![[Amazon Athena] Partition ProjectionのInjectionを使うと何が嬉しいのか確認してみた](https://devio2023-media.developers.io/wp-content/uploads/2019/04/amazon-athena.png)
[Amazon Athena] Partition ProjectionのInjectionを使うと何が嬉しいのか確認してみた

こんにちは、CX事業本部 IoT事業部の若槻です。
Amazon AthenaではPartition Projectionを使うことにより、クエリ時のパーティション計算をメモリ上で実施することができるようになります。
このPartition Projectionでは"動的IDパーティショニング"の一手法としてInjectionによる方法が用意されています。
今回は、このPartition ProjectionのInjectionを使うと何が嬉しいのか確認してみました。
何が嬉しいのか
例えばデバイスの生成したデータを管理する際に、デバイスID(UUID)によるパーティショニングを行いたい場合があると思います。次のようにデータの格納パスにデバイスIDを使用する場合などです。IDをデータに書き込まずパスで表現することにより、コンソールなどからのデータの検索性を上げたり、データ量を削減したりできるメリットがあります。
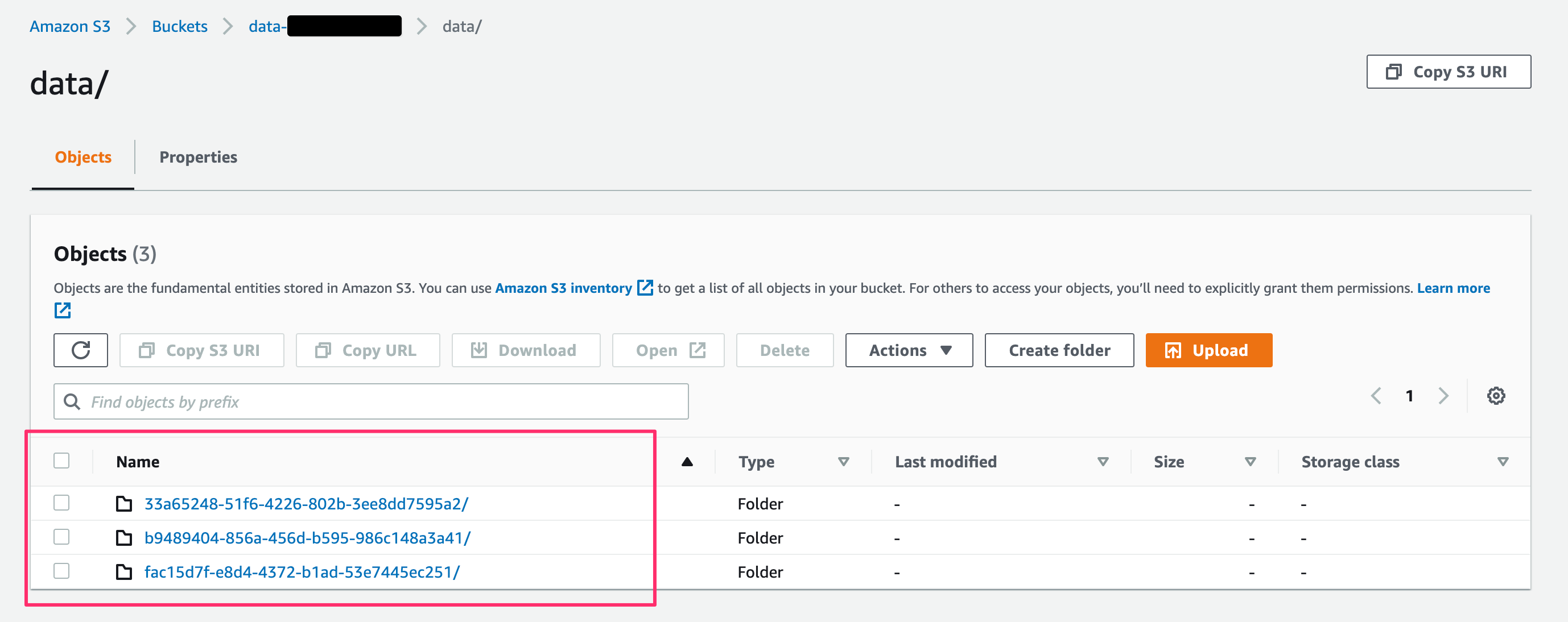
さて、このデータのAthenaからのクエリでPartition Projectionを使いたい場合、使用するパーティションの型としてまず考えられるのはstringの列挙に対応したEnum型ですが、今回のデバイスIDに使用するUUIDはランダムで値の数も多くなるためEnum型でカバーするのは非現実的です。
そんな時に役に立つのがPartition ProjectionのInjectionです。Injection型のパーティションを使うことにより、クエリ時にパーティションキーの値をWHERE句で動的に指定することができるようになります。これを動的IDパーティショニング(Dynamic ID partitioning)とも呼びます。
試してみる
Partition ProjectionのInjectionを試してみます。
環境構築
AWS CDK v2(TypeScript)で次のCDKスタックを作成します。
import { Construct } from 'constructs';
import {
aws_s3,
aws_athena,
Stack,
StackProps,
RemovalPolicy,
aws_glue,
} from 'aws-cdk-lib';
import * as glue_alpha from '@aws-cdk/aws-glue-alpha';
export class ProcessStack extends Stack {
constructor(scope: Construct, id: string, props: StackProps) {
super(scope, id, props);
// データ格納バケット
const dataBucket = new aws_s3.Bucket(this, 'dataBucket', {
bucketName: `data-${this.account}-${this.region}`,
removalPolicy: RemovalPolicy.DESTROY,
});
// Athenaクエリ結果格納バケット
const athenaQueryResultBucket = new aws_s3.Bucket(
this,
'athenaQueryResultBucket',
{
bucketName: `athena-query-result-${this.account}`,
removalPolicy: RemovalPolicy.DESTROY,
}
);
// データカタログ
const dataCatalog = new glue_alpha.Database(this, 'dataCatalog', {
databaseName: 'data_catalog',
});
// データカタログテーブル
const dataGlueTable = new glue_alpha.Table(this, 'sourceDataGlueTable', {
tableName: 'source_data_glue_table',
database: dataCatalog,
bucket: dataBucket,
s3Prefix: 'data/',
partitionKeys: [
{
name: 'device_id',
type: glue_alpha.Schema.STRING,
},
],
dataFormat: glue_alpha.DataFormat.JSON,
columns: [
{
name: 'userId',
type: glue_alpha.Schema.STRING,
},
{
name: 'count',
type: glue_alpha.Schema.FLOAT,
},
],
});
// データカタログテーブルへのPartition Projectionの設定
const cfnTable = dataGlueTable.node.defaultChild as aws_glue.CfnTable;
cfnTable.addPropertyOverride('TableInput.Parameters', {
'projection.enabled': true,
'projection.device_id.type': 'injected',
'storage.location.template':
`s3://${dataBucket.bucketName}/data/` + '${device_id}',
});
// Athenaワークグループ
new aws_athena.CfnWorkGroup(this, 'athenaWorkGroup', {
name: 'athenaWorkGroup',
workGroupConfiguration: {
resultConfiguration: {
outputLocation: `s3://${athenaQueryResultBucket.bucketName}/result-data`,
},
},
recursiveDeleteOption: true,
});
}
}
- Partition Projectionの設定で、
projection.<partition key>.typeでInjection型を指定し、storage.location.templateでプレフィクス内でのパーティションキーの位置をプレースホルダーで指定します。
上記をCDK Deployしてスタックをデプロイします。
JSON Lines形式のデータを作成します。
$ cat data1
{"userId":"u001","count":3}
{"userId":"u001","count":1}
{"userId":"u002","count":5}
{"userId":"u002","count":8}
{"userId":"u003","count":2}
$ cat data2
{"userId":"u001","count":14}
{"userId":"u002","count":10}
{"userId":"u003","count":12}
$ cat data3
{"userId":"u001","count":4}
{"userId":"u002","count":4}
{"userId":"u003","count":0}
各ファイルをそれぞれS3 Bucketのdevice_idのパーティションのパスにアップロードします。
aws s3 cp data1 s3://${BUCKET_NAME}/data/33a65248-51f6-4226-802b-3ee8dd7595a2/data1
aws s3 cp data2 s3://${BUCKET_NAME}/data/b9489404-856a-456d-b595-986c148a3a41/data2
aws s3 cp data3 s3://${BUCKET_NAME}/data/fac15d7f-e8d4-4372-b1ad-53e7445ec251/data3
動作確認
Athenaでクエリを行なってみます。
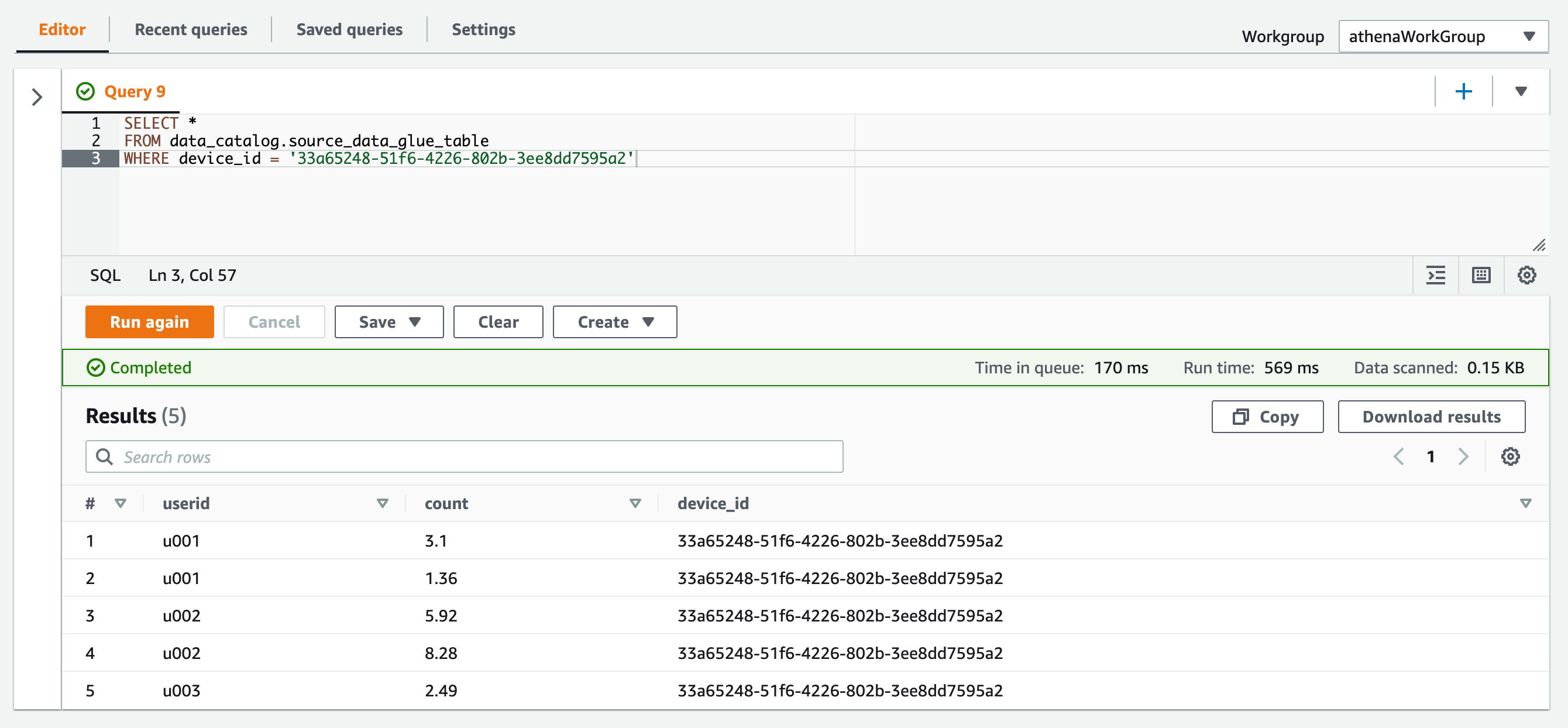
WHERE句でdevice_idを使用すると、パーティションキーによるフィルターがされたデータを取得できました。
SELECT * FROM data_catalog.source_data_glue_table WHERE device_id = '33a65248-51f6-4226-802b-3ee8dd7595a2'
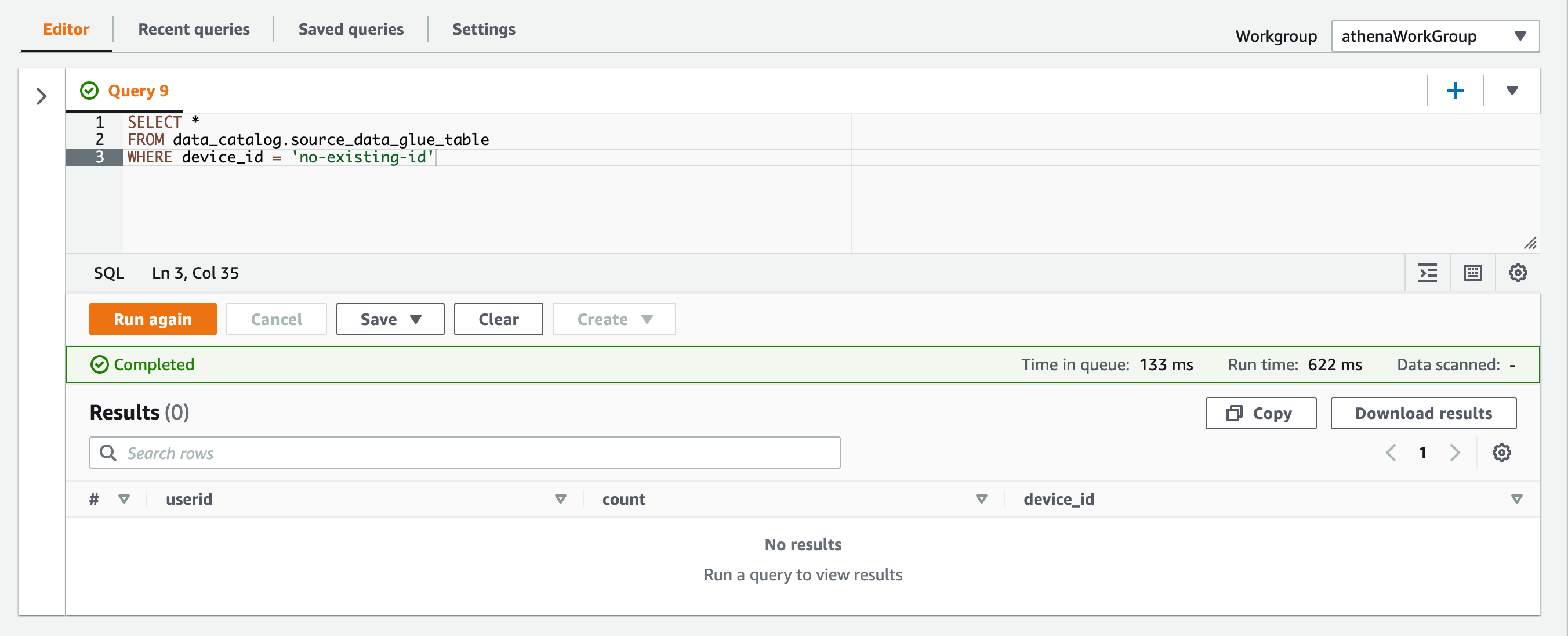
存在しないdevice_idでクエリするとクエリは成功しますが、取得結果は0件となります。
SELECT * FROM data_catalog.source_data_glue_table WHERE device_id = 'no-existing-id'
WHERE句でdevice_idを指定しないとクエリ実行はエラーとなります。Injectionのパーティションキーは必ず指定する必要があるようです。
SELECT * FROM data_catalog.source_data_glue_table
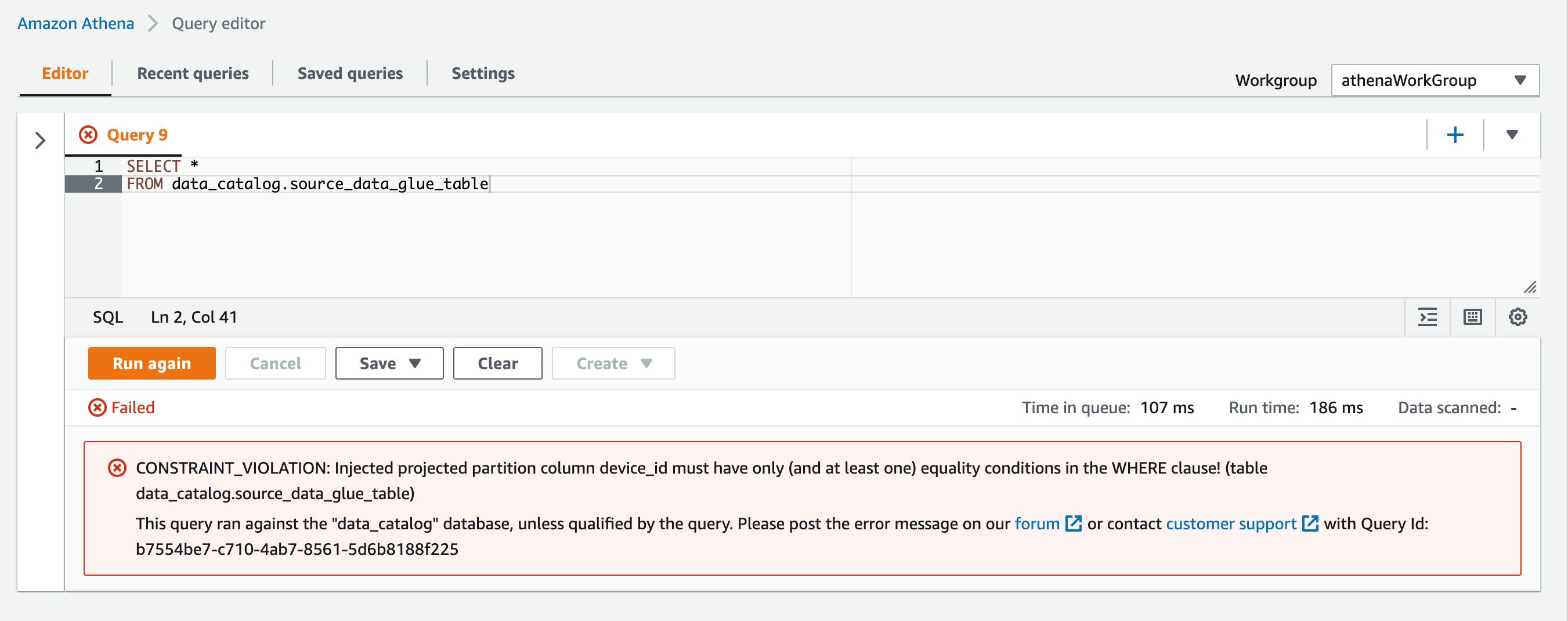
CONSTRAINT_VIOLATION: Injected projected partition column device_id must have only (and at least one) equality conditions in the WHERE clause! (table data_catalog.source_data_glue_table)
おわりに
Amazon AthenaでPartition ProjectionのInjectionを使うと何が嬉しいのか確認してみました。
同じ動的なパーティショニングをする方法としてGlue Crawlerを使う方法もありますが、余計なリソースは増やさずにPartition Projectionでどうしても何とかしたい!という方にオススメの方法となります。
参考
以上







