![[Amazon Athena] ALTER TABLE ADD PARTITIONコマンドでnon-Hiveなパーティションを追加してみた](https://devio2023-media.developers.io/wp-content/uploads/2019/04/amazon-athena.png)
[Amazon Athena] ALTER TABLE ADD PARTITIONコマンドでnon-Hiveなパーティションを追加してみた

こんにちは、CX事業本部 IoT事業部の若槻です。
今回は、Amazon AthenaでALTER TABLE ADD PARTITIONコマンドを使用してnon-Hiveなパーティションを追加してみました。
パーティションのStyleにはHiveとnon-Hiveがある
Amazon Athenaのデータパーティショニングでは、Hiveおよびnon-Hive(非Hive)の2つのStyleが使用できます。
Athena can use Apache Hive style partitions, whose data paths contain key value pairs connected by equal signs (for example,
country=us/... oryear=2021/month=01/day=26/...). Thus, the paths include both the names of the partition keys and the values that each path represents. To load new Hive partitions into a partitioned table, you can use the MSCK REPAIR TABLE command, which works only with Hive-style partitions.Athena can also use non-Hive style partitioning schemes. For example, CloudTrail logs and Kinesis Data Firehose delivery streams use separate path components for date parts such as
data/2021/01/26/us/6fc7845e.json. For such non-Hive style partitions, you use ALTER TABLE ADD PARTITION to add the partitions manually.
Hive StyleはKey-Valueが=で連結されたyear=2021/month=01/day=26/のような形式を取り、パーティションの作成はMSCK REPAIR TABLEコマンドで行います。
一方で、non-Hive Styleは2021/01/26/のような形式を取り、パーティションの作成はALTER TABLE ADD PARTITIONコマンドで行います。
AWSだとAmazon Kinesis Data Firehoseのデータ出力がこのnon-Hive Styleを取ります。
そこで今回は、S3 Bucketのnon-Hive Styleなパスに対して、ALTER TABLE ADD PARTITIONコマンドを使用してパーティションを追加してみました。
やってみた
環境準備
AWS CDK v2(TypeScript)で次のようなCDKスタックを作成して、必要な環境を準備します。
import { Construct } from 'constructs';
import {
aws_s3,
aws_athena,
RemovalPolicy,
Stack,
StackProps,
} from 'aws-cdk-lib';
import * as glue from '@aws-cdk/aws-glue-alpha';
export class ProcessStack extends Stack {
constructor(scope: Construct, id: string, props: StackProps) {
super(scope, id, props);
// ソースデータ格納バケット
const sourceDataBucket = new aws_s3.Bucket(this, 'sourceDataBucket', {
bucketName: `data-${this.account}`,
removalPolicy: RemovalPolicy.DESTROY,
});
// Athenaクエリ結果格納バケット
const athenaQueryResultBucket = new aws_s3.Bucket(
this,
'athenaQueryResultBucket',
{
bucketName: `athena-query-result-${this.account}`,
removalPolicy: RemovalPolicy.DESTROY,
},
);
// データカタログ
const dataCatalog = new glue.Database(this, 'dataCatalog', {
databaseName: 'data_catalog',
});
// データカタログテーブル
new glue.Table(this, 'sourceDataGlueTable', {
tableName: 'source_data_glue_table',
database: dataCatalog,
bucket: sourceDataBucket,
s3Prefix: 'data/',
partitionKeys: [
{
name: 'dt',
type: glue.Schema.STRING,
},
],
dataFormat: glue.DataFormat.JSON,
columns: [
{
name: 'userId',
type: glue.Schema.STRING,
},
{
name: 'count',
type: glue.Schema.INTEGER,
},
],
});
// Athenaワークグループ
new aws_athena.CfnWorkGroup(this, 'athenaWorkGroup', {
name: 'athenaWorkGroup',
workGroupConfiguration: {
resultConfiguration: {
outputLocation: `s3://${athenaQueryResultBucket.bucketName}/result-data`,
},
},
});
}
}
- データソースのデータカタログとして、パーティションキーが
dt、カラムがuserIdおよびcountのGlueテーブルを作成しています。 - AWS CDK v2(aws-cdk-lib)にはAWS GlueのL2 ConstructのClassがまだ無いため、alphaモジュール(@aws-cdk/aws-glue-alpha)を導入しています。
@aws-cdk/aws-glue-alpha含めCDKモジュールはバージョンをすべて統一するようにします。(しなければインストール時にエラーが発生します)
$ npm ls aws-cdk-lib aws-cdk @aws-cdk/aws-glue-alpha --depth=0 [email protected] /path/to/project ├── @aws-cdk/[email protected] ├── [email protected] └── [email protected]
上記をCDK Deployしてスタックをデプロイします。
JSON Lines形式のデータを作成します。
$ cat data1
{"userId":"u001","count":3}
{"userId":"u001","count":1}
{"userId":"u002","count":5}
{"userId":"u002","count":8}
{"userId":"u003","count":2}
$ cat data2
{"userId":"u001","count":14}
{"userId":"u002","count":10}
{"userId":"u003","count":12}
$ cat data3
{"userId":"u001","count":4}
{"userId":"u002","count":4}
{"userId":"u003","count":0}
各ファイルをそれぞれS3 Bucketの/2022/06/26、/2022/06/27および/2022/06/28のパスにアップロードします。
aws s3 cp data1 s3://${BUCKET_NAME}/data/2022/06/26/data1
aws s3 cp data2 s3://${BUCKET_NAME}/data/2022/06/27/data2
aws s3 cp data3 s3://${BUCKET_NAME}/data/2022/06/28/data3
パーティションを作成してみる
この時点でGlueテーブルにパーティションは作成されていません。
$ aws glue get-partitions \
--database-name ${GLUE_DATABASE_NAME} \
--table-name ${DATA_SOURCE_GLUE_TABLE_NAME}
{
"Partitions": []
}
なのでSELECTクエリを実行しても結果は取得できません。
SELECT * FROM "data_catalog"."source_data_glue_table" WHERE dt = '2022-06-28'

下記のALTER TABLE ADD PARTITIONクエリを実行します。S3 Bucketのdata/2022/06/28/のパスに対してdt = '2022-06-28'のパーティションを作成するクエリです。
ALTER TABLE data_catalog.source_data_glue_table ADD PARTITION (dt = '2022-06-28') LOCATION 's3://data-XXXXXXXXXXXX/data/2022/06/28/'
上記クエリを実行します。

するとLocations3://data-XXXXXXXXXXXX/data/2022/06/28/に対するパーティション2022-06-28が作成されたため、CLIでも取得できるようになりました。
$ aws glue get-partitions \
--database-name ${GLUE_DATABASE_NAME} \
--table-name ${DATA_SOURCE_GLUE_TABLE_NAME}
{
"Partitions": [
{
"Values": [
"2022-06-28"
],
"DatabaseName": "data_catalog",
"TableName": "source_data_glue_table",
"CreationTime": "2022-06-28T21:11:02+09:00",
"StorageDescriptor": {
"Columns": [
{
"Name": "userid",
"Type": "string"
},
{
"Name": "count",
"Type": "int"
}
],
"Location": "s3://data-XXXXXXXXXXXX/data/2022/06/28/",
"InputFormat": "org.apache.hadoop.mapred.TextInputFormat",
"OutputFormat": "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat",
"Compressed": false,
"NumberOfBuckets": 0,
"SerdeInfo": {
"SerializationLibrary": "org.openx.data.jsonserde.JsonSerDe"
},
"SortColumns": [],
"StoredAsSubDirectories": false
},
"CatalogId": "XXXXXXXXXXXX"
}
]
}
またSELECTクエリで2022-06-28パーティションからデータを取得できるようになりました!
SELECT * FROM "data_catalog"."source_data_glue_table" WHERE dt = '2022-06-28'
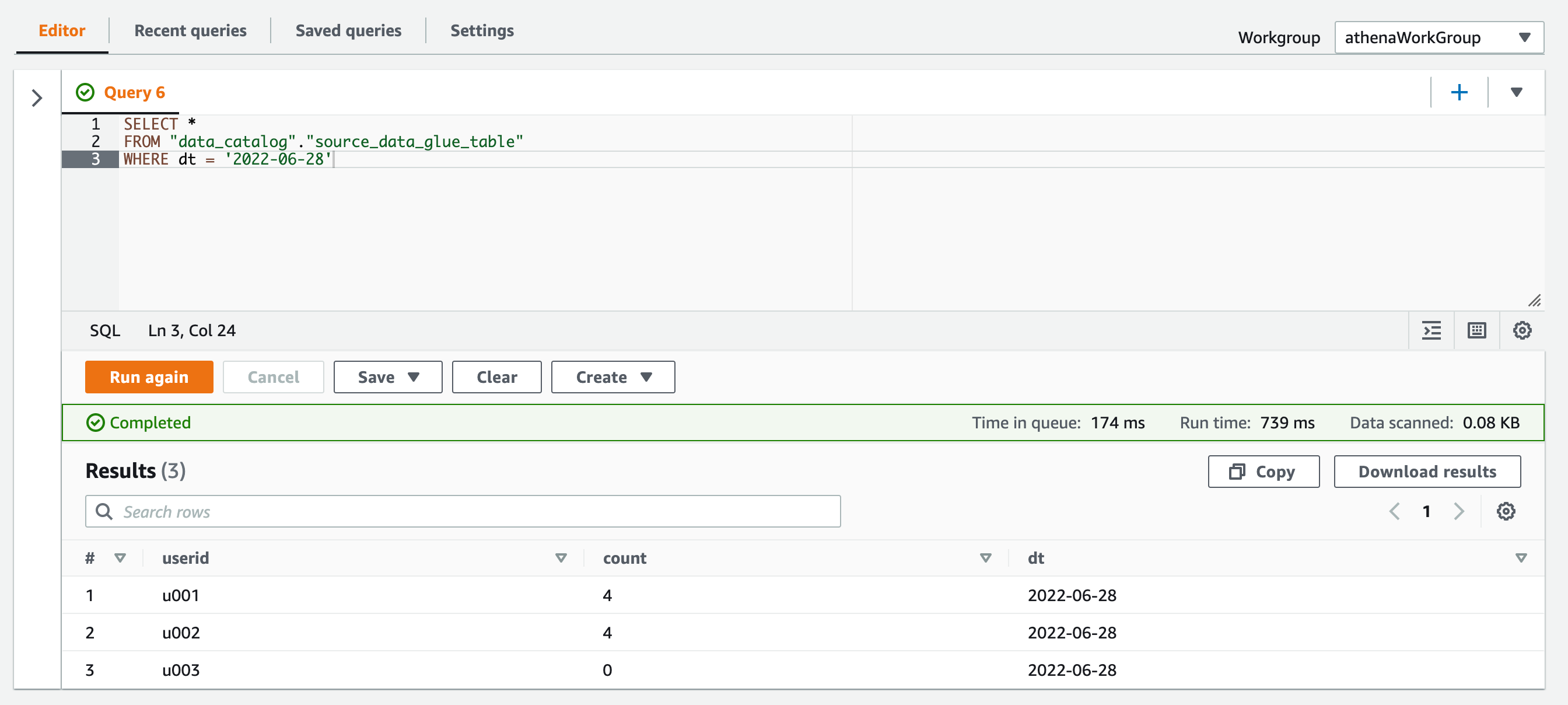
追加で2022-06-27および2022-06-26のパーティションも作成します。
ALTER TABLE data_catalog.source_data_glue_table ADD PARTITION (dt = '2022-06-27') LOCATION 's3://data-XXXXXXXXXXXX/data/2022/06/27/' PARTITION (dt = '2022-06-26') LOCATION 's3://data-XXXXXXXXXXXX/data/2022/06/26/'
すると他のパーティションへのクエリもできるようになりました!
SELECT * FROM "data_catalog"."source_data_glue_table" WHERE dt <= '2022-06-28' AND count > 3

おわりに
Amazon AthenaでALTER TABLE ADD PARTITIONコマンドでnon-Hiveなパーティション追加をしてみました。
Athenaではパーティションを作成する方法はいくつかあり迷うことがあったので、ALTER TABLE ADD PARTITIONを試すと同時に両者の整理ができて良かったです。
参考
以上







