-27 17:13:54 1974 test_table/2024/01/01/2024_data.parquet
2024-12-27 16:46:48 0 test_table/2025/
2024-12-27 16:47:17 0 test_table/2025/01/
2024-12-27 16:47:25 0 test_table/2025/01/01/
2024-12-27 17:14:03 1994 test_table/2025/01/01/2025_data.parquet
AthenaでDatabaseを作成します。
cm_kasama_db.sql
CREATE DATABASE IF NOT EXISTS cm_kasama_db;
これで事前準備は完了です!
実装
cm_kasama_db.test_table.sql
CREATE EXTERNAL TABLE cm_kasama_db.test_table(
id STRING,
name STRING
)
PARTITIONED BY (
year string,
month string,
day string
)
STORED AS PARQUET
LOCATION 's3://<your-s3-bucket>/test_table/'
TBLPROPERTIES (
'projection.enabled' = 'true',
'projection.year.type' = 'date',
'projection.year.format' = 'yyyy',
'projection.year.range' = '2024,NOW',
'projection.month.type' = 'integer',
'projection.month.range' = '1,12',
'projection.month.digits' = '2',
'projection.day.type' = 'integer',
'projection.day.range' = '1,31',
'projection.day.digits' = '2',
'storage.location.template' = 's3://<your-s3-bucket>/test_table/${year}/${month}/${day}'
);
ポイントとなる設定項目
- 年(year)の設定
- type:
NOWを使用するためにdateとして日付型を指定 - format:
yyyyで4桁年を指定 - range:
2024,NOWで2024年から現在までの範囲を指定
- 月(month)の設定
- type:
integerとして整数型を指定 - range:
1,12で1月から12月までの範囲を指定 - digits:
2で2桁表示(01-12)を指定
- 日(day)の設定
- type:
integerとして整数型を指定 - range:
1,31で1日から31日までの範囲を指定 - digits:
2で2桁表示(01-31)を指定
yearのrangeで使用されているNOWは、クエリ実行時の現在の年を示します。これにより、テーブル定義を変更することなく、将来のデータも自動的に対象となります。
例えば、2024年に作成したテーブルが2025年になっても、NOWは自動的に2025を含むようになります。ちなみにこのNOWはUTC時刻であることを注意しましょう。仮にS3のPathのyear/month/dayがJSTの場合、NOW+9HOURSという指定が必要です。
実行結果
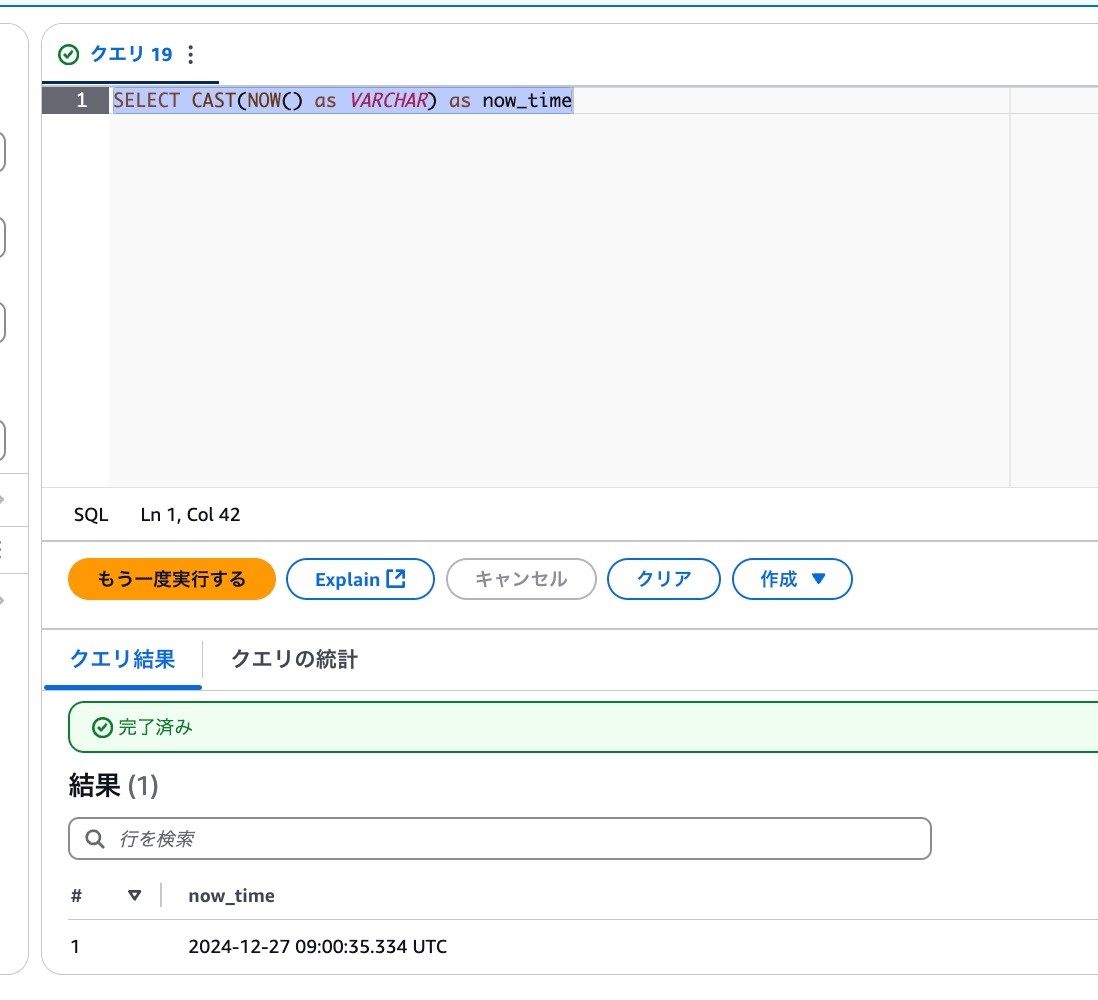
以下のクエリからもNOWの値がUTC時刻の2024年であることを確認しています。
SELECT CAST(NOW() as VARCHAR) as now_time
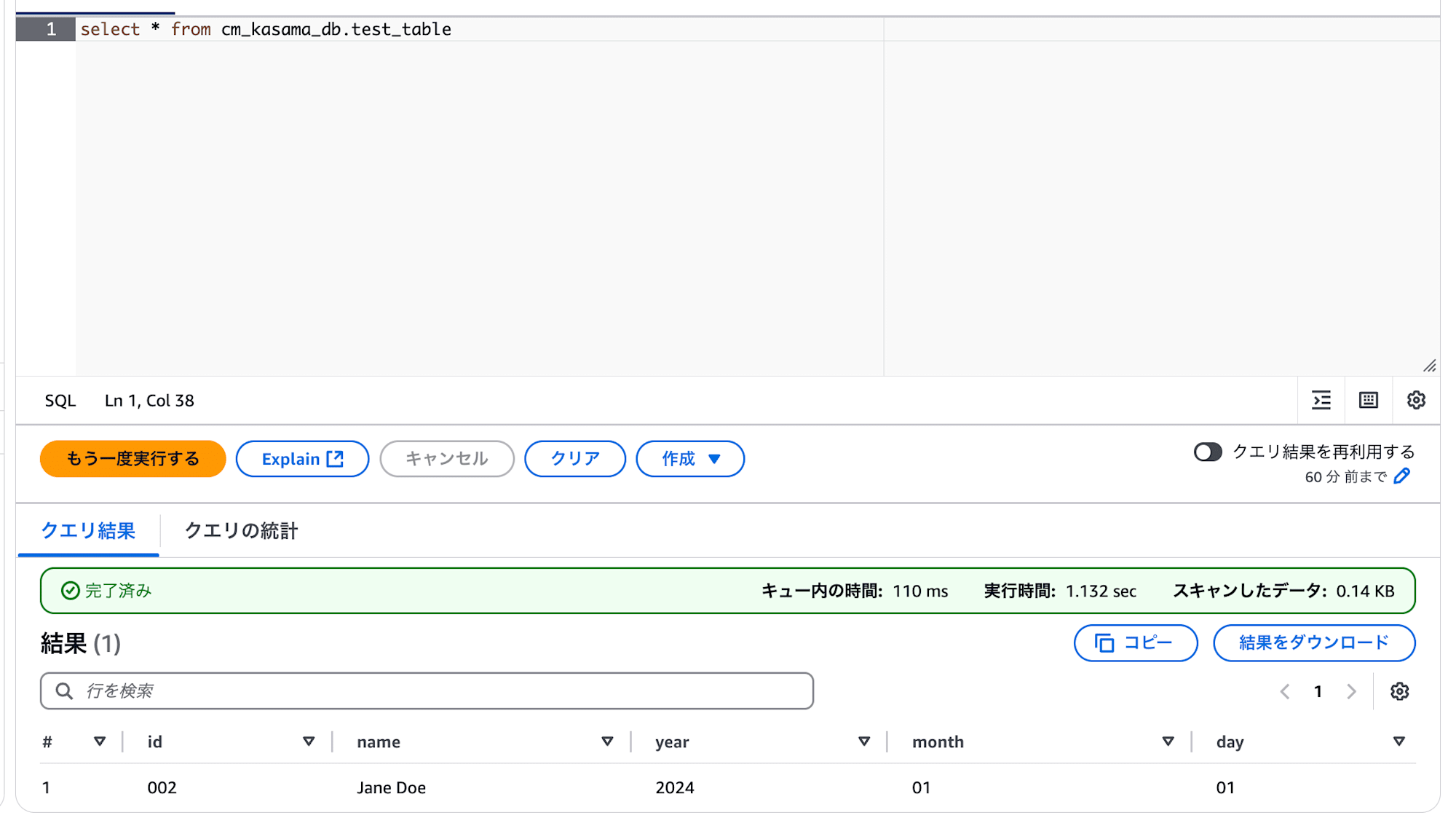
tableのselectでもrangeで2024年のみ出力されました。
最後に
最初は2099年を設定しとけば良いだろうとか、yearにNOWを使えないだろうと考えていましたが、意外と使えて便利でした。






